Conversation with Hindemburg Melão Jr. on Gratitude and Clarifications, and Life, Views, and Work: Founder, Sigma Society (1)
Author(s): Scott Douglas Jacobsen
Publication (Outlet/Website): In-Sight: Independent Interview-Based Journal
Publication Date (yyyy/mm/dd): 2022/06/08
Abstract
Hindemburg Melão Jr. (January 15, 1972) was born in São Paulo, Brazil. He founded the most, or one of the most, selective high-I.Q. societies, the Sigma Society and is the Creator of the Sigma Test Extended. He is a philosopher, chess analyst, and an astrophotographer. He published hundreds of articles on chess, finance, philosophy, science, and more. He discusses: an extensive preamble of gratitude and clarifications to the interview; growing up; extended self; family background; youth with friends; education; purpose of intelligence tests; high intelligence; extreme reactions to geniuses; greatest geniuses; genius and a profoundly gifted person; necessities for genius or the definition of genius; work experiences and jobs held; job path; myths of the gifted; God; science; tests taken and scores earned; range of the scores; ethical philosophy; political philosophy; metaphysics; worldview; meaning in life; source of meaning; afterlife; life; and love.
Keywords: Albert Frank, AlphaZero, American Biographical Institute, artificial intelligence, Bahá’í Faith, Baran Yonter, Catholic, Cattell, Chris Harding, Christopher Michael Langan, Deus VULT, Domagoj Kutle, Galois, Galton, Garth Zietsman, Gauss, George Zweig, Grady Towers, Guinness Book of World Records, Guilherme Marques dos Santos Silva, Hindemburg Melão Jr., hrIQt, intelligence, Intertel, Isaac Newton, ISIS Test, ISPE, Jimmy Rogers, Kardecism, Keith Raniere, Kevin Langdon, Kim Ung-Yong, Langdon Adult Intelligence Test, life, Marilyn vos Savant, Martial Arts, Mega Society, Mega Test, Murray Gell-Mann, MuZero, native Indian, Neumann, Nobel Prize, Pars Society, Pascal, Paul Cooijmans, Paulo Reginaldo Pascholati, Petri Widsten, pIQ, Prometheus Society, Richard Lynn, Rick Rosner, rIQ, Ronald Hoeflin, science, Sigma Society, Sigma Test Extended, Stanford-Binet, Titan Test, TNS, views, work.
Conversation with Hindemburg Melão Jr. on Gratitude and Clarifications, and Life, Views, and Work: Founder, Sigma Society (1)
*Please see the footnotes, bibliography, and citation style listing after the interview.*
*English version at the top. Portuguese version at the bottom.*
First of all, I want to thank my girlfriend Tamara, for her patience in reading this text and helping me to cut long unnecessary snippets, Tor for the kindness of referring me for this interview and you for accepting this nomination and for your kind help with the translation review.
As much as possible, I tried to synthesize and simplify, but whenever it was necessary to decide between the shortest and the most correct answer, I chose the one that seemed to me the most correct. As a result, I ended up going longer than I would have liked and branching out some answers for details that apparently lose link to the question, but are actually indirectly connected by two, three, or more nodes, so that if those snippets were removed , there would be gaps that would compromise coherence.
Before presenting the answers, it is necessary to make some important clarifications: when the question is simple, it is enough to give a short answer so that the interpretation is univocal, but for complex questions, before answering it is necessary to conceptualize some of the terms used, to minimize the differences. between the message to be transmitted and the interpretation that will be made of it. A question like “Why, in chess, aren’t all doubled pawns weaknesses?” There is no way to answer in a way that gives a correct idea in just 1 or 2 paragraphs, not even if the answer was simplified and summarized. To try to provide a reasonably correct and complete idea, at least 20 pages are needed, with several examples commented. In this interview, some questions involve similar situations.
This kind of difficulty is inherent in any question involving IQ, because the concept currently disseminated has some flaws that need to be properly revised, and some of these revisions are not trivial, requiring a considerable amount of preliminary clarification to ensure that the interpretation of the answer is sufficiently accurate and reliable.
Outside of high IQ societies, it is common for people to confuse scales with different standard deviations. James Woods’ SAT score 1579 is often converted to 180, while Bill Gates’ 1590 score is converted to 154 (sometimes 160), and both appear on the same list as if Woods’ IQ was higher than Gates’, although it is the opposite. This kind of primary error has all but been eradicated in high-IQ societies, but there are still systematic errors being ostensibly repeated, some of which are large and serious. These errors cause a lot of confusion and make it difficult to correctly interpret fundamental questions. I am not referring to individual mistakes, made by a few people, but to “institutionalized” mistakes, universally accepted as if they were right and made by practically everyone.
In 2000, I solved a central problem in Psychometrics that had been dragging on since the 1950s, when Thurstone and Gardner realized the importance of standardizing cognitive tests in order to produce proportion-scale scores. Bob Seitz of Mega Society referred to this problem as “The Holy Grail of Psychometry”. After investigating this issue and resolving it, I published an article describing my method and showing how tests should be standardized. I also reviewed the Mega Test and Titan Test standards using this method. In 2003, I applied the same method to Sigma Test and published another, more detailed article, describing the entire standardization process step-by-step and explaining the reasons why this procedure is superior to the methods used. Among the chronic problems that are solved naturally with the application of this method, one of the most important is the correction in the calculations of percentiles and rarity levels. This is a systematic error that has been made since 1905. I will comment on this question in a little more detail in answering questions dealing with this topic.
There are two other mistakes that are made systematically, although the solutions to them are already known but are not applied, in part because these problems are not well understood: the problem of construct validity and the problem of the adequacy of the level of difficulty of the questions. to the level of intelligence that is intended to be measured. In a way, these problems are connected, because tests generally have good construct validity for a given range of skill levels, but not for the entire range in which the test is intended to measure, so the results turn out to be reasonably accurate and reliable for people whose scores are within the validity range, but begin to show serious distortions outside this range. A classic example to illustrate this problem is the Stanford-Binet V. The cognitive processes required to solve the BLS questions may be appropriate for correctly measuring intelligence in the range of 60 to 140, but begin to be less appropriate between 140 and 150 , so scores above 150 are already predominantly representing a latent trait that is not what was intended to be measured. This completely compromises the validity of this type of instrument for measurement above 150, and puts in doubt the extent to which scores between 140 and 150 are actually reflecting the intellectual level.
To better organize the information, before proceeding I will mention 3 important mistakes that are systematically made by professional psychometrists and in high IQ societies:
- The way in which tests are standardized, both clinical tests and high range IQ tests (hrIQts) – either through the use of Item Response Theory or Classical Test Theory – produces distortions in the scale, and the way in which the percentiles are calculated leads to results that are very far from reality. This distortion in the scale has already been pointed out since the 1950s, by Thurstone, and had already been noticed (although not described) by Binet himself in 1905. A good method for normalizing intelligence tests should produce scores on a scale of proportion, but IQ scores are presented on an ordinal scale ( https://www.questionpro.com/blog/nominal-ordinal-interval-ratio/ ). In addition, errors in the calculations of rarity levels present very large distortions in the highest scores, reaching more than 3 orders of magnitude. This is because the calculations start from the incorrect assumption that the distribution of IQs is Gaussian throughout. The morphology of the distribution is in fact very similar to that of a Gaussian in the range -2σ to +2σ, but it starts to break down outside this range. This fact cannot be overlooked when calculating percentiles. The way the calculations are currently done by psychometricians and in high-IQ communities, results are far from correct. Therefore, when talking about the 99.9999% percentile or IQ 176 (σ=16), the meanings are very different, although they are used as if they were the same thing. The correct rarity for IQ=176 is not 1 in 983,000, but 1 in 24,500. And this does not happen because the standard deviation is greater. The standard deviation is the same (16 in this example), but the right tail is denser than in a normal distribution, making higher scores more abundant than would be expected if the distribution were exactly Gaussian. This is a problem related to the morphology of the true distribution, which does not fit the theoretical model of normal distribution. In fact, it doesn’t fit any of the 100+ distributions tested well, including the more versatile ones like the 3-parameter Weibull distribution.
- Another problem is that the difficulty level of the most difficult questions of each test is not compatible with the nominal ceiling of the test. As a consequence, such a test proves to be inappropriate for the range of IQs it should measure. The test works properly within a certain range, in which it contains questions of compatible difficulty, but fails to function outside that range. This is much more serious in clinical trials, where the ceiling of difficulty rarely exceeds 135 to 140, but the nominal ceiling can reach more than 200 (Stanford-Binet V, for example). Above 140, clinical tests measure how fast you can solve elementary problems, which is not necessarily an appropriate metric for representing intelligence at the highest levels. In hrIQt cases, in the “difficulty” question, questions are usually appropriate up to about 170 or 180, but not much higher. Here it would be necessary to open a long parenthesis to discuss the meaning of these scores, because up to 130 or a little above, the theoretical rarity is almost equal to the true rarity, but for 140, 150 and above, the theoretical rarity becomes more and more distant. of true rarity. So when we talk about 180 of IQ (σ=16), it is not enough to inform the standard deviation. In addition, it is necessary to inform if we are talking about the score measured in a test or if it is a true percentile converted into IQ. If the distribution of IQs were exactly Gaussian across their spectrum, then an IQ of 180 (σ=16) should correspond to a rarity level of 1 in 3,500,000, but the true rarity of 180 scores is around 1 in 48,000. Later I mention a link in which I describe how to get to that 1 in 48,000 rarity level.
- Another problem is related to construct validity, that is, whether what the test is measuring is in fact what it is intended to measure. The best clinical tests (WAIS and SB) are very good at this criterion for the range of 70 to 130, because this topic has been widely debated among good psychometricians for decades and some good criteria have been established to assess (albeit subjectively) whether the items are measuring what they should be measuring (intelligence, in this case, or the g factor). However, outside this range of 70 to 130, the measured variable becomes increasingly different from what was intended to be measured. In hrIQts the range is a little longer, it reaches around 160, some tests reach 170 or even 180.
In addition to these 3 issues that are seen in virtually all clinical trials and all hrIQts, there are also some individual issues, which are more basic and only affect some specific tests, such as inflated norm, template errors, misstatements, etc. I will not deal with those, because they are already well known and easy to identify and correct.
It is important not to confuse construct validity with difficulty level adequacy. A very elementary issue, with a very short time frame to resolve, may have adequate difficulty to measure at the 1 in 10 million rarity level, because although it is inherently easy, as the time frame is reduced, it ends up being difficult to resolve within that time frame. In such cases, the difficulty may be appropriate for measuring something at very high levels of rarity, but this latent trait being measured is not what it should be measuring. Furthermore, the fact that a test has construct validity in a given interval does not imply that it will necessarily have validity at levels far above or far below that interval. This is one of the most common mistakes, because validating an intelligence test for 98% of the population does not guarantee that it will continue to correctly measure intelligence at the level of the highest 1% or 0.1% of scores. Validation needs to be careful at all intervals at which the test is intended to be able to measure correctly.
There are also some more subtle issues. The Raven Standard Progressive Matrices, for example, have been used by Mensa in several countries for decades, but are inadequate to correctly measure above 120, perhaps even above 115. The reason is that the test consists of 60 questions, but only 1 or 2 of these questions (the most difficult ones) are useful to discriminate at the level of 133, which is where Mensa intends to select. So it is as if only 2 of the 60 questions were used, and a sample with only 2 elements cannot be considered statistically valid. In fact, the cut-off at 133 is not exactly determined by 1 or 2 questions, but these 2 questions account for over 90% of the test’s discriminating power at this cut-off level.
For these reasons, if there is a sincere interest in IQ questions getting answers that are representative of reality, these three problems need to be fixed:
- Unfounded extrapolation of construct validity;
- Inadequacy of the difficulty of the items for the intellectual level that the test intends to measure;
- Adoption of incorrect hypotheses about the shape of the distribution of scores at the highest levels, based on the shape in the region close to the central tendency.
In addition to these, there are other points that need to be clarified. There is a widespread myth that clinically applied tests are “better” (more reliable, more accurate, more reliable) than hrIQts. In some cases, they really are. But not at all. For scores below 130, supervised tests are standardized based on larger, unselected samples. This constitutes a real advantage of clinical trials compared to hrIQts. Another advantage is that good psychometricians know a greater number of statistical techniques, so in the range from 70 to 130, the best supervised tests usually produce more reliable scores. However, above 130, and especially above 140, supervised tests present several problems, starting with the inadequate ceiling of difficulty. The most difficult WAIS questions, for example, are too easy for them to measure intelligence above 135. Another problem is that the construct validity of supervised tests is designed for the range of 70 to 130, not applying as well outside of that range.
I made a simulated example to show what the construct variable problem consists of:
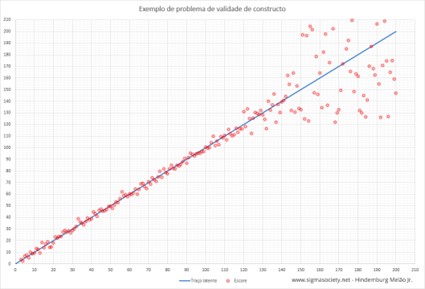
The blue line represents the latent trait [*] that we would like to measure (intelligence or g-factor or something). The red circles represent the scores obtained in the test converted into IQ. In the range between 0 and 120, the measured scores are very good representations of the latent trait, because the points are distributed closely close to the blue line, indicating a strong correlation between the variable we would like to measure and the variable we are actually measuring. [*https://dictionary.apa.org/latent-trait-theory, https://www.jstor.org/stable/1434009%5D
From 120 onwards, and especially from 130 onwards, the red circles begin to move further and further away from the blue line, indicating that the correlation between the variable we would like to measure and the variable that is actually being measured becomes more and more weak, so what we are measuring is becoming less and less representative of what we would like to measure. If you consider the entire range from 0 to 200, or even from 70 to 200, the correlation still looks strong, but that’s only because the range 70 to 120 is contained within the range 70 to 200, and as in the range 70 to 120 the correlation is strong, this improves the average correlation of the entire range from 70 to 200, but when considering exclusively the correlation between 130 and 200, it is noticed that the correlation is weak in this region and becomes weaker for the scores taller. Therefore, for scores above 130, what matters is not the global correlation, but the local correlation.
On IQ tests like the Stanford-Binet, for example, some very fast people with a true IQ of 150 can score 190 or more as a consequence of the problem described above. The opposite effect can also happen, and people with a true IQ of 190, if they are very slow, can score 150, 140 or even less. The size of errors can reach really high levels, both for more than correct and for less than correct, which is why construct validity [*] is an extremely important issue. [*https://en.wikipedia.org/wiki/Construct_validity]
A test that has good construct validity should behave like the one shown in the graph below, in which the red circles remain close to the blue line throughout the entire spectrum within which it is intended to measure:
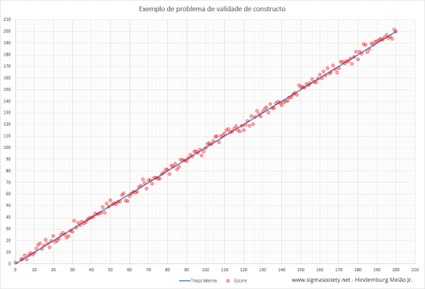
Of course, if the sample has a normal distribution, the data will be distributed approximately like an ellipse, not like a line that was represented above, but for didactic purposes this example needs to be like this to be visually clearer the increase in the amplitude of the dispersion of the measures in relative to the latent trait we would like to measure. It is also worth emphasizing that, in the real world, situations like the one in the graph above practically do not exist, because the alignment is too good. But it is desirable that the measured scores be able to provide good representations for the latent trait within as wide a range as possible.
In supervised IQ tests, used in clinics, disparities usually start to become serious from 130 and especially from 140, that is, what the test measures above 140 is no longer a good representation of Intelligence. In the cases of the best hrIQts, the scores remain reasonably good representations of the latent trait up to IQ 160 or so.
A test may have questions of an appropriate difficulty level, but what the questions are measuring may not be intelligence. Or it may happen that the measured variable is intelligence, but only within a specific range (as in the first graph). Some puzzles for children, for example, can be effective in correctly measuring the mental age range of 8 to 16 years, or 50 to 100 IQ on an adult scale, but if you use these same puzzles to try to measure the Adult IQs above 160 or 170, the result will be disastrous, because the ability to quickly solve these puzzles cannot be interpreted as a good representation of intelligence at this level. Therefore, the type of problem needs to be compatible with the intellectual level that is intended to be measured.
Generally, the smartest people are also quicker to solve basic questions, but the fact that they solve simple questions quickly does not offer a good guarantee that the person will also be able to solve more complex, deep questions that require creativity. In addition, the fact that a person is able to solve complex, deep questions that require creativity does not provide a good guarantee that he will be able to quickly solve basic questions. As the tests used in clinics exclusively include basic questions, the effect shown in Graph 1 ends up being very frequent.
This issue is discussed in more detail in the introductory text of Sigma Test Extended.
It is also necessary to standardize the meanings of some terms that I will use in the answers:
rIQ = rarity IQ, or IQ (σ=16 G), or rIQ (σ=16 G)
pIQ = Potential IQ, or IQ (σ=16 T), or pIQ (σ=16 T)
Detailed explanations can be found at https://www.sigmasociety.net/escalasqi . Here I will give a brief explanation: rIQ is the value that the IQ would have converted from the true rarity. This is not IQ measured on IQ tests or hrIQts. The measured IQ is the pIQ, whose distribution is non-Gaussian, the distribution has a dense tail, so the pIQ scores are more abundant than predicted based on the normality assumption of the distribution. This has nothing to do with the standard deviation being larger. The standard deviation is the same. The shape of the distribution is different, concentrating more cases in the right tail and less in the central region. In regions close to the central tendency, pIQ is almost equal to rIQ and remains so until about 130. From then on, pIQ becomes greater than rIQ. Some examples:
rIQ 100 is equivalent to pIQ 100.00
rIQ 130 is equivalent to pIQ 130.87
rIQ 150 is equivalent to pIQ 156.59
rIQ 180 is equivalent to pIQ 204.93
(A complete table is available on the Sigma Test Extended page)
The difference between pIQ and rIQ increases as rIQ increases, because the proportion at which the actual tail density becomes greater than the theoretical density increases as the IQ moves away from the mean.
When comparing estimated IQs based on rarity with IQs measured in tests, it is critical to put both on the same scale. For example, let’s say Newton is considered the smartest person in history and let’s say the number of people ever born is 100 billion. Then Newton’s IQ estimated based on rarity and based on the assumption that the distribution of scores is normal would be rIQ=207.3 (σ=16, G). But the actual distribution of scores is not normal, so you cannot compare that 207.3 with a score of 207 measured in a test, because they are on different scales. Both may have the same standard deviation (16 in this case), but the shape of the distribution is different and this cannot be neglected because the distortion produced is gigantic.
Newton’s rIQ would be 207.3 but his pIQ would be 261.8. To repeat: both scores have a standard deviation of 16, both rIQ and pIQ. This process should not be confused with changing scales with different standard deviations. The standard deviations are the same, but the shape of the curve is different. I’m repeating this several times because I’ve seen people confuse this just a paragraph after it’s been cleared up.
This adjustment is necessary to correct the distortions of the norms and to allow the correct calculation of rarities from the scores measured in the tests, or the inverse process of calculating the IQ from the rarity level.
Thus, the person with the highest rIQ (σ=16 G) in a population of 7.9 billion has rIQ 201.2, which is equivalent to pIQ (σ=16 T) 247.8. The scores 201.2 (σ=16 G) and 247.8 (σ=16 T) are equivalent, as 0 o C and 32 o F. The use of the term rIQ is equivalent to the use of the term IQ (σ=16 G), while the use of the term pIQ is equivalent to the use of the term (σ=16 T). I can also eventually use rIQ (σ=16 G) or pIQ (σ=16 T).
So tests can (and do) produce scores above 200 with a standard deviation of 15 or 16, but the correct calculation of rarity levels or percentiles should not be performed the way it has been done for decades. The percentile and rarity calculations are wrong, as I’ve demonstrated since my 2000 papers on this. I’m not referring to tests with inflated standards. Of course, this problem becomes more serious when the norms are inflated, but even when the norms have been calculated properly, as in the cases of the Mega Test or Titan Test norm, both the Hoeflin version and the Grady Towers version both provide incorrect values for the percentiles. The IQ scores are very close to the “correct” values, which would be the values adjusted to a well-standardized range scale. The problem is not with the measured IQs, but with the percentiles calculated based on the incorrect assumption that these scores are normally distributed. This topic will be analyzed again at other times, in more detail, when the topics covered require it. For now, this introduction should be enough to clear up much of the confusion that occurs with the indiscriminate use of the term “IQ”, without making the correct distinction between pIQ and rIQ.
When Chris Harding was registered in the 1966 Guinness Book with an IQ of 197, based on his Stanford-Binet results, this was a relatively primary and serious error because it incurs all 3 problematic items I cited above: SB does not include questions difficult enough to correctly measure above 135; the cognitive processes required in the solutions are not appropriate for IQs above 150; the calculated rarity level is incorrect.
In 1966, the world population was 3.41 billion people, and the theoretical level of rarity for scores 197, assuming the distribution of scores was a Gaussian with a mean of 100 and a standard deviation of 16, was 1 in 1.49 billion. So it seemed plausible that a person with that score could be proclaimed the smartest person in the world, or at least the person with the highest IQ in the world. However, a correct analysis of the situation reveals that the SB score of 197 does not indicate a rarity level of 1 in 1,490,000,000, but 1 in 870,000 (about 2000 times more abundant). Also, the variable measured at the rarity level of 1 in 870,000 is not intelligence. At this juncture, the most that could be said on the basis of a SB score of 197 is that the person showed consistent evidence of having an intellectual level above 135 IQ, and as their nominal score was well above 135, there is a good chance that their The correct IQ is greater than 150, perhaps greater than 160, but it would be necessary to prescribe a complementary exam, with more difficult questions and with appropriate construct validity, to investigate the real intellectual level of this person, since scores above 135 are outside the range at which the test is able to measure correctly.
In the following years, several other people began to emerge claiming the same record, with scores of 196-197. This continued until 1978, when the situation worsened, first with Kim Ung-Yong scoring 210, then Marilyn vos Savant scoring 230, corrected to 228, then corrected to 218, and finally Keith Raniere , in 1989, scoring 242. All based on clinical tests that are not suitable for correctly measuring above 135.
A similar problem happened to Langan in the Mega Test. The difficulty level of the Mega Test questions is suitable for correctly measuring up to about pIQ 194, equivalent to about rIQ 177, which corresponds to a rarity level of 1 in 1,340,000. This is the realistic rarity level corresponding to the Mega Test ceiling. In 2000 I had calculated a ceiling of pIQ 186 for the Mega Test, equivalent to rIQ 169, hence a rarity level of 1 in 124,000, but I was basing it on the sample of 520 tests available on Miyaguchi’s website. However, this sample is not representative of the set of more than 4,000 people examined with the Mega Test. This sample is stratified by 10 out of 10 (10 people with each IQ when possible). That is why there is a concentration of high scores above the “correct”, causing the difficulty of the items, especially the most difficult items (which is determined by the proportion between errors and hits) to end up being lower than the correct one, since there are more people with higher scores, there will be a higher percentage of hits than if the entire sample had been considered. Another factor is that even considering all the more than 4,000 people evaluated by the Mega Test, there is a self-selection that produces a higher concentration of people with high scores than that observed among the general population. With these two complementary adjustments, I redid my calculations for this standard and arrived at the numbers I cited above.
Therefore, with a raw score of 47/48, obtained by Langan on his second attempt, the corresponding rIQ is 176, equivalent to pIQ 192, that is, a rarity level of approximately 1 in 983,000. The actual rarity level of Mega Society is around 1 in 62,000 and Prometheus 1 in 8,000. In the cases of ISPE, TNS, etc., as they are in a range where the distortions are smaller, the true rarity is also closer to the theoretical rarity. 1 in 600. And in the case of Intertel and Mensa, they are practically unaffected. The theoretical percentile 98.04% for pIQ 133 score is equivalent to rIQ 131.8, therefore percentile 97.66%.
There are two other points I would like to comment on in this introductory text, before proceeding: on the meaning of “intelligence” and on the meaning of “certificate”, but the text has become too long and it is perhaps better to remove it, as well as other parts of some answers. Anyway, I’ve saved the full text in a separate file, in case it has any additional use or to be used on another occasion.
Having made these clarifications, we can now begin the answers.
Scott Douglas Jacobsen: When you were growing up, what were some of the prominent family stories being told over time?
Hindemburg Melão Jr.: I’m not very interested in stories.
Jacobsen: Did these stories help give a sense of an extended self or a sense of family legacy?
Melão Jr.: My grandparents were very poor, my father only studied until the second year of elementary school (2nd year). He was exceptionally intelligent, creative, had hypermnesia and a wide range of intellectual and kinesthetic talents. This allowed him to lift himself out of extreme poverty and provide a satisfying environment for his children, but not much else. My parents’ legacy is almost exclusively genetic.
Jacobsen: What was the family background, eg geography, culture, language and religion or lack thereof?
Melão Jr.: My maternal great-grandfather was a native Indian of Brazil, my paternal great-grandfather was Portuguese. My family was Catholic at the time I was born, but later they converted to Kardecism, preserving some Catholic habits. I became an atheist at approximately 11 years old, then an agnostic at 17 and a deist at 27. I was interested in the Bahá’í Faith for some time, but did not participate in any activities. I am writing a book dealing with Science and Religion, in which I cover some of these topics in more detail.
Jacobsen: How was the experience with peers and schoolmates as a child and teenager?
Melão Jr.: It was reasonably quiet, I had no problems with bullying that could be associated with discrimination on cognitive grounds. I was bullied for other reasons, because I had my eyebrows together, but nothing that caused me great embarrassment, even because I had been practicing martial arts since I was 7 years old, so if I thought they were crossing the line, I reacted in a different way. energetically and that kept them from bothering me again
My problems were with some teachers more than colleagues, because I had the incorrect view that teachers couldn’t make mistakes in their discipline, but in the real world it’s very different from that. Virtually every teacher made several mistakes every day, and I used to point out the most serious mistakes. Most of them reacted positively to it, some were grateful for the corrections and revised it immediately, but others did not accept this type of correction, especially when it came from a 7 or 8 year old. A remarkable episode occurred in a Geography class, when I was 9 years old, and the teacher asked the students to calculate the size of the Brazilian coast. When I started to perform the task, I realized that it didn’t make sense, because the measurement would depend on the level of detail of the map, so there was no possible answer. So I explained the problem to her, but she didn’t understand my explanation. She thought I was referring to the map being on a different scale than its actual size. So I explained again, but it didn’t help, she still didn’t understand, got angry and ended up acting oppressive, ordering me to shut up, and continued to “teach” incorrectly. It was a very unpleasant episode. Usually the errors that I identified were errors of the professors, but in this case it was much more serious, because it was an institutionalized error and accepted as if it was correct by the “authorities” in that discipline, it was wrong in the book and probably in all other books, being incorrectly taught to all students. In fact, this remains wrong to this day, 40 years later, in virtually every source on the subject, including Wikipedia, Encyclopedia Britannica, IBGE, Cia World Factbook, US Bureau of Labor Statistics, etc. The problem is not that the measurement number is wrong. The problem is that the question does not make sense because there is no “length” of the coastline, there is no possible answer with dimension 1, because the perimeter has a dimension greater than 1 and less than 2. Although it was unpleasant, it was also a problem. event that I remember with pride, for having deduced one of the fundamentals of Fractal Geometry, impromptu, at the age of 9.
Jacobsen: What are some of the certifications, qualifications and professional training you have obtained?
Melão Jr.: The primary purpose of certifications should be to certify that a certain person or entity fulfills requirements that would not be easily verifiable by a person from the general population. For example, an uneducated person would find it difficult to correctly assess whether a doctor is capable of treating their health, or to decide whether it would be better to receive treatment from an allopathic method or from a healer. That is why there are regulatory bodies, made up of experienced and supposedly competent specialists, which establish norms that theoretically should be necessary and sufficient to distinguish between qualified and unqualified professionals, protecting the less educated population against the provision of unsatisfactory or even unsatisfactory services and products. harmful. This is nice in theory, but in practice it doesn’t work so well, and the certification industry ends up serving other purposes, including market reserve, nepotism, the cult of vanity and egolatry.
Certificates often do not fulfill the function for which they were created, either approving insufficiently skilled people/entities , or failing to approve overqualified people. For this reason, it would be more important and fairer to examine actual achievements, competences and merits, rather than examining certifications that would recognize these merits, because merits have intrinsic value, while certifications are mere appearances that they sometimes try to represent. the merits, but they don’t always get it right.
There is even a large industry for trading fraudulent certificates, and little enforcement over it. The American Biographical Institute (ABI) is famous for selling worthless certifications, and has been operating since 1967. There are many similar bodies that specialize in printing beautiful certificates, promoting certification ceremonies, and so on. Usually people who consume these products are naive victims, but it is also possible that some people buy these certificates knowing what they mean (or don’t mean).
Wikipedia has the following description for the ABI:
“The American Biographical Institute (ABI) was a paid-inclusion vanity biographical reference directory publisher based in Raleigh, North Carolina which had been publishing biographies since 1967. It generated revenue from sales of fraudulent certificates and books. Each year the company awarded hundreds of “Man of the Year” or “Woman of the Year” awards at between $195 and $295 each.”
Source: https://en.wikipedia.org/wiki/American_Biographical_Institute
There are currently several PO Box universities handing out Ph.D. Like water. I watched some statements from people who bought these titles, the vast majority of these people really believed they had some value and were excited, happy and proud to receive the title. But maybe not everyone is naive and some understand that these titles don’t represent something real, but use it for obscure purposes. There is a member of mensa brasil who has more than 50 academic titles from a PO Box university, founded in 2021, but on the “institution” website he claims to have been founded in 2006. I find it funny, and at the same time sad, that journalists who publish the articles about this do not suspect that a 40-year-old person, who only had 1 B.Sc. by 2020, it suddenly had more than 50 academic degrees in 2022, including several Ph.Ds. and postdocs. In addition to the certificates purchased, this person also claims that TNS is the most exclusive high-IQ society in the world, he uses his IQ with a standard deviation of 24 to compare with a fictitious “IQ” of 160 attributed to Einstein, among other things, and journalists publish everything without checking.
There are also people who buy these certificates, knowing they are worthless, with no intention of making dishonest use, perhaps as a table decoration or something. For example, Chris Harding is a customer of ABI, he has acquired several titles from that company, as he declares in his profile on the OlympIQ Society. Harding has some real merits, because even though the SB doesn’t correctly rate above 140, it is recognized that this test assesses some sort of skill mixed with intelligence, and few people achieve Harding’s score on this exam. So while some certificates are purchased from him, others are based on real merit and issued by serious institutions, such as those related to his IQ records and his affiliations to high-IQ societies. However, even reputable certificates, which try to represent true merits, often attest to something that is not a good representation of reality. As I mentioned at the beginning, the SB score of 197 or 196 could not be interpreted the way it was, and the official reports and certificates issued are saying something that represents a collective belief, but very different from concrete reality.
Harding is very smart, but not based on the score he got in the SB, but based on his various opinions on different subjects. His real merits are in his essence, in his actions, in his thoughts, not in pieces of paper.
From the moment a person channels his thoughts and actions to produce something concrete, he begins to share his essence with the world, disseminating knowledge and wisdom, or disseminating futility and misinformation, depending on the quality of what he shares. And the perception that other people have of what she shared will depend not only on the quality of what she externalized, but also on the sensitivity and insight of the person receiving the information. If a brilliant person disseminates knowledge of a very high level among a very futile audience, the value of that knowledge will not be recognized and he will have no certifications, no awards, nor any recognition, while other people who are disseminating vulgar and shallow knowledge, compatible with the public that receives it and issues the certifications, that person will be acclaimed and glorified.
People are not rewarded or certified because their achievements are great, but because their achievements are perceived as great by the members of the committees responsible for the approval of awards and certifications. In addition, there are a number of other political, social, racial, etc. biases that interfere with the decisions of committee members, making certifications and awards even more inconsistent with the objective they should have.
This effect occurs, for example, in some Cooijmans tests, where the test does not measure IQ, but rather how similar the person’s IQ is compared to the Cooijmans IQ. If the person has the same IQ as Cooijmans, he will have a maximum score. If she has an IQ much higher or much lower than Cooijmans’ IQ, her score will be low. In the question about IQ tests, I comment in more detail on this problem.
I will cite a few striking examples, some quite well known, but they are worth recalling. I believe that one of the most tragic and striking is that of Galileo, who instead of being rewarded for his remarkable contributions to the understanding of the Universe, he was severely punished. In fact, his daughter Celeste ended up being punished in his place. In more recent times, one of the cases that I find very sad is that of George Zweig, who developed his Theory of Aces at the same time that Murray Gell-Mann developed the Theory of Quarks. Both were essentially the same, however the journal to which Zweig submitted his paper refused to publish it, while Gell-Mann’s paper won him the Nobel Prize in Physics. There are at least 45 known cases of controversial Nobel prizes, of people who received undeserving or deserved it but did not. The world’s most respected award is desecrated by dozens of injustices, perhaps hundreds if you consider the ones that have not been discovered. Even Einstein is one of the biggest victims, since he deserved to have received 5 Nobel prizes, however he received only 1, for racial, xenophobic, Nazi reasons etc.
I believe that now I can answer this question by dividing it into two parts:
- Awards and certifications.
- Merits so far not recognized.
I have few certificates. When I was young, I was in the habit of putting trophies and medals in Chess, Martial Arts, Arts Education, etc. on a shelf, but during one of the changes of address, one of my trophies broke. Initially I was sad, because they were important to me. But as I thought more about the “disaster,” I realized that they really didn’t matter. What really mattered were the merits that led me to win those awards, as well as some merits that were not awarded. There were also cases in which I had no merit, but had been awarded due to some fateful fate. That doesn’t mean I’m not a vain person. I am, but I’ve learned that most of the time you get nothing or almost nothing for something valuable, while other times you get more than what’s fair for something of little or even worthless. Unfortunately, the world rewards appearances much more than essence.
One of my few certificates is the world record holder for longest announced mate in simultaneous blind chess, recorded in the 1998 Guinness Book. Perhaps some people are not familiar with the meaning of “blind chess” and “announced mate ”. This video helps to understand the dynamics of a blind simultaneous: https://youtu.be/LUo89Cl9FPY . It’s an old, low quality video, but to exemplify the mechanism of the event, I think it’s appropriate:
I will give a brief description: in a simultaneous, one person (simultanist) plays at the same time against several opponents (simultaneously), each of which has its own board. It is different from a consultation game, where several players can consult each other on a single board and decide on the best move by voting. In a simulcast, each simulcast has its own board and each game follows its own course.
In this case, as it is a blind simultaneous, the simultanist does not have visual access to any of the boards, nor to the pieces, nor to the summaries, nor to any type of record of moves or positions. At no time may the simultanist look at any of the boards, nor request any information that helps him to remember the positions of the pieces, nor any specific piece, nor that helps him to remember the order of the moves, nor any other type of information that can in some way help with the matches. The position of each of the pieces on each of the boards is registered exclusively in the simultanist’s memory and these positions are mentally updated with each move. In addition, at each move the simultanist needs to make the calculations of the variants and sub-variants necessary to make his decisions about the move to be executed, taking care not to confuse the memories of the calculated variants with the memories of the variants actually played, among others. care.
The game develops as follows: the simultanist stands with his back to the boards and communicates his moves to an assistant (speaker), who executes each simultanist move on the respective board. Then, the simultaneous player on that board executes his answer on the board and the speaker verbally communicates to the simultaneous player which move was executed by that simultaneous player. Then the speaker moves to the next board, where again the simultaneous player declares his move and this is executed on that board by the speaker, etc.
There are easier (or less difficult) versions, in which the player can blindly access a list with all the moves noted, as in Melody Amber’s tournaments, in which, in addition to being individual games, instead of simultaneous , competitors can also see an empty board, which facilitates calculations and reduces the risk of forgetting the position of a piece. But under the strictest rules, as in my 1997 Guinness record, it was not allowed to have access to the move history, nor to see an empty board, nor any other similar kind of aid. It is equivalent to being blindfolded all the time, from start to finish of the event.
That record set in 1997 was a blind simultaneous to 9 boards, in one of which I announced mate in 12 moves. The average rating of my opponents was estimated at around 1400. I got 7 wins, 1 draw and 1 loss.
Previous record holders were: Joseph Henry Blackburne (mate in 8 moves in a 10-board blind match in the year 1877), Samuel Rosenthal (mate in 8 moves in a 4-board blind match in the year 1885) and Garry Kasparov (mate in 8 moves in a blind simultaneous to 8 boards, in the year 1985). There was also an event in 1899, in which Harry Nelson Pillsbury announced mate at 8 in a 10-board blind simultaneous, but there was a miscount. Following the sequence dictated by Pillsbury, mate took place in 7 moves.
In the case of Kasparov, there are some details that need to be clarified: he played a blind simul against the 8 best computers of the time, including the world champion Mephisto Amsterdam 68000 RISC 12MHz. The average rating of these machines was about 1500 and the best reached 1800. The best computer in the world in 1985 was precisely the Mephisto Amsterdam, whose rating published by the manufacturer was 2265, but later measured by SSDF in 1827 (based on 1020 matches). In the match against Mephisto Amsterdam, Kasparov played a beautiful combination with an 8-moves mate streak, but there is no record of him having announced the mate. In any case, as he sacrificed a Rook and two pieces at the start of the combination, it is clear that he correctly calculated the entire sequence.
In 2005, Rede Globo did a report for the program “Fantástico” celebrating 100 years of IQ tests, and I was nominated as the person with the highest IQ in Brazil, at the level of 1 in 200 million. This is an example of “recognition” that I’m not sure was correctly assigned. In the question about IQ, I discuss this subject in more detail.
Recently, my friend Domagoj Kutle honored me with a kind invitation to publish in his excellent magazine Deus VULT, and requested that I also send a short biography. My girlfriend Tamara kindly helped me craft this material, including some of my accomplishments. I think this would fit here, so I’ll paste the text:
Melao mini-bio, by Tamara Rodrigues:
Hindemburg Melao Jr. was born in Brazil, in a family with few resources, and only attended school until the 11th grade, having learned almost completely as self-taught.
In 1998 he was registered in the Guinness Book as the holder of the world record for longest announced checkmate in blindfold simultaneous chess games.
Between 2006 and 2010 he developed an artificial intelligence system to trade in the Financial Market; in 2015, his friend and partner Joao A.L.J. incorporated a hedge fund to use this system and started to be registered in fund rankings (BarclayHedge, IASG and Preqin), winning 21 international high performance awards.
In 2007, Melao solved a problem that had been unsatisfactorily solved for 22 years, by creating an index to measure performance adjusted at risk that was more accurate, more predictive and conceptually better founded than the traditional indexes of William Sharpe (Nobel prize 1990) and Franco Modigliani (Nobel 1985).
In 2003 he solved a 160+ year old problem by proposing a new formula for calculating BMI, superior to the traditional one and superior to the formula proposed in 2013 by Nick Trefethen, Chief of the Dept. of Numerical Analysis at the University of Oxford, Leslie Fox Prize(1985), FRS prize, (2005), IMA Gold Medal (2010). Trefethen’s 2013 formula is an incomplete version of Melao’s 2003 formula.
In 2000 Melao developed the first method for standardization of intelligence tests that produces scores in scale of ratio and in 2003 he applied this method in the Sigma Test norm (he also calculated new norms for Mega and Titan tests using the same method), thereby solving a problem of Psychometry that exists more than 90 years ago and was pointed by Thurstone and Gardner as a central question of Psychometry more than 45 years ago.
In 2002 Melao found the best solution to a problem that has existed for more than 520 years and had been attacked for more than 65 years, the Shannon Number, which was only matched in 2014 by Stefan Steinerberger, professor of mathematics at Yale University.
In 2015 Melao showed that the method recommended by the Nobel Prize in Economics Harry Markowitz, for portfolio optimization, has some flaws, and proposed some improvements that make this method more efficient and safer.
In 2021 Melao pointed out flaws in the recommendation of the 2003 Nobel Prize in Economics, Clive Granger, regarding the use of the concept of cointegration, and presented a more adequate solution to the same problem.
In 2022, Melao solved a problem that had been open for 16 years, in which he established a method for calculating chess ratings based on the quality of the moves. Also presented an improved version of the Elo system, applying both methods to calculate the ratings of more than 100,000 players between years 1475 and 2021, the results were published in a book, along with the description of the two methods.
At 9 years old Melao deduced one of the fundamentals of Fractal Geometry and at 13 he developed a method to calculate logarithms. At age 19 he developed a method for calculating factorials of decimal numbers without using Calculus.
Also at the age of 19 (1991) he developed an invisibility machine project, which in 1993 he inscribe in a contest of ficction Literature (although the project is consistent with Scientific Method), but did not win. In 2003 Susumu Tachi, Emeritus Professor at the University of Tokyo and guest Professor at MIT, created (independently) a simplified version of this project and built a prototype.
In 2020 Hindemburg presented a study showing that Jupiter’s Great Red Spot cannot be 350+ years old, as was believed. The correct age is around 144 years old.
In 2000 Melao had a chess theoretical novelty elected one of the 10 most important in the world by the Sahovski Informator jury, the world champion Anand was one of the judges and Anand’s vote was that this novelty should be the 8th most important.
In 2004 Baran Yonter, founder of Pars Society (IQ>180, σ=16), estimated that Melao IQ should be above 200 (σ=16).
In 2005 the production of the program “Fantástico”, from Globo (second-largest commercial TV network in the world), made a special report on intelligence, celebrating the centenary of the creation of IQ tests, and Melao was nominated as the person with the highest IQ in Brazil, with a rarity level of 1 in 200 million.
In 2009 Melao was nominated by Albert Frank to participate in a John Hallenborg project with people whose IQ is at the rarity level above 1 in 1 million.
In 2000 Melao updated and extended his “Alpha Tests” that he had created in 1991, added new questions, and created the Sigma Test.
In 2022 he extended the Sigma Test by creating the extended version.
Melao is author of more than 1700 articles on Science, Statistics, Psychometrics, Econometrics, Chess, Mathematics, Astronomy, Physics, Cognitive Science, Ethics, Philosophy of Science, History of Science, Education etc.
Detailed bio of Melao (documents, videos, interviews, articles, reports etc.) at: https://www.sigmasociety.net/hm
Although I practiced Martial Arts for several years (maybe ~11 years if you add up all active periods), I didn’t get any certification, because the time was distributed among many different disciplines and I didn’t reach black belt in any of them. But I reached a reasonable technical level. For handguns, maybe I’m in the 99.9% percentile and in the specific case of nunchaku, maybe 99.999%. This is a video from 2016, I was already kind of old and rusty https://youtu.be/jCw–5H34x4 . On the same channel there are also videos with other weapons (sword, tonfa, kama, sam-tien-kuan, etc.).
In 2020 I was invited to a group of the 26 best planetary astrophotographers in Brazil. Although there is no certificate for it, I was very happy because it is one of my favorite hobbies. I would like to take this opportunity to thank my friend Vinícius Martins, who taught me almost everything I know about planetary image processing, I believe that in a short time he will be one of the 5 best astrophotographers in the world, he combines 3 fundamental extraordinary talent, an immense love for this activity and a deep knowledge that is constantly expanded and updated.
Among the certifications that I do not have, one of the most interesting is the CFA, granted to investment managers. It is interesting because between 2006 and 2010 I developed an artificial intelligence system to operate in the Financial Market that between 2015 and 2020, when it was used by a European fund, won 21 international high performance awards in the Barclay’s Hedge, Preqin and IASG rankings, being also the second best investment system in the world between 2011 and 2016. However, I was banned by the CVM from providing management services because I do not have the CFA certificate. In 2014, a petition was made to request that the CVM (Brazilian Capital Markets Regulator) issue me a certificate on an extraordinary basis. The claim was based on the wording of CVM Instruction 306 and on the fact that my system had accumulated more than double the profit of the fund that occupied the first place (ahead of 282 other funds, all managed by certified managers) in the ranking of the InfoMoney, the largest ranking of funds in Brazil. Among the people who signed the petition on my behalf were several university professors, several professional managers, and several members of high-IQ societies, including Dany Provost of Giga Society. However, the claim was not accepted and I still do not have this certificate. By the way, the two most famous managers in the world, Warren Buffett and George Soros, also don’t have a manager certificate, so I’m in good company. Buffett solved this problem by incorporating a company that buys other companies, rather than running a fund. Soros solved the problem by putting his friend Jimmy Rogers as gestures (Jimmy had the necessary certification), I solved the problem by trading licenses to use my system, with a volume limit of application for each license and a renewal period.
Among the certifications I don’t have, I can also include CNH, although I drive outside the law (I’m practically a gangster). I stopped going to school in the 5th grade, then I went back a few times, due to pressure from my parents. I would come back, I would continue enrolled for a few months, I would run out of patience, I would stop again, my parents would pressure me to come back, I would come back again, etc. I finished high school (11th grade) and entered the Physics faculty, but I didn’t like the course and I stopped for good after 2 months. In the first week of class, I reviewed the Physics I textbook and pointed out over 200 errors, sent my comments to the author, with an introductory note trying to be tactful so he wouldn’t be offended, but he never responded. I also pointed out two serious conceptual errors in the methods used in the Physics laboratory, which should impact the results of the experiments; one of them, on the crumpled paper balls, is the same “experiment” carried out in the Mathematics Department at Yale University, where they also make the same mistake. In that case, Prof. Dr. Paulo Reginaldo Pascholati had an honorable conduct, he received my criticisms with humility, he did some experiments to investigate whether the error I indicated was justified, he found that I was right and, in the next class, he publicly admitted the error. I found his conduct exemplary in this regard, however the handout was not corrected and they continued to do the experiment incorrectly.
Anyway, I decided that university was a waste of time and it would be more productive to study on my own, but it’s not that simple, and this decision proved questionable on some occasions. The distance from the academic career has some positive aspects, some negative ones. One of the positive aspects is that I can select my own curriculum, go at my own pace, and delve as deep into each topic as I want. One of the negative aspects is that it becomes more difficult to have access to satisfactory bibliography and even more difficult to publish in indexed journals. In doing so, I practically ostracized myself.
Therefore, certificates are useful, but it is important to understand the limitations and distortions they may present, so as not to run the risk of dealing with them in a bureaucratic way, to the point of being placed above the real capacity verified empirically on a continuous basis. Certificates reflect the opinions of people or institutions that are often not qualified enough to make correct assessments on the merits and to decide impartially. In the example of the CFA, certifications are literally distributed based on excessively condescending criteria, which are far from sufficient to select qualified people to exercise the role of manager, which is why more than 95% of certified managers generate losses for their clients. Perhaps this effect is more noticeable in the Capital Markets than in any other activity, but it also frequently occurs in Journalism, Advertising, Administration, etc., where some people without training in these disciplines may eventually be more qualified than certified people, but for protect the less competent, laws are created that prevent companies from hiring the most competent, using certificates as an instrument of discrimination and apology for mediocrity.
I wrote an extended version of this answer, in which I discuss some failures in the education system in Brazil and in the world, justifying why I moved away from academic life. I also point out and analyze the mistakes made by Richard Lynn in his study of IQs in different countries and explain why it would not be correct to try to justify the educational problem in Brazil based on the supposedly low average IQ of the population, as well as revise the estimate for the IQ average for some countries, including Equatorial Guinea, Israel and Brazil. The text was 10 A4 pages, so I thought it best to put it as an appendix.
Jacobsen: What is the purpose of intelligence tests for you?
Melão Jr.: the most important attribute of living beings is intelligence. Without intelligence there would be no Ethics, Laws, Science or Art. In order to correctly delegate the most important tasks to the most qualified people, it is necessary to correctly identify and rank people according to their abilities. That is why correctly measuring intelligence and using the results as a criterion for assigning positions and tasks, according to the level of competence, is extremely important, but unfortunately this is not what happens. There are two big problems:
- The first is that the world is dominated by nepotism;
- The second is that there are no appropriate intelligence tests to correctly measure at the highest levels.
In the late 19th century, the first tests by Galton and Cattell failed to satisfactorily measure intelligence, but it was an interesting attempt. The hypothesis that the speed of reflexes, visual acuity, auditory acuity, etc. could be relevant indicative of the intellectual level proved to be inadequate. In 1904, Binet and Otis managed to solve this problem by using questions that required the combined use of various cognitive skills – rather than trying to measure primary aptitudes, as Galton did – but Binet’s tests only measured correctly up to about 140. Terman’s attempts in 1921 to use Binet’s tests to select future geniuses failed. Among the 1528 children selected with an IQ above 135 (more than 70 with an IQ above 177), none won a Nobel or any similar prize, while two of the unselected children won Nobel prizes. The test worked very well until about 130, the selected children published more books, more articles, had a higher average income than the children in the other group, but at the higher levels, the test failed and missed some of the brightest children. The results of this study had an extremely deleterious effect, undermining the credibility of IQ tests in the eyes of the general public and in the eyes of many intellectual exponents from scientific, technological, cultural and educational fields, so it would be important to clarify the limits of until point these tests can measure correctly, so that unrealistic expectations are not created and so that they are not applied incorrectly outside these limits.
In 1973, Kevin Langdon created the LAIT (Langdon Adult Intelligence Test) and with that he managed to raise the difficulty level to close to 170 and the construct validity to 150; In 1985, Ronald Hoeflin took another important step forward with the Mega Test, raising the difficulty level to about pIQ 190 and construct validity to 170, and these contributions broadened the horizons of application of intelligence tests, which previously worked well until the approximate level of 1 in 100, while the new tests started working up to 1 in 100,000. On the other hand, from the 1990s onwards, some fantasy tests began to appear with nominal ceilings that reached 250, although the real ceiling of difficulty did not reach 180 and the ceiling of construct validity was around 150, as the ISIS Test by Paul Cooijmans. Some of these fantasy tests keep popping up to this day, and this exacerbates the prejudice many people have against IQ tests, because if a person has refined critical thinking and a skeptical attitude, he realizes that there are inconsistencies in results like Feynman’s ( 123) and Rosner (193, 196, 198 etc.). Both are very intelligent, and the problems that Feynman solved are more difficult than the problems that Rosner solved, which could be interpreted as indicating that Feynman was more intelligent, so how is it possible for a serious standardized system of evaluation to assign 190+ to Rosner and 123 for Feynman? Something is obviously not right about this, and people often don’t identify exactly where the error is, so they generally conclude that all IQ tests don’t work, or they don’t even know that there is more than one type of IQ test. IQ That’s why clarifying the range in which each type of test works contributes to combating this type of prejudice. If Feynman’s true IQ, based on the difficulty, complexity, and depth of the problems he solved on quantum electrodynamics, superfluids, etc. were put on the same scale that Rosner’s IQ is represented, Feynman’s correct IQ would be close to 235. And to explain this number above 200, I would first have to show that the distribution of scores is not Gaussian, etc. etc. Then that apparent initial inconsistency would disappear and everything would become clearer and more logical. The same is true for Einstein’s fictitious IQ of 160, whose correct value, if placed on the same scale as the scores measured by the tests, would be close to 250.
In 2000, the Sigma Test brought solutions to the 3 problems cited in the introductory text, with the main focus on construct validity, using questions based on real-world problems that require a combination of convergent and divergent thinking at different levels of difficulty, complexity and depth, consistent with the IQ levels to be measured. More recently, the Sigma Test Extended raised the ceiling on difficulty to about pIQ 225 and construct validity to about 210. However, in a population of 7.9 billion, the smartest adult person in the world must have an rIQ of around 210. 201, equivalent to about pIQ 245, thus far outside the limits that STE can measure. Nevertheless, for some of the smartest 100 or 200 people alive, STE could provide reliable measures of real intelligence, with good construct validity at this level, in addition to offering a stimulating intellectual challenge. This would fix some urban legends disseminated in various sources, such as that the average IQ of Nobel laureates in Science is “only” 154. With the use of a properly standardized test, with an appropriate difficulty level and good construct validity, the The average IQ of Nobel Prize winners in Science should be between 170 and 190. With the use of appropriate tests it is possible to correctly reposition the scores, both up and down. This would also overcome some prejudices against IQ tests, because one of the reasons for rejection is precisely due to the bizarre results for Feynman (123), Fischer (123*), Kasparov (123, 135), Shockley (<135), Alvarez ( <135), Feynman’s sister (124), etc., because that takes away the credibility of the tests, as these scores are far more likely to be wrong than these people having IQs below the 1 in a thousand level, when in fact they should be above 1 in 1 million (and Feynman close to 1 in 1 billion). When we can show that tests are able to measure correctly even at very high levels and provide realistic results, consistent with the achievements of these people in real-world problems, we can restore credibility to intelligence tests as serious and reliable instruments capable of to perform one of the most important functions, which is precisely to make early predictions of genius. [*Although many sources mention an IQ of 187, 181, or 180 for Fischer, his 1958 reports show a score of 123]
So while there are no tests capable of correctly measuring at the level needed to pinpoint the smartest person alive, or rank the 10 smartest, there has been substantial progress since Binet’s first tests, and if Terman were alive today and developing the same study from 1921, but starting in 2000, and if he used the STE instead of the SB, most likely the smartest children would all (or almost all) be selected in his group, and the subsequent results would have been confirmatory even at the highest levels, corroborating the thesis he defended, that it is possible to predict genius early, but not with the tests that existed at that time. The thesis itself was correct, as was Leonardo Da Vinci’s helicopter, but the technology still needed to advance a little further for the thesis to have the necessary subsidies to be tested properly.
Jacobsen: When was high intelligence discovered for you?
Melão Jr.: I find it difficult to determine this precisely. The first time I was examined in a clinic, I was 3 years old, but at 6 months of age I was able to speak reasonably fluently, so there was some earlier evidence.
Jacobsen: When you think about the ways in which the geniuses of the past were mocked, vilified and condemned, if not killed, or praised, flattered, plagiarized and revered, what seems to be the reason for the extreme reactions and treatment of geniuses? Many alive today seem camera-shy – many, not all.
Melão Jr.: I don’t think it’s a problem of the past. It is still present in many primitive cultures, such as in Brazil and in several African countries. The vast majority of the population adopts a posture of hostility, envy and boycott not only against geniuses, but against anyone who may be having any kind of success. Recently my girlfriend showed me a video of Ozires Silva, who was Minister of Infrastructure and president of Petrobras. He comments that during a dinner attended by some members of the Nobel committee (link to the video: https://youtu.be/m3u-E5XdzZ4 ) he asked why they thought Brazil had no Nobel laureates, since several Latin American countries with lower population and lower GDP even had more than one Nobel Prize. One of the committee members commented “you Brazilians are hero destroyers”. Unfortunately, this is a fact that is still present in our daily lives.
At the time I got to know high IQ communities, 1999, some famous names were William James Sidis, Marilyn vos Savant, Chris Langan, Rick Rosner, Grady Towers etc. Langan was a security guard at a nightclub, Rosner was a nudist model and also worked for a time as a security guard, Grady Towers was a security guard at a park and died a tragic and untimely death in 2000. Sidis spent the last decades of his life in underemployment and collecting license plates. Marilyn was a columnist for a magazine and got a reasonable standard of living out of it, as well as good prestige and recognition outside of high-IQ communities, as well as a lot of hateful envious. With the exception of Marilyn, the other people I mentioned earned minimum wage and still spent part of their time without a job, while many people are hired to fill positions that they are not even qualified, earning small fortunes as well as prestige and recognition.
This situation is very sad. Although Langan was not the smartest man in the Americas, as he claimed in 2000, or in world history, as he began to claim some time later, he is arguably a much smarter and more competent person than 99% of Ph. Ds. in any area and more than 99.9% of the CEOs of companies. He may not have had such a vast culture and expertise needed to solve major scientific problems, but he certainly would have given better administrative and political solutions than any president the US has ever had. I don’t know if he would be the best president, because being a great president isn’t just about solving problems. He would also need to have sensitivity, empathy, kindness, honesty and other attributes. But generally many people have these attributes at the required level. What they usually lack is precisely intelligence. I’m not saying that Langan or Rosner should be presidents. But, pondering the positives and negatives, I would bet on them as better presidents than the average of recent presidents.
Persecution and oppression can sometimes happen silently, and this is often even worse because it is harder to detect and combat. How is it possible that a person with Langan’s intellectual potential was not discovered by a large company that hired him for a millionaire salary so that he would solve internal problems in a way that generates more profit for the company than other less competent people working in the same role? There are grotesque errors in this. The vast majority of companies are contaminated by mobs of incompetents and cheats, who instead of hiring and promoting based on merit, do almost exactly the opposite, because they feel threatened by those who are more competent than themselves. This is a complete disaster not only for the companies they work for, but for the entire harmony of civilization. In Norway, Sweden, Holland, Finland, Switzerland, Denmark, etc. these problems are very rare, but in brazil this is a constant that sinks the country. In the USA, the problem may not be as serious as it is in Brazil, but when we look at the cases of Langan and Rosner, it is clear that there are serious flaws in the performance of the headhunters, failing to hire some of the most qualified people in the country, who started to most of their lives in sub-professional activities. I have cited the examples of Langan and Rosner, but the same is true of a large number of people with far above average IQs, who are working in incompatible activities, with incomes far below what they deserve, producing less than they should, while people very less capable are in high positions, making absurd mistakes and sinking companies or even sinking entire nations. My girlfriend is an environmental engineer and exceptionally smart, she worked at a large company where she solved problems that saved tens of thousands of dollars monthly by cutting waste, as well as contributing to reducing pollution. One of the solutions involving the replacement of a pipeline generated savings of a few million. If she were placed in a higher position, where her performance had greater reach, it could save the company tens or hundreds of millions. However, she was invited to participate in a corruption scheme, she refused, the person who made the invitation was afraid that she would denounce them and fired her.
In “The Republic”, Plato commented on the importance of kings being philosophers and philosophers being kings. This seems to me the most natural, substituting “philosophers” for “competent” which is usually almost synonymous with “intelligent”. And replacing “kings” with an equivalent modern meaning, which can be CEOs of big companies, mayors, governors and presidents. In the US there are several mechanisms to discover and mentor talented children and young people, there are several specialized programs. According to Eunice Maria Lima Soriano de Alencar, in the 1970s there were over 1200 educational programs for gifted children in the US. How is it possible that these programs “missed” Langan and Rosner? How could a respected entity like Hollingworth Institute not discover them? It’s not possible that they didn’t excel at school. In Brazil I would think this is normal, Brazil lets almost all the great talents go down the drain. But in the US I find it surprising that this has happened. There are records that Langan scored perfect on the SAT and received scholarships at two universities, but it appears that he lost his scholarship because he was late one day because his car broke down. This is pretty ridiculous. Even if he missed every class, he would probably learn more and better than 99% of his classmates who were present in every class. The universities did not award scholarships in recognition of his genius, but as a “handout”, with restrictive conditions to withdraw the handout if he did not meet certain criteria.
This waste of great talent is one of the main reasons that leads a country to ruin. China is catching up and surpassing the US in large part because China has invested more seriously and more heavily in special education for gifted children, while the US is making gross mistakes like this, letting great minds like Langan, Rosner, Towers are wasted on jobs like nightclub or park security, while less-skilled people lead big companies, govern cities and states.
Nepotism is not an exclusively family phenomenon. It is much broader, leading to the placement of underqualified people in positions that should be filled by others with more merit. There is no optimization in the delegation of positions, responsibilities, tasks, incentives, awards, etc. And this lack of optimization is obviously penalized. Competitors who optimize this best take the lead.
In Brazil the situation is much more serious, because there are no such programs. There were a few isolated initiatives, which reached a few dozen children, but they did not last long.
Intelligence tests are extremely important to be used in these talent discovery processes. Although the tests have several flaws, it is better that they are applied as far as possible, with errors and patches, than if they were not applied and this calamity was perpetuated. Some of the tech giants create their own tests to select their collaborators, usually these tests are not as good as the hrIQts, but at least they demonstrate that they understand the need for it. Although they are patching up the problem badly, at least they are trying to do something to identify young talents and engage them in relevant projects, in which they can contribute to the development of Science, Technology and the common good, so these companies do better than the government in this regard.
Jacobsen: Who seems like the greatest geniuses in history to you?
Melão Jr.: Leonardo, Newton, Aristotle, Gauss, Ramanujan, Archimedes, Euler and Einstein.
It is difficult to judge the cases of Hawking, Galois, Faraday, Al-Hazen and others, because Hawking had to face extreme hardships, it is difficult to know what the magnitude of his legacy would have been had he not fallen ill . It is possible that Hawking is one of the 5 or 10 smartest people in history, although his effective work is not one of the 100 most expressive, as it is not a fair representation of his potential, as he unfortunately did not have the opportunity to “compete” in equal conditions with other great geniuses. Galois was born in a very privileged situation culturally, intellectually and economically, but unfortunately he died very young. This does not mean that he would have produced much more if he had lived to be 90 or 100, because looking at the lives of other great mathematicians and scientists, most of the most important work they did was before the age of 25, eventually between 25 and 30. In addition, there are many cases of people who produced almost everything they could before the age of 20, then showed no advance or accumulation of production (Paul Morphy, for example, or Arthur Rubin). So Galois’ remarkable precocity does not necessarily indicate that he would have produced more than Gauss or Euler had he lived much longer. But even if he had not reached Euler’s level, it is likely that he would have left a monumental legacy. Faraday – like Edison, Leonardo and me – did not receive a formal education, which could be interpreted as a disadvantage, although perhaps it is not. Academic life can get in the way, in many cases, it is difficult to judge with certainty. To find out whether people with IQs above a certain level would have an advantage or a disadvantage studying as self-taught, it would be necessary to carry out experiments with several pairs of twins with an IQ in the desired range, in which one of each pair of twins would be forced to pursue a career in academia and education. another forced not to follow. There would be several problems in running such an experiment, because twins are rare and twins with IQs above a certain level may simply not be an example case, and the study would require a sample of at least a few dozen. Another problem is the ethical issue, of forcing a person to attend the unit and forcing another not to attend. This is especially serious in the case of monozygotic twins, because both would likely have similar preferences, and one of them would have to be “sacrificed” in this situation, forced to do something different than they would like.
At the time I got to know the high-IQ communities, there was a lot of talk about Sidis as the greatest genius in history, a genius wronged and misunderstood. There’s some truth to that, but there’s also a lot of exaggeration and distortion. Sidis is an unusual case and very difficult to judge, because his story is mixed with legends and fantasies. My first contact with Sidis’ “story” was through an article by Grady Towers in 1999, which he later modified in 2000. I now know that there was a lot of incorrect information in that text, but at the time I believed what was there, and I even considered the possibility that Sidis really was the smartest person in history. I now see Sidis as a victim of his parents, a forced prodigy with maybe 180 to 200 IQ, who could have been a good researcher and led a pleasant, productive life, but has been turned into a circus attraction. The 250-300 IQ that for years has been attributed to him appears to have been his sister’s invention, the 54 languages he was claimed to speak have been reduced to 52, then 40, then 26, and currently it appears he is considered to have perhaps spoken of fact 15 to 20 languages. The legend about him being able to learn 1 language in 1 day seems to be simply false. He didn’t get a Ph.D. Cum Laude at Harvard at 16, but rather a B.Sc., which is still an impressive accomplishment, but not quite. About 12% of Yale students graduate Cum Laude, Magna Cum Laude or Summa Cum Laude. In some years (like 1988) these percentages can increase quite a lot, reaching more than 30%. I don’t know the percentages at Harvard, but I suppose it’s not that different. So it is indeed expressive, but not as impressive as would be expected by someone with a supposed 250-300 IQ.
His sister’s tendency to exaggerate just about everything ends up increasing skepticism about which claims about him are true. The fact is that he did not leave a scientific or mathematical legacy that justifies the overestimation that is usually made of him. His ideas about black holes were preceded by more than 100 years by Laplace and Michell, his ideas about Evolution had already been better developed by Darwin and Wallace, in fact, Sidis’ approach is much more superficial than Darwin and Wallace’s. , being more similar to that of Anaximander and Aristotle. However, the question remains about the level of intellectual production that he could have reached if he had not withdrawn from academic life, or even withdrawn from academic life, but producing Science and Mathematics outside the university.
In terms of precocity, Gauss, Galois, Neumann and Pascal seem to me more remarkable than Sidis, not least because Gauss was a natural prodigy, while Sidis was a mixture of natural prodigy and forced prodigy. Galois, Pascal, Neumann were also natural and forced prodigies, but not as forced as Sidis. This pressure to which Sidis was subjected may have harmed him and provoked the outcome that this telenovela ended up having. I find it difficult to assess.
So if I had been asked this question in 2000, maybe I would have done a less critical and more superficial analysis and singled out Sidis as the greatest genius. Currently I would have doubts even if he would have a very high score in the hrIQts, maybe he would reach 190 in some tests, but in others he would not exceed 180. As far as intellectual production is concerned, the records do not show anything so extraordinary.
Jacobsen: What differentiates a genius from a deeply intelligent person?
Melão Jr.: The concept of “genius” is usually used to indicate exceptional ability in different scientific, artistic, sports, cultural areas, etc. In this context, one of the main differences would be the level of specificity, as the genius could indicate a remarkable talent in any area of activity (Music, Football, Ballet, etc.), including activities in which high-level intelligence is not required. In contrast to this, the profoundly intelligent person would have his talent exclusively linked to activities in which notability requires a very high intellectual level (physics, mathematics, literature, chess, etc.).
But this concept is inappropriate, in my opinion, because with the development of machines that outperform the best humans in different modalities, it becomes important not to mix “smart” machines with other machines. It might seem acceptable to say that Usain Bolt is a track and field genius, but it would be strange to say that a Bugatti Chiron is a genius, even though what the Chiron does exceptionally is the same as Usain Bolt does. It is therefore necessary to determine objective classification criteria that are equally applicable to all organic and inorganic entities, without discrimination, a criterion that works well and does not produce bizarre classifications. It would be unreasonable to say “ah, Chiron is a car, so criteria don’t apply to it”. That would be shallow and incorrect discrimination, because in a few decades there will be cars capable of talking about philosophy and demonstrating mathematical theorems, including hybrids that are part human and part cars, and if one of the criteria for being considered genius is “it can’t be a car”, there would be a serious inconsistency. A serious and fair criterion needs to be well planned, it cannot be a naive guess that does not contemplate possible exceptions.
Talents for intellectual modalities, when they reach a certain level of excellence (something like 5 standard deviations above average) can be considered “geniuses”, but for activities in which the intellectual level does not play an important role (Boxing, Football, Athletics etc. ), I believe that the correct term should be chosen more carefully, to avoid that non-intellectual machines are incorrectly classified as “geniuses” (a fast car being classified as a “genius” because it is fast seems to me to be an etymological error, but if this car is could perform intellectual tasks, the situation would change). In some circumstances, machines need to be recognized as geniuses, otherwise there will be serious inconsistencies in the syntax of the language, based solely on prejudice against machines. AlphaZero or MuZero, for example, in my opinion they (especially MuZero) are in a “grey zone” that is difficult to assess. MuZero can learn by himself to play Chess, Go, Shogui, Atari games, and reach very high level, superior to the best humans in the world in some of these games, which are recognized as intellectual games. So an attempt to adjust the criteria post facto, with the sole purpose of disqualifying MuZero as a genius, would seem to me to be a sign of unfair discrimination. Even because, the next generations of MuZero tend to present better and better what we understand as “general intelligence”, and at some point there will be no way to avoid recognizing that some machines also need to be classified as “intelligent”.
The question is whether MuZero would be better classified as “idiot savant” or “genius”. In my opinion, “genius” would be better, because idiot savants are usually not very creative and don’t excel in activities that require deep, sophisticated problem solving. They are very good at memorizing and repeating, whether mental calculations or playing songs, but I don’t know of any idiot savant who has excelled as a chess player or as a scientist. Perhaps it would be possible to reformulate the meanings of genius and idiot savant so that MuZero would be better classified as a savant, without compromising the essence of these meanings. A proper classification could not “push” Bobby Fischer or Kasparov into the savants group, for example. The classification would need to be careful, so as not to create inconsistencies with the sole objective of removing MuZero from the group of geniuses, nor presenting other types of arbitrariness.
In some other pursuits where there is no need for exceptional intellect, with an IQ of close to 120 being sufficient together with exceptional talent in a particular area, I believe the term “genius” should not be applicable. Mike Tyson or Usain Bolt don’t need much more than 120 IQ, and some vehicles without any trace of intelligence, who don’t think, can beat Bolt in the sport he excelled in, so excellence in that sport perhaps shouldn’t be seen as ” genius”.
In some cases it is more difficult to assess whether or not the term “genius” is applicable. Artificial Intelligence Systems like AIWA, which specializes in composing music, and does it at a very high level, in my view, shouldn’t be classified as “genius” either, in which case great human composers shouldn’t be classified as ” geniuses” based solely on their talent for songwriting. If this talent for songwriting was accompanied by an intellectual level commensurate with the intellectual criterion of genius, then the classification as “genius” would apply on that basis. The same would be true for boxers, farmers or professionals in any field, who would not be classified as “geniuses” based on their talents for their most prominent activities, but on their intelligence.
In this sense, there could be latent geniuses and effective geniuses. The latent genius would be in the intellectual potential to produce relevant contributions to expand the horizons of knowledge, revolutionize scientific paradigms, etc. While the effective genius would be the one who concretely does these things. A profoundly intelligent person, who has not made outstanding contributions, could be a latent genius, having the constant opportunity to become an effective genius, from the moment he uses his potential for scientific development, or for innovations in mathematics or science. in some important field of knowledge.
Some people consider the fundamental difference between a genius and a profoundly intelligent person to be creativity, but creativity is one of the components of intelligence. People often confuse logical reasoning (which is also one of the components of intelligence) with intelligence itself. But intelligent behavior is a broad combination of many cognitive processes, including memory and creativity.
The difference between “genius” and “deeply intelligent” is more quantitative and is associated with the proportions in which certain attributes are present. Creativity appears in the genius as a fundamental element, but not because the genius is creative and the profoundly intelligent person is not (both are), or even because the genius is always more creative (although he usually is). In the set of attributes, considering logical reasoning, creativity, working memory, long-term memory, etc., the genius has and uses this set of latent traits in solving novel problems with greater efficiency. As creativity is usually one of the most important requirements for this, it ends up being natural to associate genius with creativity.
Jacobsen: Is deep intelligence necessary for genius?
Melão Jr.: For the concept of genius I described, yes. In the previous answer I ended up answering this one.
Jacobsen: What were some work experiences and jobs you’ve had?
Melão Jr.: Since 2006 I have been working on the development of artificial intelligence systems to operate in the Financial Market. I am currently interested in solving the problem of prolonging life indefinitely, preserving memory and identity in inorganic devices that have a proper communication interface with the brain, resuscitating people, restoring severely damaged bodies, and other minor problems that are subsets of these and pre -requirements for these.
Jacobsen: Why pursue this particular work path?
Melão Jr.: The development of automatic systems to operate in the Financial Market is an intellectually challenging activity and offers a reasonably fair monetary reward, although the absence of a business network imposes many obstacles. The level of difficulty, complexity and depth of the problems that need to be solved to make consistent long-term profits from long-short trading is extremely high. There are some easy ways to earn 3% a year or a little more by practicing Index Buy & Hold or Blue Chips, where the gain is small but very easy. But if one wants to strive to earn profits close to 30% a year or above, the challenge is extraordinarily difficult and few people in the world actually manage to do so. As part of that work, I’ve made some interesting advances in Econometrics and Risk Management. In 2007, I solved a problem that had been unsatisfactorily resolved for 22 years by creating an index to measure risk-adjusted performance that was more accurate, more predictive, and conceptually better informed than traditional William Sharpe Nobel 1990) and Franco Modigliani (Nobel 1985). In 2015 I showed that the method recommended by the Nobel Prize in Economics Harry Markowitz, for portfolio optimization, has some flaws, and I proposed some improvements that make this method more efficient and safe. In 2021, I pointed out flaws in the recommendation of the 2003 Nobel Prize in Economics, Clive Granger, regarding the use of the concept of cointegration, and presented a more adequate solution for the same problem. Among other contributions in processes of optimization of genetic algorithms, ranking and selection of genotypes, pattern recognition, etc.
Jacobsen: What are some of the most important aspects of the gifted and genius idea? These myths that permeate the cultures of the world. What are these myths? What truths dispel them?
Melão Jr.: There seem to be different myths among different intellectual strata. For the majority of the population, with an IQ below 130, it seems that they think of the genius as a crazy, reclusive, antisocial, physically fragile person, and every physical and psychological flaw they can imagine, as a morbid need to push down. the person for not tolerating the fact that he excels at something and has little advantage in almost everything. Many movies, books and magazines try to reinforce this stereotype. But there are other incorrect ideas that are pervasive in other IQ bands. At the 130 to 180 level, for example, there seems to be an overestimation of results on IQ tests, without a correct understanding of the limits of the extent to which these tests produce accurate and reliable scores.
Another myth is related to the rarity level. People who have no concept of Psychometrics (almost all outside of high IQ societies) think that gifted people are very rare, something like 1 in a million or even rarer. They are also generally unaware of the difference between “gifted” and “genius”, including some who think gifted is smarter than genius.
Jacobsen: Any thoughts on the concept of God or the idea of gods and philosophy, theology and religion?
Melão Jr.: My family was Catholic. I became an atheist at age 11 after studying some religions. In a transition process that lasted a few years between the ages of 17 and 25, I ended up becoming agnostic. I became interested in the Bahá’í Faith at the age of 27 and at 28 I became a deist and wrote an article in which I present serious scientific arguments for the existence of God. I say “serious arguments” because all the pseudoscientific arguments I know of on the subject are desperate attempts to “prove” an a priori belief. It is different from an impartial analysis that leads to a conclusion that had not served as an initial motivation. I’m still a deist, I even founded my own religion, and I’m writing a book on the subject.
Jacobsen: How much does science influence your worldview?
Melão Jr.: Science is the only way we know of through which adequate models can be developed to represent sentient reality, functional models, capable of making generalizations and predictions, in which the results obtained are reasonably in accordance with the predictions, without predictions depend on luck for chance hits. Science is essential in the process of acquiring knowledge and technological development. On the other hand, it is important to understand the limitations of Science, as a body of disciplines that offers us a valuable method, but that is not immune to failures. The great differential of Science is not in the knowledge it produces, but in the method that allows it to correct itself and to do this constantly, updating itself, refining itself, expanding itself, etc., so that all the Scientific knowledge, even if it is fundamentally incorrect, has some practical use and works reasonably well within the limits set by Measurement Theory. Ptolemy’s cosmological model, for example, even though it was fundamentally wrong, allowed for very accurate predictions. Sometimes scientific theories may not structurally accurately represent natural phenomena, but even if the theoretical explanations are not the most correct, they work. Knowledge obtained through other means, such as philosophy, religion or popular culture, is generally less likely to “work”, and even when they do work, it is difficult to regulate the parameters that determine their functioning, due to the absence of an underlying theory that be organized by a mathematical model.
Jacobsen: What were some of the tests performed and scores obtained (with standard deviations) for you?
Melão Jr.: There is no simple answer to this question. In fact, among all the questions in this interview, this is perhaps the most difficult, because in addition to giving a correct answer, I need to try to be diplomatic so I don’t seem too arrogant. My girlfriend has asked me dozens of times what my IQ is, Tor has asked me this at least 5 times, and I usually shy away from the subject because it takes time to explain everything. But I’ll answer it here and when other people ask me again, I’ll provide the link to that answer, including because in previous questions and in the introductory text I commented a little about clinical trials, hrIQts, estimates and comparisons. With that, I believe it will be possible to express my opinion on this topic in a reasonably complete and accurate way in less than 50 pages, taking advantage of the previous answers as prerequisites.
I was examined for the first time at 3 years of age, and I even got to the tests for 9 years, because they were not above 9 years old for children who could not read. I don’t know what the tests are called, but the standard deviation was probably 24. There are several complex points that need to be examined about this, because the evolution of intelligence as a function of age is not linear, as in Stern’s simplified formula, the deviation default is not 24 in all age groups under 16, most very young children examined are forced prodigies that parents tried to teach a lot since they were born but it was not like that in my case, my father went out to work before When I woke up and came back after I was asleep, my mom worked most of the day, so none of them even had time to spend much time with me, let alone train me like a forced prodigy. Other points to consider are that intellectual development does not end at age 16 (nor 17 or 18 or 19), nor does it reach the limit at a fixed age for all people, nor does it remain stable when reaching a certain age. Therefore the interpretation that the mental age of 9 years to 3 years corresponds to an IQ ratio of 300 is grossly incorrect and naive. Even after converting the scale with standard deviation from 24 to 16, reaching 233, it is still incorrect. The evolution curve of intelligence as a function of age also varies from one person to another. Therefore, it is not reasonable to use tests applied in childhood as a basis to try to estimate what the adult IQ will be. There are several cases of IQs measured in childhood that prove to be very far from correct in adulthood, although some may “get it right”, as in the case of Terrence Tao, who had an IQ measured at 230 and, luckily, really had an IQ. his is close to it. In my case, it is also possible that the measured IQ came close to the correct value “luckily”, but the tests used, the method used, etc. are not appropriate.
Another detail is that I don’t know if I would continue to solve typical tasks for children over 10 years old, but it is possible that I would, but the precocity in solving typical tasks for older children says almost nothing, or says very little, about the intellectual level that will be reached in adulthood, because the skills measured do not provide useful information for this type of prognosis. The type of skill that would indicate a very high intellectual level (200+) in adulthood is not related to the same type of task that an 8, 9 or 10 year old, or even 20 year old child could perform, but with the problem solving that indicated traits of creativity and deep thinking for that age. The event in Geography class at age 9, for example, was a much more relevant indicator than the test result at age 3, not only because at age 9 he had already reached greater maturity and was closer to the potential he would have as an adult. , but also, and mainly, because the type of problem involved was more closely related to the cognitive processes needed by genius adults.
As I mentioned in the introductory text, in other answers, in some articles and in some forums, IQ tests and hrIQts have problems in construct validity, errors in the calculation of the norm, and inadequacy of the level of difficulty. I already had a very bad experience with Paul Cooijmans in 2001 and I don’t plan on wasting time on it again. Cooijmans’ Space, Time & Hyperspace (STH) proposed measuring IQ up to 207 (σ=16), although the real difficulty of the hardest questions on this test is not much higher than 170. But that’s not the main problem. STH contains several primary errors that completely invalidate the test and the norm, although many people consider it to be one of the “best” hrIQts. In 2001 I wrote to Cooijmans about this and pointed out one such mistake to him, but he refused to talk about it and did not admit his mistake. I don’t have the patience to deal with people who act like him. I’ll describe exactly what the problem is using an example:
The general wording for all STH questions was as follows:
a : b :: c : d
Meaning: “a” is to “b” as “c” is to “d”.
Given “a, b, c” determine “d”.
The statement, along with the test, can be accessed at https://web.archive.org/web/20040812113534/http://www.gliasociety.org/
Here’s a print of what’s in the link above:

Question 10 is:

The general statement says that there is a relationship from the 1st figure to the 2nd figure that must be discovered and then that same relationship must be applied to the 3rd figure to produce the 4th figure. This is the only general statement for all questions in this test, presented at the beginning of the test, and it works like this in questions 1 through 9, but not so in question 10 or 16 other questions out of the 28 that make up this test.
He wanted question 10 to discover the relationship of the 1st figure to the 3rd figure and then that same relationship to be applied to the 2nd figure to produce the 4th figure! But at no time did he ask for this in the statement. What the statement asks for is exactly what I described above. If the person answers exactly what the utterance is asking for, the person loses 1 point!
There are several other issues in STH with this same basic logic error. In this surreal situation, if the person hits all 28 questions exactly in accordance with what the test statement asks for, the person will receive only 11 correct answers and score 135 instead of 205 by the current norm, or 140 instead of 207 by the norm. old.
As Cooijmans did not agree to talk about it, I talked (at the time) with 3 other people able to give an opinion: Petri Widsten, Albert Frank and Guilherme Marques dos Santos Silva.
Petri Widsten scored highest on the Sigma Test, STH and was champion in several logic and IQ contests, including http://www.worldiqchallenge.com/rankings.html , where Petri scored nearly twice the raw score of Rick Rosner. Petri quickly agreed with me on this, even to the detriment of his own answers, because he had answered what he thought Cooijmans would like to receive as an answer, not what would be the most correct answer. Every time I think about this subject, I get stressed, because Cooijmans is a very stubborn person. I don’t think Cooijmans is stupid or dishonest; I think he’s smart and he tries to do what he believes is right, but his stubbornness is greater than his intelligence.
Albert Frank was a professor of logic and mathematics at the University of Brussels, a veteran champion of chess in Belgium. Albert also agreed with me and made some comments on Formal Logic that categorize the type of mistake made by Cooijmans.
Guilherme Marques dos Santos Silva is a member of Sigma V and was champion in the IQ contest “Ludomind International Contest IV”, he also agreed with me and “gave up” to finish doing the STH after he saw this absurd error. He said there were few questions left to finish, but due to the serious bias in the correction, he had no interest in proceeding.
In addition to the people I talked to back then, I also recently talked to Tianxi Yu about this kind of issue. Yu scores 196, σ=15 on Death Numbers, which is considered a serious test with a deflated norm. He commented that he has already found bugs in several tests, and he has posted an extensive and detailed public critique of this in a group, citing the various types of bugs that bother him. There are several points where I disagree with Yu’s opinions, but in terms of testing, our opinions are very similar.
As soon as I had my first contact with high IQ societies and discovered Miyaguchi’s website (1999), I became interested in taking the Power Test, which I consider one of the best in terms of construct validity and with an adequate level of difficulty. At the time I was 27 years old and with a different opinion than I do now, I had three goals with the Power Test: one was fun, another was to beat Rick Rosner’s IQ~193 record, and the third was to get into Mega Society. At that time, the standard calculated by Garth Zietsman for the Power Test was used, with a ceiling of 197, but before I finished solving all the questions, the Power Test was no longer accepted in Mega Society and the ceiling was “revised” to 180. So I completely lost interest.
Garth Zietsman is a competent statistician and the norm he calculated , probably using Item Response Theory, is consistent and very well grounded. If the same items used in Mega, Titan, and Ultra were in Power, then the individual difficulties of those items were maintained and determined the norm for Power. So when the Power Test ceiling was changed to 180, it was a mistake. The more than 4,000 applications of Meta, Titan and Ultra, which served as the basis for the norm calculated by Zietsman, were simply disregarded, and a new norm was calculated based on a few dozen people. The correct procedure would be to add the new data (about the results of each item answered by the people examined with the Power) to the item bank that contained the Mega, Titan and Ultra questions, recalibrate the parameters of difficulty, discriminating power and casual accuracy (if applicable) of each item, then review the norms of the 4 Hoeflin tests that shared those items. Thus, the difficulty levels would be preserved equally in all tests, maintaining a unified scale.
But the way it was done, the Power norm was skewed downwards relative to the other three Hoeflin tests. To better clarify the problem, I will cite an example: in the Power Test the question about the Moebius tape is being treated statistically as if it had parameter b = +2.81, that is, 50% of people with IQ 145 (σ=16) should get this issue right. However, the same question about the Moebius tape, when applied in another of the Hoeflin tests, is being treated statistically as if it had a parameter b = 3.88, that is, 50% of people with IQ 162 (σ=16) must get this right. question. This is a serious inconsistency, because either the question has a difficulty of 2.81 on all tests in which it is used, or 3.88 on all tests. The question cannot have difficulty 3.88 on some tests and 2.81 on others. Zietsman’s norming is consistent in this regard, so the Power roof produces a norm on the same scale as the Mega, Titan, and Ultra norms.
One of the reasons that caused this reduction in the Power ceiling is because some people had already taken one or more of the other Hoeflin tests in which the Power items were present, so the probability of hitting those items on the second try was higher, increasing even more on the third and fourth attempts. But the correct way to deal with this would be to adjust all the norms of all the tests that contained those items, depending on the number of times those items had already been solved by the person examined, with norms customized for each person, or based on how many and which of the three other tests the person had already solved (an equation for this could easily be determined using cluster analysis, for example).
It could also simply look at the scores of people who had taken more than one test (or the same test more than once) and the effect that had on the probability of getting each repeated item right on the second, third, or fourth test that contained the same item. While this global adjustment to the itemset was not as accurate and refined as analyzing this effect on each individual item, as I suggested above, this would already help to improve the norms across all 4 tests, rather than distorting the Power norm in relative to everyone else.
Anyway, there is a worrying amount of errors in the hrIQts, both in the calculations of the norms and in the answers accepted as correct, among other problems. That’s why Sigma Test has always adopted a policy of transparency, being open to debates, if the person had a score above 180 in any test and they believed that some of their answers were right and they thought they received an incorrect evaluation, they could contest the correction of a question she chose. If she was right, she could challenge the correction of one more question, and so on, until her challenge was unfounded. The Moon Test and Sigma Test Extended have a similar transparency policy, but the minimum score on other tests to have this right to challenge is 190 on both the Moon Test and Sigma Test Extended. This allows reviewing any errors, as well as allowing the person being examined the opportunity to defend what they believe is right, in the event that they feel they deserved more points than they received. In my opinion, all tests should adopt a similar policy.
If there were any tests with appropriate characteristics, I would consider doing another test, even though I am older and dumber. Basically it should be a test with good construct validity at the highest levels, appropriate ceiling, and appropriate difficulty. In addition, it should have a formal “grievance” system that allows contesting the result. Without that, I see no reason to waste time on these things. An hrIQt can easily take up to 50 hours and if it’s a really hard test, with the right level of difficulty, it can take over 500 hours. It is time that could be spent on more interesting and productive activities. So unless the test brings together a number of notable virtues that justify the effort, I wouldn’t be interested. In fact, there is a test that, in my opinion, meets these requirements, but I cannot solve it because I am the author. This reminds me of a topic that was discussed a few weeks ago in a group:

In fact, some problems I’ve already solved are more difficult than the more difficult problems in Sigma Test Extended. So there are some useful clues in that.
Some people have already estimated my IQ and made some comparisons. In 2004, Pars Society founder (IQ>180), Baran Yonter, estimated my IQ to be over 200 (σ=16, G), this is equivalent to over 240 pIQ (σ=16, T). I thought he was being nice, but in 2005, when I was nominated for the production of the Globo TV show “Fantástico” as the smartest person in Brazil, I discovered that other people had similar opinions to Baran about me. I was flattered by the nominations, but I don’t know if I’m really the smartest person in Brazil and I told the journalist that, but he insisted, and as I had been the most nominated, and also for the sake of vanity, I ended up accepting to do the article, whose video is available on my page and my channel.
It is necessary to make an important caveat regarding the correct determination of the most intelligent person in Brazil, because there is a Brazilian who won a Fields medal (Artur Ávila) and there is a Brazilian who made fundamental contributions to the development of paraconsistent logics (Newton da Costa), both are very smart people, but with different profiles than mine, so it would be difficult to make a proper comparison to know for sure who is the smartest in Brazil, because each of them is deeply specialized in a very specific area, while my talents and achievements span a wide variety of different areas. As a result of greater specialization, the level of depth they have reached is greater, but this greater depth does not reflect greater depth of reasoning, but greater depth of knowledge. Also, I only studied until the 11th grade, while they did PhDs and postdocs with excellent advisors, which puts me in a “running with legs tied” situation compared to people who run on horseback. The people who worked on the same problems I worked on were equipped with more sophisticated mathematical tools, access to much more powerful computers, access to a vast, high-quality bibliography, received much more prolonged, intensive formal training under the guidance of experienced scientists, while all my “training” was self-administered, with virtually no bibliographic resources and modest computational resources. I often had to create my own statistical tools before using them to solve problems, and later I found that there were ready-made tools for the same purposes. During the development of my system to operate in the Financial Market, situations like this were repeated many times.
A detail that is important to clarify: I commented (in the appendix) that the average quality of education in Brazil is terrible, so what would be my disadvantage for not having attended this terrible environment? And the answer is simple: many of the best Brazilian academics will study at the best research centers and universities in Europe, the USA, Canada, Australia, Japan, etc. Also, there are a few really good researchers in Brazil, and when a young talent receives guidance from a first-rate researcher, it makes a huge difference. So there is a substantial advantage in Artur and Newton da Costa’s opportunities compared to my situation, because they had access to many more resources, in addition to the advantages in mentoring and training.
As for other people who have worked on the same problems as me, and I solved those problems before them or better than them or both, almost all of them are from other countries: Nick Trefethen is Head of Dep. in Numerical Calculus at Oxford University and collects some international Mathematics prizes (Leslie Fox Prize 1985, FRS Prize 2005, IMA Gold Medal 2010), Susumu Tachi is Professor Emeritus at the University of Tokyo and Guest Professor at MIT, Stefan Steinerberger is Professor of Mathematics at Yale, William Sharpe is a professor at the University of California and a Nobel Prize in Economics in 1990, Franco Modigliani is a Professor at the University of Rome and a Nobel Prize in Economics in 1985, Clive Granger was a professor at the University of Nottingham and a Nobel Prize in Economics in 2003, among others. So the people who worked on some of the problems that I solved constitute a “heavy competition”, in addition to having access to more resources, more advisors, etc. relevant before them, perhaps represents some merit to me, I have no false modesty in admitting it.
The fact is that the correct determination of the smartest person in a country is not something so simple, it is not a game of egos and vanities. There needs to be a real basis for this. For example, I think Petri Widsten has excellent chances of being the smartest person in Finland, not only because of his excellent result in the Sigma Test, but also because his doctoral thesis, besides being very innovative, was awarded as the best thesis. of the country in the 2002-2003 biennium and he won several logic contests. The aggregate of these results, and other minor details such as him being fluent in more than 10 languages, suggest a real intellectual level with rarity above 1 in 5 million, which is the population of Finland. However, there are other very smart people in Finland, like Rauno Lindström or Bengt Holmström. Although Finland is a culturally more homogeneous country, so that there is not as great a difference in opportunities as in my case, even so, the comparison is still difficult, so it would not be wise to categorically state that a certain person (Petri or Rauno or another) is the smartest in Finland. The most appropriate would be to assign a probability to each one. Petri would have around a 95% probability of being the smartest person in Finland, Maybe Rauno 2%, Bengt 1% and someone among other people 5 million people 2%. In the case of Brazil, my advantage would be much smaller than Petri’s in relation to the other strong candidates.
In 2005, friend Alexandre Prata Maluf, a member of Sigma V, Pars Society and OlympIQ Society, estimated that my IQ should be similar or slightly above that of Marilyn Vos Savant. I think he meant it as a compliment, because Marilyn is an icon in high-IQ societies, but I didn’t like the comparison, because it’s not a fair comparison. The real-world problems I’ve solved are much more difficult than the problems she’s solved. I don’t exclude the possibility that she might have an IQ similar to mine, but she would need to prove it with concrete results, solving problems with a compatible degree of difficulty.
I recently learned that in 2018, in a private group, my name had been mentioned in a post titled “Name the top 5 people (alive) with the highest measured IQs in the world today! Name, IQ and Test.” I found it surprising that I was quoted, because since 2006 I had been away from high IQ societies and only returned a few months ago, in February 2022, yet Rasmus Waldna from Sweden very kindly remembered me and suggested my name, and his nomination received more likes than the names of Terence Tao, Chris Hirata, Rick Rosner, Marilyn and Langan. The names of friends Tor and Iakovos were also indicated. I understand that it was an informal topic, and people’s positive reactions may have been influenced by factors extrinsic to intellectual capacity, some people may have liked it out of sympathy, for example, or because they like my hair, but I was still happy with the memory and recognition, and also happy to see some friends on this list.
In 2001, David Spencer compared me to Leonardo Da Vinci and Pascal. In 2016 my friend Joao Antonio LJ compared me to Newton and Galileo, and the way he wrote and the context in which it was said, I found it a touching and sincere compliment. In 2017, I was again compared to Leonardo (by Aurius). In 2020, Empiricus magazine published an article by Bruno Mérola on risk management, in which the author compared my Melao Index with the Sharpe index (1990 Nobel), and in the analysis he did, he presented facts and arguments demonstrating that my index is higher than the Sharpe index. In fact, my index is also superior to that of Modigliani (Nobel 1985), Sortino and all the others, but in the article he only mentioned the Sharpe index because it is the most used in the world, because it is more traditional and better known, and cited mine for being the most efficient. In 2021 I was compared to Feynman and again to Leonardo, in an interesting situation, where the person (Francisco) did a reasonably detailed analysis of the comparison to justify his opinion. In 2021, I was again cited as possibly the smartest person in Brazil by Luca Fujii, one of the greatest precocious talents in Brazilian Mathematics, but as he is still very young, he has not yet manifested all his intellectual brilliance and that is why he is not yet so famous, but it will be soon. Luca is a person with many moral virtues, as well as intellectual ones, just like Joao Antonio LJ, so I feel really honored that these people have high opinions about me, and also because I know they don’t say that just to please me, but based on deep criteria, very well-founded and well-considered criteria. Joao has read over 1000 of my articles, Luca has read my two books and has surely read hundreds of my articles. So, in addition to being exceptionally skilled, they were also knowledgeable about what they were talking about.
Anyway, I think the real world problems I’ve solved, the people who have tried to solve the same problems and the awards these people have won and other problems they’ve solved, the opinions of some exponents of high IQ societies about me maybe answer a little about my IQ, certainly more and better than a standardized test could tell.
Jacobsen: What ethical philosophy makes any sense, even the most viable sense to you?
Melão Jr.: I know of no author who represents my views on any subject sufficiently accurately and completely. There are always details where disagreements occur. In my book on the existence of God, one of the chapters deals with Ethics, in which I set out my views on this. There are some articles in which I discuss issues related to Ethics, this is one of them: https://www.saturnov.org/liberdadeedireitos
Jacobsen: What political philosophy makes any sense, even the most viable sense to you?
Melão Jr.: There is a Polish proverb that says “In capitalism, man betrays man. In socialism, the opposite occurs. In theory, almost all political systems try to be reasonably good, with different priorities, but each aiming, in its own way, at noble and lofty goals, although utopian and superficial in basic points, so when they are implemented in practice, it becomes clear that human vicissitudes corrupt any system, because theoretical systems do not make adequate predictions about how to deal with real humans. I believe that in the not too distant future, if we do not destroy each other by war, the political leadership of the planet will be “in the hands” of intelligent machines, and there will be a system much more logical and fair than any system that currently exists. It will be far from a perfect system, but it will be vastly superior to anything we know of, as these systems will be able to analyze much more complex and profound interactions of human relationships between large groups and how those relationships evolve over the long term in much the same way. that the best chess programs far surpass the quality of analysis of humans, “seeing” much more accurately and deeper and making more accurate predictions than any human. The problem is that there is a high risk that we will be enslaved by machines, or something, or there will be a symbiotic union between humans and machines, or parasitic, it is difficult to predict, it will depend on some decisions we make in the coming years and decades.
Jacobsen: What metaphysics makes any sense to you, even the most viable sense to you?
Melão Jr.: The theory of the multiverse is on the threshold between Physics and Metaphysics. The word “multiverse” is an inadequate construction, but the meaning is plausible and even probable.
Jacobsen: What comprehensive philosophical system of worldview makes any sense, even the most viable sense to you?
Melão Jr.: What I describe in the book I cited above, in which I present arguments that seem conclusive about the existence of God, and I address other philosophical and scientific topics.
Jacobsen: What gives you meaning in life?
Melão Jr.: I don’t think there needs to be something that gives meaning to life beyond itself. Life has an intrinsic meaning. But I can say that protecting my mother and providing the best possible for her was something that gave me joy. She passed away in 2016. I didn’t eat properly and didn’t sleep properly for a few months. I had already researched cryogenics and knew that this technology does not offer realistic prospects of bringing a person back to life, because the membranes of trillions of cells are ruptured in heat shock, leaving the cytoplasm to leak out, a process that is unlikely to be reversed. I started to think of a way to resuscitate her, but I find it very difficult that the resurrected person could have restored the exact same personality and memories, so it wouldn’t be the same person. If her memories and personality had been stored entirely on an HDD or SSD, or some device with similar properties, then perhaps it would be possible to restore the same person, in a genuine process of resuscitation. The joy of living was gone with her death. In 2018 I met my girlfriend Tamara who has been living with me ever since and I can say she has been my joy of living, my life would be very small and discolored if it wasn’t for her. It is an honor for the human species that there are people deeply committed to doing what is right and fair, like her, who elevate human dignity to a level close to perfection.
Jacobsen: Is meaning externally derived, internally generated, both, or something else?
Melão Jr.: In deduction the meaning is attributed, ultimately, arbitrarily. One determines what a triangle is and that will be a triangle. In finite induction, meaning is inferred from the analysis of the amplitude of variation of properties observed in entities of the same class compared to the dispersion of the same properties observed in entities of different classes.
The evolution of the concept of “planet”, for example, illustrates well how this happens. The Greeks classified the Moon, Sun, Mercury, Venus, Mars, Jupiter and Saturn as planets. Not all Greeks, actually. Aristarchus, Seleucus, Ecphantus (assuming that Ecphantus actually existed) and Philolaus did not adopt the same criteria. With Copernicus, the Sun was no longer considered a planet, while the Earth was classified as a planet, because the criterion of the Greeks was that the planets moved. When Uranus was discovered in 1781, it also came to be classified as a planet, because its general properties fit this class of objects better, and the same happened when Ceres was discovered in 1801. However, shortly afterward, Pallas was discovered, Vesta, Juno and other objects with orbits very similar to those of Ceres, all much smaller than the other planets and sharing almost the same orbit. Within a few years there were more than 10 objects with these characteristics , which led to reconsidering whether the criteria used to classify planets were appropriate. Then came the concept of “planetoid” later modified to “asteroid” to include this class of objects. At the time Pluto (1930) was discovered, as it was far outside the asteroid zone and its size was originally estimated to be similar to that of Earth, it was classified as a planet. In a few years it was found to be much smaller than previously thought. The first estimates from 1931 assigned Pluto 13,100 km in diameter, then 6084.8 km, then 5760 km, then 3000 km, 2700 km, 2548 km, 2300 km, 2390 km and the latest data indicate about 2376.6 km . So, at the time it was discovered, it was plausible that it was classified as a “planet”, but when it was found that it was much smaller and less massive, the situation changed. This issue is discussed in more detail in my book on the subject. When other trans-Neptunian objects were discovered, it started to be considered that perhaps Pluto would be better classified as one of those objects, rather than being considered a planet. The terrestrial planets (Mercury, Venus, Earth and Mars) had a rocky surface, average density approximately between 4 and 5.5 times that of water, diameter approximately between 5,000 and 13,000 km, while Jovian planets (Jupiter, Saturn, Uranus, Neptune) they had a fluid “surface”, average density approximately between 0.7 and 1.7 times that of water, diameter approximately between 50,000 and 140,000 km. But Pluto was far outside these two groups, its density 1.9 was similar to that of the Jovians, but its size was smaller than that of the tellurics. It was not known if the surface was rocky, but in principle it was believed that it was. When Eris was discovered – whose mass is similar to Pluto and maybe a little larger – they finally decided to promote a debate about it and reconsider the criteria for classifying planets. In 2006, the IAU decided to create a new class of objects, the “dwarf planets”, and Pluto entered that category.
I skipped some important events, such as Galileo and Simons’ discovery of the 4 large satellites of Jupiter, which were initially considered “planets” because the concept of a “satellite” didn’t exist until Kepler suggested it. Galileo sometimes referred to these objects as “small stars”, as it was not really known what stars were, although Giordano Bruno already had a promising hunch.
The meaning of “planet” was and continues to be determined by comparison with other objects that show different levels of similarity. In cases where there are large numbers of objects to compare, such as the taxonomy of animals, classifications can be made at many hierarchical levels, with different levels of similarity, and meanings are assigned according to properties common to all elements. of the same class, while trying to select criteria that allow distinguishing from elements of other classes. In classifications of dogs and cats, for example, it is not useful to consider the fact that they have 2 eyes, a tail and a snout, because this does not help to distinguish one species from the other. Average size would help if the size spread were narrower, but as different dog breeds vary over a very wide range, this criterion wouldn’t help much either. In these cases, more subtle and specific criteria, such as facial morphology, tooth morphology and number of teeth, turn out to be more useful. The size of the snout can help, but the number of teeth has a similar meaning, as it is related to the size of the snout, with the advantage of being more objective and quantitative.
Anyway, these are the two main ways of determining meanings. One is arbitrary, it allows one to impose what characteristics the entity must have. The other tries to discover which characteristics are common to all entities of the same class and, at the same time, are different from the characteristics of entities of similar classes, in order to make it possible to distinguish between entities of one class or another. These meanings are often incomplete, uncertain and subject to revision as new discoveries are made about other entities whose characteristics are borderline in a given class, leading to broadening, narrowing or reconfiguring the criteria to include or exclude the new entity in one of the classes. known, or, more rarely, create a new class inaugurated by that entity.
Jacobsen: Do you believe in life after death? If yes, why and in what way? If not, why not?
Melão Jr.: The concept of “death” is a disconnection, which for now we don’t know how to reconnect, but soon it will be possible in different ways. This is one of the topics analyzed in more detail in my book. The concept of “soul” also needs to be examined in detail to answer this, and the size of the answer would be immense.
Jacobsen: What do you think of the mystery and transience of life?
Melão Jr.: I don’t think it’s transitory. It has been for now, but that should soon change.
Jacobsen: What is love to you?
Melão Jr.: It is a desperate attempt to invent a word to represent an indescribable feeling.
Appendix: Educational System in Brazil and Richard Lynn’s study on IQs in different countries
The education system is usually bad all over the world, but in Brazil it is much worse than the average of countries with similar GDPs. I estimate that Brazilian education is one of the worst in the world. University of Ulster Professor Emeritus Richard Lynn offers a simplistic explanation for this in his article “IQ and Wealth of Nations”. It does not deal with Education. It deals with Economics, but the argument he uses to justify differences in income would be equally (and better) applied to Education, as long as the argument is valid. But the argument starts from a false premise. There are many errors in Lynn’s work. The central idea he defends is right, but quantitatively he forces exaggerated results. The thesis he defends – that there are ethnic and regional differences – is correct, but the differences are not as big as he wants to make it out to be. According to Lynn, the average IQ in Equatorial Guinea is 56. If this were right, the country would be expected to be a large tribe of nomads, they would not have mastered the technique of producing fire, they would not have built plows, spears, etc. But there is an urban civilization there. In addition, people with an IQ below 60 have a hard time learning to read and write, even though they live in countries with extensive infrastructure and literacy incentives. If more than 91% of the population of Equatorial Guinea can read (assuming this information is not made up), even in an environment with less incentive to learn, it would be very difficult to explain how this population with an average IQ of 56 is predominantly literate. Lynn tries to spread his neo-Nazi beliefs and uses this scientific research to try to gain credibility for his views. The average IQ of Ashkenazi Jews is around 114, the highest average in the world, but Lynn was able to manipulate the data from her meta-analysis so that the average IQ for the state of Israel was 94.
In the case of Brazil, Lynn’s results indicated an average IQ of 87 and, in a more recent review, they indicate 83.38. If this were correct, it would be a good explanation for the low quality of Brazilian scientific production and the terrible quality of teaching. But the real problems that predominate in Brazil are a combination of student laziness, teacher laziness, low leveling in classes and bad “pedagogical” methodology.
A more serious analysis of the situation shows that the average Brazilian’s real IQ is not as low as Lynn’s studies suggest. Many people turn in IQ quizzes without answering, or they “guess” all the alternatives, or they answer some and “kick” the others.
In a post of mine on the profile of our friend Iakovos Koukas, I made a reasonably detailed comment about this, which I also reproduced in the IQ Olympiad group and reproduced here again:

There are indeed cognitive differences based on ethnicity, just as there are in relation to average height, average penis size, average concentration of melanin under the skin, etc., but the cognitive differences are much smaller than what he tries to “sell”.
On the one hand, there is the problem of naive egalism, defended by some pseudo-ideological groups, and this finds no support in the facts. At the opposite extreme, there are groups of people like Richard Lynn, Tatu Vanhanen and Charles Murray who try to exacerbate racial differences and use them to justify the misery of some peoples. Both the radical eugenicists and the radical egalitarians are wrong, but between one extreme and the other there are some truths.
Just as there are marked cognitive differences between species, there are differences between ethnicities, but less marked because the range of genetic variation within the same species is smaller. Pretending that these differences do not exist is a mistake, because the correct knowledge about the particularities of each ethnicity helps to make more accurate diagnoses of several diseases whose symptoms are not the same in all ethnic groups, the adequate time of exposure to the Sun for the synthesis of vitamin D is not the same, and many characteristics that would be interpreted as “healthy” in some ethnicities are not in others, so the correct use of this information helps to more effectively interpret the results of blood counts, analyze bone, dermatological and other anomalies. muscle. Knowing the physiological, cognitive and behavioral differences of each ethnicity is important; the problem is to use these differences for the purpose of tyrannizing, oppressing or diminishing the merits of a people, this is unethical and unscientific, and Lynn ostensibly tries to do this.
In the case of Brazil, there seems to be a distortion close to 10 to 15 points in the numbers presented by Lynn, so the correct average Brazilian IQ should be around 95, a little below average, but not so much as to justify the bad results. of Brazil in Science. The real problems seem to be laziness and other items I mentioned above. There are recent studies that question whether apparently lazy behavior should be classified exactly as “laziness” or not, but I won’t go into that discussion either so as not to make this text even longer.
In the 1950s and 1960s, Richard Feynman was in Brazil a few times and made severe criticisms of the Brazilian education system, he did some impromptu social experiments and showed that Brazilian doctoral students often did not understand the basics of what they were doing, they acted mechanically , without the slightest idea about the fundamentals. Brazilians wrote some nice words in relation to Feynman’s criticism, saying that they intended to improve something, but the current situation is perhaps even worse than it was when Feynman was in our country. In addition to the shameful situation of education in Brazil, there are still other problems in this episode, because Brazilian “educators” showed surprise and perplexity with the problems pointed out by Feynman, as if they were in a house on fire, but they were not seeing that the fire was devouring. everything, until a neighbor comes in and shows them the fire. So they thank you, look shocked, make a speech of mea culpa, but do nothing concrete about the fire, which is still devastating … It ‘s unbelievable that they weren’t seeing the fire before the neighbor pointed it out to them and unbelievable that they continue without taking any action after the problem was pointed out.
Although scientists and educators have not mobilized to try to solve the problem, some Brazilian exponents of Mathematics, who had some experiences in Europe and the United States, decided to try to reproduce a small oasis, bringing to Brazil some of what they had experienced in developed countries. In 1952, IMPA (Institute of Pure and Applied Mathematics) was founded. At that time, Brazil was in Group I of the IMU (International Mathematical Union), the lowest level. For 70 years, IMPA has been the only place in Brazil where there has been a sincere attempt to identify and support some outstanding talent, trying to escape the bureaucracy and inefficiency of the Educational System. But IMPA is only 1 institution located in Rio de Janeiro. Brazil is a large country, with 8,500,000 km^2, so people who live far from RJ are often unable to enjoy what IMPA offers. Therefore, IMPA’s reach is still small. With the popularization of the Internet, this has improved, but the number of beneficiaries is still very limited, including because there is relatively little publicity about IMPA events, most schools do not enroll their students in OBM (Brazilian Mathematics Olympiad), most of the students do not even know that OBM exists. There are some professors spread across Brazil linked to IMPA, who try to contribute to the identification of talents, but it is a difficult process, they do not receive incentives from the government or companies. Even with these obstacles, between 1952 and 2015 IMPA raised Brazil from Group 1 to Group 5 (the highest), which only 11 countries are part of: Germany, Brazil, Canada, China, USA, France, Israel, Italy , Japan, UK and Russia.
I don’t know what the criteria for being included in Group 5 of the UMC are, but I suppose it’s a combination of merit and politics, perhaps more merit than politics. I say that there is a bit of politics because there are countries with two Fields medals or two Abel awards, but they are not part of this group, such as Australia, Belgium, Iran and Sweden, while Brazil has only 1 Fields medal. Of course, these awards should not be the only criterion, but they are very reasonable indications of the cream of mathematics produced in each country. There are also several countries with 1 Fields medal and a longer mathematical tradition, which are also not in Group 5. Perhaps the criterion takes into account the pace of growth, and in this regard Brazil is perhaps, along with China and India, one of the fastest growing in the production of high-level Mathematics.
The fact is that if the average Brazilian IQ were really as low as Richard Lynn claims, and the main problem in Brazil was really the low average IQ of the population, then IMPA actions would not have been able to substantially modify the quality and quantity. of high-level mathematical production. If the problem were low IQ, the solution would come from other actions, such as nutritional improvements, for example. IMPA actions did not change the average IQ of the population; they only changed the efficiency in the identification of talents that already existed in the country, and after the identification, opportunities and incentives began to be offered to these talents.
The numbers pointed out by Lynn, that the average Brazilian IQ would be 87, are inconsistent with the results achieved by IMPA. Even with a population of 213 million, it would be difficult for some of these people to reach the world top with rarity close to 1 in 300 million if Brazil was 1 standard deviation below the average, even because IMPA cannot extend its benefits to more than 1% to 5% of the most talented population. Of course, other hypotheses would apply, such as a higher standard deviation in the IQ distribution among the Brazilian population or a more platykurtic distribution. But generally what you see in groups with a smaller mean height is a narrower rather than a wider standard deviation. This happens with virtually all variables. The standard deviation in diameter for larger screws is wider than for smaller screws. In other words, the percentage standard deviation is usually maintained, so it would be strange for a population with a lower IQ to have a higher standard deviation. Furthermore, it would be an ad hoc adjustment to try to salvage a theory that has other problems, making it more plausible to pass Occam’s razor and accept that Lynn is wrong about this. The average Brazilian’s correct IQ is substantially higher than he says, just like the IQs of most other non-Aryan peoples he tries to push down are also higher than the numbers he presents.
Examining the facts objectively, what the data suggests is that the average Brazilian IQ is probably much closer to 95 than to 87. A little below average, but not as low as Lynn suggests.
The IMPA results also show that perhaps laziness is a reflection of the poor education system. If laziness were a widespread problem in the country, the solutions implemented by IMPA would not have been enough to solve it either; other complementary measures would be necessary. Perhaps laziness is a striking problem that affects more than 99% of the population, but about 1% could not be labeled as “lazy”, but as a victim of a very bad education system. As more than 99% of intellectual production comes from that 1%, we have a huge problem there, and a complete lack of attention to this problem, because politicians are not very concerned about making great efforts to win 1% of votes, since with less effort they can get more votes by pretending to please a less demanding, easier to deceive and much more numerous audience.
One of the big problems is that the 99% of the population are also harmed, but they don’t see this themselves and don’t demand from the government measures that can contribute to long-term improvements, measures that are good and fair for all. Each just wants the government to adopt measures with immediate results that benefit their own navels. In this way, the problem tends to perpetuate itself, as it has for decades.
Many Brazilian academics often complain about the lack of funds and attribute the low scientific production to this. Others do worse, pretending that there is good quality scientific production in Brazil, despite the lack of funds. But what the concrete facts show is that really very poor countries, in which most of the population lives in poverty, such as Ethiopia, Nigeria, Congo, Kenya, Ghana, etc. had citizens Nobel laureates, while in Brazil there has never been a Nobel laureate. Furthermore, when Einstein developed his major works, for which he deserved 3 Nobel prizes (and 2 more for later works), he was not receiving any funding for his research, not even in previous years. Therefore, although the lack of resources imposes severe limitations, it cannot be considered an absolute impediment, much less be used as a pretext in a situation like this. Great works were carried out practically without money, as was much of Newton’s work during 1665.
[Here, perhaps, a small caveat fits, because as I mentioned in the part about awards and merits, it is possible that some Brazilians have performed works with merit to receive a Nobel, but were not laureates for political, bureaucratic reasons, etc. My work on Econometrics and Risk Management, for example, is more expressive than most of the work of Nobel laureates in Economics in recent decades. The discovery of the π meson, although predominantly an operational work, had a Brazilian as the protagonist (César Lattes), but as the team leader was Celil Powell, Lattes only had a B.Sc. and at the time (1950) the award was only given to the head of the team, Lattes ended up not receiving the award, although he was perhaps primarily responsible for this work and was the main author of the article. After the detection of π mesons in cosmic rays (1947), Lattes was one of the few in the world with the necessary knowledge to identify the signatures left by these particles on the emulsion plates, so he was invited to collaborate at CERN (1948) and verify if they were also able to produce π mesons, as the energy needed for this was easily exceeded by the particle accelerator used, so they were probably already producing pions for a long time (since 1946), but they didn’t know exactly what to look for in the chambers bubble as being signatures of the π mesons. Lattes went to CERN and made the identifications. Again the work was distinguished with the Nobel and again Lattes was excluded from the award. In all, Lattes was nominated 7 times for the Nobel, but was never awarded. Oswaldo Cruz was also nominated for the Nobel Prize in Medicine, but was not awarded. Perhaps Machado de Assis would also have merit for a Nobel Prize in Literature. So, although there are 0 Brazilian Nobel laureates, maybe some have merit for that. There is a detailed text in which I analyze the case of Lattes, without the usual exaggerations and nationalist distortions of most articles about him, but at the same time acknowledging the merits he had that were not properly recognized.]
On the one hand, the low scientific production reflects the lack of funds, on the other hand, the lack of funds reflects the low scientific production, because if there really was scientific and technological production of good quality, large national and international companies would be interested in funding this research. , as they would profit from it. If private companies do not invest in Brazilian science, it is because such “investment” does not generate an expectation of profit, because the level of production is below what could justify some serious interest from entrepreneurs. I usually use the term “donation” for Brazilian science instead of “Investment”, because the meaning of “investment” is different. What Brazilian researchers demand is basically this: donation.
It is important to make it clear that I am not against funding Brazilian science, whether in the form of investment or donation. If I were against it, it would be stupid. I am against the bad management of the budget allocated to Science, combined with the terrible educational system and the complete lack of incentive for intellectual production. Intellectual production is not writing 50,000 useless papers to pretend that it is being produced and continue “sucking” on the grants of “research” funding agencies. Real intellectual production is serious effort to solve real and important problems. Therefore, instead of whining about lack of funds, the correct procedure would be a complete reformulation of the clowning that takes place in Brazilian Education and in Brazilian “scientific” research, they would need to start producing real, with high quality, as happens at IMPA , and then present substantial facts and consistent arguments to claim investments. Without it, the tearful speech to ask for donation is fragile. Certainly a crowd of unproductive researchers will stone me for this comment, but the few serious researchers will agree with me, although they may not have the courage to publicly acknowledge the position they defend, lest they be lynched by their colleagues.
Perhaps there are less than 1% of serious researchers in Brazil, among which I had the opportunity to meet some, such as Renato P. dos Santos, Roberto Venegeroles, André Gambaro, José Paulo Dieguez, Luis Anunciação, Antonio Piza, André Asevedo Nepomuceno, Herbert Kimura, Cristóvão Jacques, George Matsas, Doris Fontes among others. But unfortunately they represent a small fraction, and they do not always openly admit the disastrous situation in which Brazilian science finds itself, because the pressure is great for them to pretend to believe in the staging of which most of the others are part. When the person takes a fair position on this and tells forbidden truths, he begins to be cowardly boycotted on all sides, so it is understandable that many prefer to remain silent, avoiding manifesting, or simply pretending to agree with the fantasy. that try to propagate the situation of Science and Education in Brazil. Many criticized Copernicus because of the preface to his book Revolutionibus, for not having faced the dominant beliefs openly, but when analyzing the problems faced by Galileo, it is clear that the defense of the truth that goes against the interests of certain groups can be very onerous . And it would be naive to believe that the entities that dominate the world today (media, companies, universities, politicians, etc.) are more scrupulous than the medieval ecclesiastics were. There are certainly some entities that are more reputable and more sincerely committed to defending what is right and fair, but they are exceptions, unfortunately. “Ironically” the same people who are outraged by the persecution of Galileo are the people who today practice the same type of abuse, injustice and persecution.
This is a delicate situation, because if the immense majority builds a hoax and pretends that it is real, it becomes difficult for a small minority to restore the truth. For example: Roberto de Andrade Martins is a serious researcher, with post-docs in Cambridge and Oxford, with good knowledge and good understanding of Physics, Logic and Epistemology. He is completely rejected by his colleagues and by those who call themselves “scientific” disseminators, because Roberto tells undesirable truths. Roberto has never been invited to the major channels of scientific dissemination in Brazil, although he is by far more qualified than the overwhelming majority of those invited to these channels. This happens because in these channels, the most “commercial”, more “charismatic” figures are preferred in the eyes of those who pretend to be interested in Science, instead of serious scientists who tell forbidden truths about the tragic reality of science in the country and education in the country. country. YouTubers who call themselves “scientific promoters” in Brazil have to choose between truth and popularity, and almost always prefer the second option. In this way, they are dragging a farce that at some point will cause the country’s collapse, as happened with the former USSR in 1991, or with the Lehman Brothers bank in 2008. They were sweeping the dirt under the rug, until a point where the situation became untenable and the shack collapsed. There are a few serious scientific disseminators in Brazil, but these generally reach a much smaller, more enlightened audience that already sees the problem without it being necessary for someone to show them. The public that would really need to be informed remains “armored”, to serve no one’s interests, since no one will profit from the sinking of the nation. Chomsky once declared that “the purpose of the media is not to report what happens, but to shape public opinion in accordance with the will of the dominant corporate power.” In this case it is worse, because they are not shaping public opinion according to anyone’s will. They are just acting stupidly for everyone’s harm.
Hypocrisy is another terrible problem that affects a large number of Brazilian academics and pseudo science disseminators. When a foreigner comes to Brazil and says that Brazilian science is a joke, as Feynman did, he stomps and spits on Brazilian science, Brazilian academics certainly don’t like it, they are embarrassed, but even so they applaud the alpha male, like sycophantic primates. But when another Brazilian points out the same problem, they growl and rant at the heretic and try to keep him from talking about it.
There are a few more complications that cannot be overlooked: most cutting-edge science has no immediate application and can take decades or centuries to produce any return for the investor. The director of the Department of Mathematical Physics at USP, Ph.D. from MIT and Post Doctoral from MIT, Antonio Fernando Ribeiro de Toledo Piza, who in 1994 wanted to meet me in order to talk to me about a work I developed at age 19, about a method for calculating fractional factorials, in the middle of the conversation he mentioned an occasion in which Faraday was asked what the discoveries he had made about electricity and magnetism were for. Faraday responded with another question: “What good is a child who has just been born?” This phrase expresses a complex problem in the treatment of science as an “investment”, because the current human life expectancy is too short for some investments in science to be seen as attractive to private investors. These are investments that will only bring a return in 50 years, 100 years or more, for the following generations, for our children, grandchildren, great-grandchildren, it is a tree that we will have the cost and work of planting, fertilizing, cultivating, protecting, but they are our grandchildren who will reap the rewards. For this reason, even in countries where science is prolific, it may not be attractive to private investors, whose time horizon for which they are willing to wait for results is usually shorter.
Having made this important caveat, it is necessary to emphasize that this discourse would be fallacious if used to try to save the terrible reputation of Brazilian science. What is produced in Brazil can rarely even be called “Science”. Data tabulation and descriptive reports are made about the task. To use Faraday’s argument I cited her above, in defense of investment in Science, it would first be necessary for Brazil to start producing real Science.
Real science involves innovation, paradigm shift, real improvement, critical, in-depth analysis that goes beyond the obvious and adds some new and useful knowledge to the legacy of humanity. In Brazil this is rarely done. In fact, this is rarely done in the world, but the level of scarcity of innovations is worse in Brazil than in other countries with a similar economic situation or with a similar HDI.
When I say “paradigm break” it doesn’t have to be something as grandiose as a new cosmological system or a unification theory. It could be something basic, like adding a little boron to photographic emulsion plates to preserve the records of π mesons all the way down from the mountains, as César Lattes did, or solving a homomorphic encryption problem that was open for 15 years, as he did Joao Antonio LJ, or develop a new educational system that allows teaching 1-year content in 40 days to a child who had below-average grades and after those 40 days the child starts to have the best grades in school, as Tamara PC did Rodrigues, or revise the BMI formula, as I did. They are small contributions, but they reveal scientific facts still unknown, or correct knowledge that has been incorrectly repeated for a long time, or in some way contribute to broadening the horizons of knowledge or to redirecting knowledge to a path closer to the truth. It is not a complete deconstruction and reconstruction of knowledge, as Newton did, but it is a brick added to the right place, or removed from the wrong place and repositioned in the right place. This is the minimum that would be expected of a scientist, but most of the time this minimum is not met, and Ph.D. they are distributed almost like a ritual, in which the candidate only has to show that he knows how to write and knows how to interpret a little of what is on some graphs – with several misinterpretations, by the way. Depending on the discipline, it is enough to show that you can write, you don’t even need to know how to read a chart. After performing the ritual, the person receives the Ph.D. label. and begins to receive money to continue with this nonsense, pretending to be producing Science.
The vast majority of doctoral theses and scientific articles do not present anything innovative. These titles are awarded to inflate egos and satisfy people’s vanity, but they are not associated with any intellectual merit or original scientific production. A person does elementary research, purely mechanical, to corroborate some results on which there are already hundreds of other similar studies, and receives a Ph.D. therefore, and the State pays these people to pretend that they are producing something relevant and they call it “Brazilian science”, but the correct name, at best, would be “data tabulation” and “descriptive reports”. I say “at best” because there are usually several blunders in these procedures, which makes the situation even more vexing.
The central problem is that there is no culture of producing innovations. It just repeats itself endlessly. There is no incentive for innovation, there is no charge for innovation, no reward for innovation and, worst of all, there are even penalties for innovation. In 1998, a friend (Patrícia EC), who was completing her doctorate at USP, found that some experimental data on dwarf galaxy morphology was inconsistent with expectations. Instead of her advisor helping her try to understand what could be causing it, he told her to redo the measurements because she must have made a mistake in the measurements or calculations. Up to this point, I agree with him, because these mistakes are often the most common. She redid and obtained results statistically equivalent to the first measurements. At this point the yellow alert turns red and her advisor should have paid more attention to the case. However, he told her to redo it again! This is complete nonsense. It’s unscientific. It is to destroy “evidence” that could contribute to expanding, revising, improving what was known until then. This is the level at which the so-called “Brazilian science” sect finds itself. If any discovery is contrary to established dogmas, it needs to be adjusted in some way until it conforms to the dogmas. In addition to the fact that there are no incentives for discoveries, when there is any indication that something new may be ahead, we try to erase the traces of the possible discovery! People are trained not to produce, not to innovate, not to discover!
Part of the education problem in the country is not the fault of teachers, students and researchers. They just dance to the music. But a big part of the problem is their fault, because they determine the music that should play. In addition, they can refuse to dance to the music, they can put on headphones with better music, and they can create their own center of excellence, as in the case of IMPA.
The academic community’s resistance to admitting these facts exacerbates the situation, because instead of trying to fix the problems, they pretend the problems don’t exist, sweep the dirt under the rug, and move on as if everything is fine. Recently, the president of Brazil made a brutal cut in funds destined for “science”. It is a delicate situation, because the problem of scientific unproductivity is not resolved in this way. The budget cut only exacerbates the situation. It is bad to allocate money to a sector that does not generate satisfactory results, but being a fundamental sector, the correct procedure is to restore that sector and ensure that it works as it should, instead of killing it, taking away its bread and water. It would need to exchange bread and water for a richer diet, increase investment in science and simultaneously reformulate the criteria for granting scholarships, granting funds, reducing the bureaucracy of importing books and scientific and technological products, promoting exchanges with qualified researchers, creating prizes for real merit related to excellence in the original production of relevant works, rather than the political front awards, among many other changes from basic education to the titles of professors emeritus.
In the 1970s, China, India and Thailand were much poorer and less developed countries than Brazil, but they made massive investments in identifying talented children and offered differentiated conditions to encourage these children. Thailand stopped the project. China and India did. In less than two decades, they began to reap the rewards, after one generation, these children became highly skilled teachers, who provided the next generation with an even more exquisite education, and today China is on its way to becoming the greatest economic power, cultural, scientific and technological world, and India follows closely. There was a serious and profound overhaul of the education system so that they could get to where they are now. Instead of pretending they were doing science, they admitted the unproductiveness and low quality of what they produced, and started to fix what was wrong. One of the great problems in Brazil is precisely this inability to admit mistakes.
Portuguese Version
Entrevista para Scott Douglas Jacobsen
Preâmbulo:
Em primeiro lugar eu quero agradecer à minha namorada Tamara, pela paciência de ler esse texto e me ajudar a cortar longos trechos desnecessários, a Tor pela gentileza de me indicar para essa entrevista e a você (Scott) por aceitar essa indicação e por sua amável ajuda com a revisão da tradução.
Na medida do possível, procurei sintetizar e simplificar, mas sempre que foi necessário decidir entre a resposta mais curta e a mais correta, optei por aquela que me parecia a mais correta. Como resultado, acabei me estendendo mais do que gostaria e ramificando algumas respostas por detalhes que aparentemente perdem o vínculo com a pergunta, mas que, na verdade, estão indiretamente conectados por dois, três ou mais nós, de modo que se esses trechos fossem removidos, ficariam lacunas que comprometeriam a coerência.
Antes de apresentar as respostas é necessário fazer alguns esclarecimentos importantes: quando a pergunta é simples, basta dar uma resposta curta para que a interpretação seja unívoca, mas para questões complexas, antes de responder é necessário conceituar alguns dos termos utilizados, para minimizar as diferenças entre a mensagem a ser transmitida e a interpretação que dela será feita. Uma questão do tipo “Por que, no Xadrez, nem todos os Peões dobrados são debilidades?” Não há como responder de modo a proporcionar uma ideia correta em apenas 1 ou 2 parágrafos, nem mesmo se a resposta fosse simplificada e resumida. Para tentar proporcionar uma ideia razoavelmente correta e completa, são necessárias pelo menos 20 páginas, com vários exemplos comentados. Nessa entrevista, algumas perguntas envolvem situações semelhantes.
Esse tipo de dificuldade é inerente a qualquer pergunta envolvendo QI, porque o conceito atualmente disseminado apresenta algumas falhas que precisam ser devidamente revisadas, e algumas dessas revisões não são triviais, exigindo um volume considerável de esclarecimentos preliminares para garantir que a interpretação da resposta seja suficientemente acurada e fidedigna.
Fora das sociedades de alto QI é comum que façam confusão entre escalas com desvios padrão diferentes. O escore 1579 de James Woods no SAT é frequentemente convertido em 180, enquanto o escore 1590 de Bill Gates é convertido em 154 (às vezes 160), e ambos aparecem na mesma lista como se o QI de Woods fosse maior que o de Gates, embora seja o contrário. Esse tipo de erro primário foi praticamente erradicado nas sociedades de alto QI, mas ainda há erros sistemáticos sendo repetidos ostensivamente, alguns dos quais são grandes e graves. Esses erros provocam muitas confusões e dificultam a correta interpretação de questões fundamentais. Eu não me refiro a erros individuais, cometidos por algumas pessoas, mas sim a erros “institucionalizados”, universalmente aceitos como se fossem corretos e cometidos por praticamente todas as pessoas.
Em 2000, resolvi um problema central da Psicometria que vinha se arrastando desde os anos 1950, quando Thurstone e Gardner perceberam a importância de padronizar testes cognitivos de modo a produzir escores em escala de proporção. Bob Seitz, da Mega Society, referiu-se a esse problema como “O Santo Graal da Psicometria”. Depois de investigar esse problema e resolvê-lo, publiquei um artigo descrevendo meu método e mostrando como os testes deveriam ser normatizados. Também revisei as normas do Mega Test e Titan Test utilizando esse método. Em 2003, apliquei o mesmo método ao Sigma Test e publiquei outro artigo, mais detalhado, descrevendo passo-a-passo todo o processo de normatização e explicando os motivos pelos quais esse procedimento é superior aos métodos utilizados. Entre os problemas crônicos que são solucionados de forma natural com a aplicação desse método, um dos mais importantes é a correção nos cálculos dos percentis e dos níveis de raridade. Esse é um erro sistemático que vem sendo cometido desde 1905. Comentarei essa questão com um pouco mais de detalhes ao responder a questões que tratam desse tema.
Há dois outros erros que são cometidos sistematicamente, embora as soluções para eles já sejam conhecidas, mas não são aplicadas, em parte porque esses problemas não são bem compreendidos: o problema de validade de constructo e o problema da adequação do nível de dificuldade das questões ao nível de inteligência que se pretende medir. De certo modo, esses problemas estão conectados, porque geralmente os testes apresentam boa validade de constructo para determinado intervalo de níveis de habilidade, mas não para todo o intervalo no qual o teste pretende medir, assim os resultados acabam se mostrando razoavelmente acurados e fidedignos para pessoas cujos escores estejam dentro do intervalo de validade, mas começam a apresentar sérias distorções fora desse intervalo. Um exemplo clássico para ilustrar esse problema é o Stanford-Binet V. Os processos cognitivos exigidos para solucionar as questões do SBV podem ser apropriados para medir corretamente a inteligência no intervalo de 60 a 140, mas começam a se mostrar menos apropriados entre 140 a 150, por isso os escores acima de 150 já estão representando predominantemente um traço latente que não é o que se pretendia medir. Isso compromete inteira a validade desse tipo de instrumento para a aferição acima de 150, e coloca em dúvida em que medida os escores entre 140 e 150 estão de fato refletindo o nível intelectual.
Para organizar melhor as informações, antes de prosseguir citarei 3 erros importantes que são cometidos sistematicamente pelos psicometristas profissionais e nas sociedades de alto QI:
- A maneira como os testes são padronizados, tanto os testes clínicos quanto os high range IQ tests (hrIQts) – seja pelo uso de Teoria de Resposta ao Item, seja pela Teoria Clássica dos Testes –, produz distorções na escala, e a maneira como os percentis são calculados conduz a resultados muito distantes da realidade. Essa distorção na escala já foi apontada desde os anos 1950, por Thurstone, e já havia sido notada (embora não tivesse sido descrita) pelo próprio Binet em 1905. Um bom método para normatização de testes de inteligência deveria produzir escores numa escala de proporção, mas os escores de QI se apresentam numa escala ordinal (https://www.questionpro.com/blog/nominal-ordinal-interval-ratio/). Além disso, os erros nos cálculos dos níveis de raridade apresentam distorções muito grandes nos escores mais altos, chegando a mais de 3 ordens de grandeza. Isso acontece porque os cálculos partem da hipótese incorreta de que a distribuição dos QIs é gaussiana em toda sua extensão. A morfologia da distribuição é de fato muito semelhante à de uma gaussiana no intervalo -2σ a +2σ, mas começa a degringolar fora desse intervalo. Esse fato não pode ser negligenciado quando se calcula os percentis. Da maneira como os cálculos são feitos atualmente pelos psicometristas e nas comunidades de alto QI, chega-se a resultados muito distantes dos corretos. Por isso, quando se fala em percentil 99,9999% ou QI 176 (σ=16), os significados são muito diferentes, embora sejam usados como se fossem a mesma coisa. A raridade correta para o QI=176 não é 1 em 983.000, mas sim 1 em 24.500. E isso não acontece porque o desvio padrão seja maior. O desvio padrão é o mesmo (16 nesse exemplo), porém a cauda direita é mais densa do que numa distribuição normal, tornando os escores mais altos mais abundantes do que seria esperado se a distribuição fosse exatamente gaussiana. Trata-se de um problema relacionado à morfologia da distribuição verdadeira, que não se ajusta ao modelo teórico de distribuição normal. Na verdade, não se ajusta bem a nenhuma das mais de 100 distribuições testadas, inclusive as mais versáteis, como a distribuição de Weibull com 3 parâmetros.
- Outro problema é que o nível de dificuldade das questões mais difíceis de cada teste não é compatível com o teto nominal do teste. Como consequência, tal teste mostra-se inapropriado para o intervalo de QIs que deveria medir. O teste funciona adequadamente dentro de certo intervalo, no qual contenha questões com dificuldade compatível, mas deixa de funcionar fora desse intervalo. Isso é muito mais grave nos testes clínicos, cujo teto de dificuldade raramente ultrapassa 135 a 140, mas o teto nominal pode chegar a mais de 200 (Stanford-Binet V, por exemplo). Acima de 140, os testes clínicos medem a rapidez para resolver problemas elementares, que não é necessariamente uma métrica apropriada para representar a inteligência nos níveis mais altos. Nos casos de hrIQt, no quesito “dificuldade”, as questões geralmente são apropriadas até cerca de 170 ou 180, mas não muito acima disso. Aqui seria necessário abrir um extenso parêntesis para discutir o significado desses escores, porque até 130 ou um pouco acima, a raridade teórica é quase igual à raridade verdadeira, mas para 140, 150 e acima, a raridade teórica vai se tornando cada vez mais distante da raridade verdadeira. Então quando falamos em 180 de QI (σ=16), não basta informar o desvio padrão. Além disso é necessário informar se estamos falando do escore medido em um teste ou se é um percentil verdadeiro convertido em QI. Se a distribuição dos QIs fosse exatamente gaussiana em todo o seu espectro, então um QI 180 (σ=16) deveria corresponder ao nível de raridade de 1 em 3.500.000, mas a raridade verdadeira de escores 180 fica em torno de 1 em 48.000. Mais adiante, menciono link no qual descrevo como chegar a esse nível de raridade de 1 em 48.000.
- Outro problema está relacionado à validade de constructo, isto é, se aquilo que o teste está medindo é de fato aquilo que se pretende medir. Os melhores testes clínicos (WAIS e SB) são muito bons nesse critério para o intervalo de 70 a 130, porque esse tema tem sido amplamente debatido entre bons psicometristas ao longo de décadas e se conseguiu estabelecer alguns bons critérios para avaliar (ainda que subjetivamente) se os itens estão medindo o que deveriam medir (a inteligência, nesse caso, ou o fator g). Entretanto, fora desse intervalo de 70 a 130, a variável medida vai se tornando cada vez mais destoante daquilo que se pretendia medir. Nos hrIQts o alcance é um pouco maior, chega a cerca de 160, alguns testes chegam 170 ou até 180.
Além desses 3 problemas que são observados em praticamente todos os testes clínicos e todos os hrIQts, há também alguns problemas individuais, que são mais básicos e afetam apenas alguns testes específicos, como norma inflada, erros no gabarito, erros nos enunciados etc. Não tratarei desses, porque já são bastante conhecidos e fáceis de identificar e corrigir.
É importante não confundir a validade de constructo com a adequação do nível de dificuldade. Uma questão muito elementar, com um prazo muito curto para ser resolvida, pode ter dificuldade adequada para medir no nível de raridade 1 em 10 milhões, porque embora seja intrinsecamente fácil, como o prazo é reduzido, acaba se tornando difícil resolver dentro daquele prazo. Em casos assim, a dificuldade pode ser apropriada para medir alguma coisa em níveis muito altos de raridade, mas esse traço latente que está sendo medido não é o que deveria ser medido. Além disso, o fato de um teste ter validade de construto num determinado intervalo não implica que terá necessariamente validade em níveis muito acima ou muito abaixo daquele intervalo. Esse é um dos erros mais comuns, porque ao validar um teste de inteligência para 98% da população, isso não garante que ele continue medindo corretamente a inteligência no nível dos 1% ou 0,1% de escores mais altos. A validação precisa ser cuidadosa em todos os intervalos nos quais se pretende que o teste seja capaz de medir corretamente.
Há também alguns problemas mais sutis. O Raven Standard Progressive Matrices, por exemplo, tem sido utilizado pela Mensa em vários países durante décadas, mas é inadequado para medir corretamente acima de 120, talvez até acima de 115. O motivo é que o teste é constituído por 60 questões, mas apenas 1 ou 2 dessas questões (as mais difíceis) são úteis para discriminar no nível de 133, que é onde a Mensa pretende selecionar. Então é como se fossem utilizadas apenas 2 das 60 questões, e uma amostra com apenas 2 elementos não pode ser considerada válida estatisticamente. Na verdade, o corte em 133 não é determinado exatamente por 1 ou 2 questões, mas estas 2 questões respondem por mais de 90% do poder discriminante do teste nesse nível de corte.
Por essas razões, se há interesse sincero em que perguntas sobre QI recebam respostas representativas da realidade, esses três problemas precisam ser corrigidos:
- Extrapolação infundada da validade de constructo;
- Inadequação da dificuldade dos itens para o nível intelectual que o teste pretende medir;
- Adoção de hipóteses incorretas sobre a forma da distribuição dos escores nos níveis mais altos, com base na forma na região próxima à tendência central.
Além desses, há outros pontos que precisam ser esclarecidos. Há um mito amplamente disseminado de que testes aplicados em clínicas são “melhores” (mais confiáveis, mais acurados, mais fidedignos) do que hrIQts. Em alguns casos, realmente são. Mas não em todos. Para escores abaixo de 130, como os testes supervisionados são normatizados com base em amostras maiores e não-seletas, isso constitui uma vantagem real dos testes clínicos em comparação aos hrIQts. Outra vantagem é que os bons psicometristas conhecem maior número de técnicas estatísticas, por isso na faixa de 70 a 130 geralmente os melhores testes supervisionados produzem escores mais fidedignos. Porém acima de 130 e, principalmente, acima de 140, os testes supervisionados apresentam vários problemas, a começar pelo teto inadequado de dificuldade. As questões mais difíceis do WAIS, por exemplo, são excessivamente fáceis para que possam medir a inteligência acima de 135. Outro problema é que a validade de constructo dos testes supervisionados é planejada para o intervalo de 70 a 130, não se aplicando tão bem fora desse intervalo.
Fiz um exemplo simulado para mostrar em que consiste o problema da variável de constructo:

A linha azul representa o traço latente[*] que gostaríamos de medir (inteligência ou fator g ou algo assim). Os círculos vermelhos representam os escores obtidos no teste convertidos em QI. No intervalo entre 0 e 120, os escores medidos são representações muito boas do traço latente, porque os pontos se distribuem estreitamente perto da linha azul, indicando forte correlação entre a variável que gostaríamos de medir e a variável que estamos realmente medindo. [* https://dictionary.apa.org/latent-trait-theory, https://www.jstor.org/stable/1434009]
A partir de 120, e principalmente a partir de 130, os círculos vermelhos começam a se afastar cada vez mais da linha azul, indicando que a correlação entre a variável que gostaríamos de medir e a variável que está sendo realmente medida se torna cada vez mais fraca, portanto aquilo que estamos medindo está cada vez sendo menos representativo do que gostaríamos de medir. Se considerar o intervalo inteiro de 0 a 200, ou mesmo de 70 a 200, a correlação ainda parece forte, mas isso só acontece porque o intervalo de 70 a 120 está contido dentro do intervalo de 70 a 200, e como no intervalo 70 a 120 a correlação é forte, isso melhora a correlação média do intervalo inteiro de 70 a 200, mas quando se considera exclusivamente a correlação entre 130 e 200, percebe-se que a correlação é fraca nessa região e vai se tornando mais fraca para os escores mais altos. Por isso para escores acima de 130 o que importa não é a correlação global, mas sim a correlação local.
Em testes de QI como o Stanford-Binet, por exemplo, algumas pessoas muito rápidas com QI verdadeiro 150 podem obter escore 190 ou mais, como consequência do problema descrito acima. Também pode acontecer o efeito oposto, e pessoas com QI verdadeiro 190, se forem muito lentas, podem ter escore 150, 140 ou até menos. O tamanho dos erros pode chegar a níveis realmente muito altos, tanto para mais que o correto quanto para menos que o correto, por isso é que a validade de constructo[*] é um quesito extremamente importante. [* https://en.wikipedia.org/wiki/Construct_validity]
Um teste que tenha boa validade de constructo deve apresentar comportamento como o do gráfico abaixo, em que os círculos vermelhos permanecem próximos à linha azul ao longo de todo espectro dentro do qual se pretende medir:
Naturalmente, se a amostra tiver distribuição normal, os dados se distribuirão aproximadamente como uma elipse, não como uma linha que foi representada acima, mas para fins didáticos esse exemplo precisa ser assim para ficar visualmente mais claro o aumento na amplitude da dispersão das medidas em relação ao traço latente que gostaríamos de medir. Também convém enfatizar que, no mundo real, situações como a do gráfico acima praticamente não existem, porque o alinhamento está excessivamente bom. Mas é desejável que os escores medidos sejam capazes de oferecer boas representações para o traço latente dentro de um intervalo tão largo quanto possível.
Nos testes de QI supervisionados, utilizados em clínicas, geralmente as disparidades começam a se tornar graves a partir de 130 e principalmente a partir de 140, ou seja, aquilo que o teste mede acima de 140 deixa de ser uma boa representação da Inteligência. Nos casos dos melhores hrIQts, os escores continuam sendo representações razoavelmente boas do traço latente até QI 160 ou um pouco mais.
Um teste pode ter questões com nível de dificuldade apropriado, mas aquilo que as questões estão medindo pode não ser a inteligência. Ou pode acontecer de que a variável medida seja a inteligência, mas apenas num intervalo específico (como no primeiro gráfico). Alguns quebra-cabeças para crianças, por exemplo, podem ser eficientes para medir corretamente no intervalo entre idade mental de 8 a 16 anos, ou 50 a 100 de QI numa escala para adultos, mas se utilizar esses mesmos quebra-cabeças para tentar medir os QIs de adultos acima de 160 ou 170, o resultado será desastroso, porque a habilidade para resolver rapidamente esses quebra-cabeças não pode ser interpretada como uma boa representação da inteligência nesse nível. Por isso o tipo de problema precisa ser compatível com o nível intelectual que se pretende medir.
Geralmente as pessoas mais inteligentes também são mais rápidas para resolver questões básicas, mas o fato de resolver rapidamente questões simples não oferece uma boa garantia de que a pessoa também será capaz de resolver questões mais complexas, profundas e que exijam criatividade. Além disso, o fato de a pessoa ser capaz de resolver questões complexas, profundas e que exigem criatividade não oferece boa garantia de que ela será capaz de resolver rapidamente questões básicas. Como os testes utilizados em clínicas incluem exclusivamente questões básicas, o efeito apresentado no gráfico 1 acaba sendo muito frequente.
Essa questão é analisada com mais detalhes no texto introdutório do Sigma Test Extended.
Também é necessário padronizar os significados de alguns termos que vou utilizar nas respostas:
rIQ = QI de raridade, ou QI (σ=16 G), ou rIQ (σ=16 G)
pIQ = QI de potencial, ou QI (σ=16 T), ou pIQ (σ=16 T)
Explicações detalhadas podem ser encontradas em https://www.sigmasociety.net/escalasqi. Aqui darei uma explicação resumida: rIQ é o valor que teria o QI convertido a partir da raridade verdadeira. Isso não é o QI medido nos testes de QI nem em hrIQts. O QI medido é o pIQ, cuja distribuição não é gaussiana, a distribuição tem uma cauda densa, por isso os escores de pIQ são mais abundantes do que o previsto com base na hipótese de normalidade da distribuição. Isso não tem relação com o desvio padrão ser maior. O desvio padrão é o mesmo. A forma da distribuição que é diferente, concentrando mais casos na cauda direita e menos na região central. Nas regiões próximas à tendência central, pIQ é quase igual ao rIQ e se mantém assim até cerca de 130. A partir de então, pIQ vai se tornando maior que rIQ. Alguns exemplos:
rIQ 100 equivale a pIQ 100,00
rIQ 130 equivale a pIQ 130,87
rIQ 150 equivale a pIQ 156,59
rIQ 180 equivale a pIQ 204,93
(Uma tabela completa está disponível na página do Sigma Test Extended)
A diferença entre pIQ e rIQ aumenta conforme o rIQ aumenta, porque a proporção em que a densidade real da cauda fica maior que a densidade teórica é cada vez maior à medida que o QI se afasta da média.
Quando se compara QIs estimados com base na raridade com QIs medidos em testes, é fundamental colocar ambos na mesma escala. Por exemplo: digamos que Newton seja considerado a pessoa mais inteligente da História e digamos que o número de pessoas que já nasceram seja 100 bilhões. Então o QI de Newton estimado com base na raridade e com base na hipótese de que a distribuição dos escores é normal seria rIQ=207,3 (σ=16, G). Mas a distribuição real dos escores não é normal, por isso não se pode comparar esse 207,3 com um escore 207 medido num teste, porque estão em escalas diferentes. Ambos podem ter mesmo desvio padrão (16, nesse caso), mas a forma da distribuição é diferente e isso não pode ser negligenciado porque a distorção produzida é gigantesca.
O rIQ de Newton seria 207,3 mas seu pIQ seria 261,8. Repetindo: ambos os escores são com desvio padrão 16, tanto o rIQ quanto o pIQ. Não se deve confundir esse processo com a mudança de escalas com desvios padrão diferentes. Os desvios padrão são iguais, mas a forma da curva é diferente. Eu estou repetindo isso várias vezes porque já vi pessoas confundindo isso apenas um parágrafo depois de isso ter sido esclarecido.
Esse ajuste é necessário para corrigir as distorções das normas e possibilitar o cálculo correto das raridades a partir dos escores medidos nos testes, ou o processo inverso de calcular o QI a partir do nível de raridade.
Desse modo, a pessoa com maior rIQ (σ=16 G) numa população de 7,9 bilhões tem rIQ 201,2 que equivale a pIQ (σ=16 T) 247,8. Os escores 201,2 (σ=16 G) e 247,8 (σ=16 T) são equivalentes, como 0ºC e 32ºF. O uso do termo rIQ equivale ao uso do termo QI (σ=16 G), enquanto o uso do termo pIQ equivale ao uso do termo (σ=16 T). Também posso eventualmente utilizar rIQ (σ=16 G) ou pIQ (σ=16 T).
Por isso os testes podem produzir (e de fato produzem) escores acima de 200 com desvio padrão 15 ou 16, mas o cálculo correto dos níveis de raridade ou dos percentis não deve ser realizado da maneira como tem sido feito há décadas. Os cálculos de percentis e de raridade estão errados, conforme já demonstrei desde meus artigos de 2000 a respeito disso. Eu não estou me referindo a testes com normas infladas. Claro que esse problema se torna mais grave quando as normas estão infladas, mas mesmo quando as normas foram calculadas adequadamente, como nos casos da norma do Mega Test ou do Titan Test, tanto a versão de Hoeflin quanto a versão de Grady Towers, ambas fornecem valores incorretos para os percentis. Os escores de QI estão muito próximos dos valores “corretos”, que seriam os valores ajustados a uma escala de intervalo bem padronizada. O problema não está nos QIs medidos, mas sim nos percentis calculados com base na hipótese incorreta de que esses escores teriam uma distribuição normal. Esse tema voltará a ser analisado outras vezes, com mais detalhes, quando os tópicos abordados exigirem isso. Por enquanto, essa introdução deve ser suficiente para desfazer boa parte das confusões que acontecem com uso indiscriminado do termo “QI”, sem fazer a correta distinção entre pIQ e rIQ.
Quando Chris Harding foi registrado no Guinness Book de 1966 com QI 197, com base em seus resultados no Stanford-Binet, isso foi um erro relativamente primário e grave, porque incorre em todos os 3 itens problemáticos que citei acima: o SB não inclui questões suficientemente difíceis para medir corretamente acima de 135; os processos cognitivos exigidos nas soluções não são apropriados para QIs acima de 150; o nível de raridade calculado é incorreto.
Em 1966, a população mundial era de 3,41 bilhões de pessoas, e o nível teórico de raridade para escores 197, assumindo que a distribuição dos escores fosse uma gaussiana com média 100 e desvio padrão 16, era 1 em 1,49 bilhões. Então parecia ser plausível que uma pessoa com esse escore poderia ser proclamada a mais inteligente do mundo, ou pelo menos a pessoa com maior QI do mundo. Entretanto, uma análise correta da situação revela que o escore 197 no SB não indica nível de raridade de 1 em 1.490.000.000, mas sim 1 em 870.000 (cerca de 2000 vezes mais abundante). Além disso, a variável medida no nível de raridade de 1 em 870.000 não é a inteligência. Nessa conjuntura, o máximo que se poderia afirmar com base num escore 197 no SB é que a pessoa apresentou evidência consistente de possuir nível intelectual acima de 135 de QI, e como seu escore nominal foi muito acima de 135, há boas probabilidades de que seu QI correto seja maior que 150, talvez maior que 160, mas seria necessário prescrever um exame complementar, com questões mais difíceis e com validade constructo apropriada, para investigar qual o nível intelectual real dessa pessoa, já que os escores acima de 135 ficam fora do intervalo no qual o teste é capaz de medir corretamente.
Nos anos seguintes, começaram a surgir várias outras pessoas reivindicando o mesmo recorde, com escores 196-197. Isso prosseguiu até 1978, quando a situação se agravou, primeiramente com Kim Ung-Yong com escore 210, depois Marilyn vos Savant com escore 230, corrigido para 228, depois corrigido para 218, e finalmente Keith Raniere, em 1989, com escore 242. Todos baseados em testes clínicos que não são apropriados para medir corretamente acima de 135.
Um problema similar aconteceu com Langan, no Mega Test. O nível de dificuldade das questões do Mega Test é apropriado para medir corretamente até cerca de pIQ 194, equivalente a cerca de rIQ 177, que corresponde a um nível de raridade de 1 em 1.340.000. Esse é o nível de raridade realista correspondente ao teto do Mega Test. Em 2000 eu havia calculado para o Mega Test um teto de pIQ 186, equivalente a rIQ 169, portanto nível de raridade de 1 em 124.000, mas eu estava me baseando na amostra de 520 testees disponível no site do Miyaguchi. Porém essa amostra não é representativa do conjunto de mais de 4.000 pessoas examinadas com o Mega Test. Essa amostra está estratificada de 10 em 10 (10 pessoas com cada QI, quando possível). Por isso há uma concentração de escores altos acima do “correto”, fazendo com que a dificuldade dos itens, especialmente os itens mais difíceis (que é determinada pela proporção entre os erros e acertos) acabe sendo menor do que a correta, já que havendo mais pessoas com escores mais altos, haverá maior porcentagem de acertadores do que se tivesse sido considerada a amostra inteira. Outro fator é que mesmo considerando todas as mais de 4.000 pessoas avaliadas pelo Mega Test, há uma self-selection que produz uma concentração de pessoas com escores altos maior do que a observada entre a população em geral. Com esses dois ajustes complementares, refiz meus cálculos para essa norma e cheguei aos números que citei acima.
Portanto, com um escore bruto 47/48, obtido por Langan em sua segunda tentativa, o rIQ correspondente é 176, equivalente a pIQ 192, isto é, nível de raridade de aproximadamente 1 em 983.000. O nível de raridade real da Mega Society fica em torno de 1 em 62.000 e da Prometheus 1 em 8.000. Nos casos de ISPE, TNS etc., como estão numa faixa em que as distorções são menores, a raridade verdadeira também fica mais próxima da raridade teórica. 1 em 600. E no caso da Intertel e Mensa, praticamente não são afetadas. O percentil teórico 98,04% para escore pIQ 133 equivale a rIQ 131,8, portanto percentil 97,66%.
Há dois outros pontos que eu gostaria de comentar nesse texto introdutório, antes de prosseguir: sobre o significado de “inteligência” e sobre o significado de “certificado”, mas o texto ficou muito extenso e talvez seja melhor remover, bem como outras partes de algumas respostas. De qualquer modo, salvei o texto integral num arquivo separado, caso tenha alguma utilidade complementar ou para ser utilizado em outra ocasião.
Feitos esses esclarecimentos, agora podemos dar início às respostas.
Entrevista
Scott Douglas Jacobsen: Quando você estava crescendo, quais eram algumas das histórias familiares proeminentes sendo contadas ao longo do tempo?
Hindemburg Melão Jr.: não me interesso muito por histórias.
Jacobsen: Essas histórias ajudaram a dar uma noção de um eu estendido ou uma noção do legado da família?
Melão Jr.: meus avós eram muito pobres, meu pai só estudou até o segundo ano do Ensino Fundamental (2º ano). Ele era excepcionalmente inteligente, criativo, tinha hipermnésia e uma grande variedade de talentos intelectuais e sinestésicos. Isso permitiu que ele saísse de uma situação de extrema pobreza e proporcionasse um ambiente satisfatório para os filhos, mas não muito além disso. O legado de meus pais é quase exclusivamente genético.
Jacobsen: Qual era a origem familiar, por exemplo, geografia, cultura, idioma e religião ou a falta dela?
Melão Jr.: meu bisavô materno era índio nativo do Brasil, meu bisavô paterno era português. Minha família era católica na época que nasci, mas posteriormente se converteram ao Kardecismo, preservando alguns hábitos católicos. Eu me tornei ateu, aproximadamente aos 11 anos, depois agnóstico aos 17 e deísta desde os 27. Tive interesse na Fé Bahá’í por algum tempo, mas não cheguei a participar de nenhuma atividade. Estou escrevendo um livro que trata de Ciência e Religião, no qual abordo alguns desses tópicos com mais detalhes.
Jacobsen: Como foi a experiência com colegas e colegas de escola quando criança e adolescente?
Melão Jr.: foi razoavelmente tranquilo, não tive problemas com bullying que pudessem ser associados a alguma discriminação por motivos cognitivos. Sofri bullying por outros motivos, porque eu tinha as sobrancelhas unidas, mas nada que chegasse ao ponto de me causar grandes constrangimentos, mesmo porque eu praticava artes marciais desde os 7 anos, por isso se eu achasse que estavam passando dos limites, eu reagia de forma enérgica e isso evitava que voltassem a me importunar.
Meus problemas foram com alguns professores, mais do que com colegas, porque eu tinha a visão incorreta de que os professores não podiam cometer erros na disciplina deles, mas no mundo real é muito diferente disso. Praticamente todos os professores cometiam vários erros todos os dias, e eu costumava apontar os erros mais graves. A maioria deles reagia positivamente a isso, alguns agradeciam pelas correções e revisavam imediatamente, mas outros não aceitavam esse tipo de correção, especialmente quando vinha de uma criança de 7 ou 8 anos. Um episódio marcante ocorreu numa aula de Geografia, quando eu tinha 9 anos, e a professora solicitou aos alunos que calculassem o tamanho do litoral brasileiro. Quando comecei a executar a tarefa, percebi que aquilo não fazia sentido, porque a medida dependeria do nível de detalhes do mapa, logo não havia uma resposta possível. Então expliquei o problema a ela, mas ela não entendeu minha explicação. Ela achou que eu estivesse me referindo ao fato de o mapa estar numa escala diferente do tamanho real. Então expliquei novamente, mas não adiantou, ela continuou sem entender, ficou irritada e acabou agindo de forma opressiva, ordenando que eu me calasse, e continuou a “ensinar” incorretamente. Foi um episódio muito desagradável. Geralmente os erros que eu identificava eram erros dos professores, mas nesse caso era muito mais grave, porque era um erro institucionalizado e aceito como se fosse correto pelas “autoridades” naquela disciplina, estava errado no livro e provavelmente em todos os outros livros, sendo ensinado incorretamente a todos os alunos. Aliás, isso continua errado até hoje, 40 anos depois, em praticamente todas as fontes sobre o assunto, inclusive na Wikipedia, Enciclopédia Britânica, IBGE, Cia World Factbook, U.S. Bureau of Labor Statistics etc. O problema não é que o número da medida esteja errado. O problema é que a pergunta não faz sentido porque não há um “comprimento” do litoral, não existe uma resposta possível com dimensão 1, porque o perímetro tem uma dimensão maior que 1 e menor que 2. Embora tenha sido desagradável, foi também um evento do qual me lembro com orgulho, por ter deduzido um dos fundamentos da Geometria Fractal, de improviso, aos 9 anos.
Jacobsen: Quais foram algumas certificações, qualificações e treinamentos profissionais obtidos por você?
Melão Jr.: a finalidade primordial das certificações deveria ser atestar que determinada pessoa ou determinada entidade cumpre quesitos que não seriam facilmente verificáveis por uma pessoa da população em geral. Por exemplo: uma pessoa sem muita instrução teria dificuldade para avaliar corretamente se um médico está capacitado para tratar da saúde dela, ou decidir se seria melhor receber tratamento de um método alopata ou de um curandeiro. Por isso há entidades reguladoras, constituídas por especialistas experientes e supostamente competentes, que estabelecem normas que teoricamente deveriam ser necessárias e suficientes para distinguir entre profissionais qualificados e não-qualificados, protegendo a população menos esclarecida contra a prestação de serviços e produtos insatisfatórios ou até mesmo nocivos. Isso é bonito na teoria, mas na prática não funciona tão bem, e a indústria das certificações acaba servindo a outros propósitos, entre os quais a reserva de mercado, o nepotismo, o culto à vaidade e egolatria.
Os certificados muitas vezes não cumprem a função para a qual foram criados, ora aprovando pessoas/entidades insuficientemente capacitado, ora deixando de aprovar pessoas sobrequalificadas. Por essa razão, mais importante e mais justo seria examinar as realizações, as competências e os méritos reais, em vez de examinar as certificações que reconheceriam esses méritos, porque os méritos têm valor intrínseco, enquanto as certificações são meras aparências que algumas vezes tentam representar os méritos, mas nem sempre acertam.
Há inclusive uma ampla indústria para comércio de certificados fraudulentos, e pouca fiscalização sobre isso. A American Biographical Institute (ABI) é famosa pela venda de certificações sem valor, e continua atuando desde 1967. Há muitas entidades similares, especializadas na impressão de certificados bonitos, promoção de cerimônias de homologação etc. Geralmente as pessoas que consomem esses produtos são vítimas ingênuas, mas também é possível que algumas pessoas comprem esses certificados cientes de que eles significam (ou não significam).
Na Wikipedia consta a seguinte descrição para a ABI:
“The American Biographical Institute (ABI) was a paid-inclusion vanity biographical reference directory publisher based in Raleigh, North Carolina which had been publishing biographies since 1967. It generated revenue from sales of fraudulent certificates and books. Each year the company awarded hundreds of “Man of the Year” or “Woman of the Year” awards at between $195 and $295 each.” Fonte: https://en.wikipedia.org/wiki/American_Biographical_Institute
Atualmente há várias universidades de P.O. Box distribuindo títulos de Ph.D. como água. Eu assisti a algumas declarações de pessoas que compraram esses títulos, a grande maioria dessas pessoas realmente acreditava que tinham algum valor e se mostravam emocionadas, felizes e orgulhosas ao receber o título. Mas talvez nem todos sejam ingênuos e alguns compreendam que esses títulos não representam algo real, mas usam isso com finalidades obscuras. Há um membro da mensa brasil que possui mais de 50 títulos acadêmicos por uma universidade de P.O. Box, fundada em 2021, mas no site da “instituição” alega ter sido fundada em 2006. Acho engraçado, e ao mesmo tempo triste, que os jornalistas que publicam as matérias sobre isso não desconfiam que seja estranho uma pessoa de 40 anos, que tinha apenas 1 B.Sc. até 2020, de repente passou a ter mais de 50 títulos acadêmicos em 2022, inclusive vários Ph.Ds. e pós-doutorados. Além dos certificados comprados, essa pessoa também afirma que a TNS é a sociedade de alto QI mais exclusiva do mundo, ele usa o QI dele com desvio padrão 24 para comparar com um “QI” fictício 160 atribuído a Einstein, entre outras coisas, e os jornalistas publicam tudo sem conferir.
Há também pessoas que compram esses certificados, sabendo que não têm valor, sem a intenção de fazer uso desonesto, talvez como um enfeite de mesa ou algo assim. Por exemplo, Chris Harding é cliente da ABI, possui vários títulos adquiridos dessa empresa, conforme ele mesmo declara em seu perfil na OlympIQ Society. Harding tem alguns méritos reais, porque mesmo que o SB não avalie corretamente acima de 140, é reconhecido que esse teste avalia algum tipo de habilidade misturado com inteligência, e poucas pessoas alcançam o escore de Harding nesse exame. Portanto, embora alguns certificados dele sejam comprados, outros são baseados em méritos reais e emitidos por instituições sérias, como os relacionados a seus recordes de QI e suas filiações a sociedades de alto QI. Entretanto, mesmo os certificados idôneos, que tentam representar méritos verdadeiros, muitas vezes atestam algo que não é uma boa representação da realidade. Conforme comentei no início, o escore 197 ou 196 no SB não poderia ser interpretado da maneira como foi, e os laudos oficiais e os certificados emitidos estão dizendo algo que representa uma crença coletiva, mas muito diferente da realidade concreta.
Harding é muito inteligente, mas não com base no escore que ele obteve no SB, e sim com base em várias opiniões dele sobre diferentes assuntos. Os méritos reais dele estão em sua essência, em suas ações, seus pensamentos, não em pedaços de papel.
A partir do momento em que a pessoa canaliza seus pensamentos e suas ações para produzir algo concreto, ela passa a compartilhar com o mundo sua essência, disseminando conhecimento e sabedoria, ou disseminando futilidade e desinformação, dependendo da qualidade daquilo que ela compartilha. E a percepção que as outras pessoas têm sobre aquilo que ela compartilhou dependerá não apenas da qualidade do que ela exteriorizou, mas também da sensibilidade e perspicácia de quem recebe a informação. Se uma pessoa brilhante disseminar conhecimentos de um nível muito elevado entre um público muito fútil, o valor desse conhecimento não será reconhecido e ela não terá certificações, nem prêmios, nem qualquer reconhecimento, enquanto outras pessoas que estejam disseminando conhecimentos vulgares e rasos, compatíveis com o público que o recebe e que emite as certificações, essas pessoas serão aclamadas e glorificadas.
As pessoas não são premiadas ou certificadas por suas realizações serem grandiosas, mas sim por suas realizações serem percebidas como grandiosas pelos membros dos comitês responsáveis pela homologação de prêmios e certificações. Além disso, há uma série de outros vieses de caráter político, social, racial, etc., que interferem nas decisões dos membros dos comitês, tornando as certificações e os prêmios ainda mais destoantes do objetivo que deveriam ter.
Esse efeito ocorre, por exemplo, em alguns testes de Cooijmans, em que o teste não mede o QI, mas sim quão semelhante é o QI da pessoa examinada em comparação ao QI do Cooijmans. Se a pessoa tiver o mesmo QI de Cooijmans, ela terá escore máximo. Se ela tiver QI muito maior ou muito menor que o QI de Cooijmans, o escore dela será baixo. Na questão sobre testes de QI, comento mais detalhadamente esse problema.
Citarei alguns poucos exemplos marcantes, alguns bastante conhecidos, mas vale a pena rememorá-los. Creio que um dos mais trágicos e marcantes seja o de Galileu, que em vez de ser premiado por suas notáveis contribuições à compreensão do Universo, ele foi severamente punido. Aliás, sua filha Celeste acabou sendo punida em lugar dele. Nos tempos mais recentes, um dos casos que acho muito tristes é o de George Zweig, que desenvolveu sua Teoria dos Ases na mesma época em que Murray Gell-Mann desenvolveu a Teoria dos Quarks. Ambas eram essencialmente iguais, entretanto a revista para a qual Zweig enviou seu artigo se recusou a publicá-lo, enquanto o artigo de Gell-Mann lhe rendeu o prêmio Nobel de Física. Há pelo menos 45 casos conhecidos de prêmios Nobel polêmicos, de pessoas que receberam sem merecer ou mereciam, mas não receberam. O prêmio mais respeitado do mundo está profanado por dezenas de injustiças, talvez centenas, se considerar as que não chegaram a ser descobertas. Inclusive Einstein é uma das maiores vítimas, já que merecia ter recebido 5 prêmios Nobel, entretanto recebeu apenas 1, por motivos raciais, xenofóbicos, nazistas etc.
Creio que agora eu possa responder a essa questão, dividindo-a em duas partes:
- Prêmios e certificações.
- Méritos até o momento não reconhecidos.
Tenho poucos certificados. Quando eu era jovem, tinha o hábito de colocar troféus e medalhas de Xadrez, Artes Marciais, Educação Artística etc. numa estante, mas numa das mudanças de endereço, um de meus troféus quebrou. Inicialmente fiquei triste, porque eram importantes para mim. Mas ao refletir melhor sobre o “desastre”, percebi que na verdade não tinham nenhuma importância. O que realmente importava eram os méritos que me levaram à conquista daqueles prêmios, bem como alguns méritos que não chegaram a ser premiados. Havia também casos nos quais eu não tinha mérito algum, mas havia sido premiado devido a alguma fatalidade da sorte. Isso não significa que eu não seja uma pessoa vaidosa. Eu sou, mas aprendi que na maioria das vezes não se recebe nada ou quase nada por algo valoroso, enquanto outras vezes se recebe mais do que o justo por algo de pouco valor ou até mesmo sem valor. Infelizmente o mundo recompensa muito mais as aparências do que a essência.
Um de meus poucos certificados é o de detentor do recorde mundial de mate anunciado mais longo em simultâneas de Xadrez às cegas, registrado no Guinness Book de 1998. Talvez algumas pessoas não estejam familiarizadas com o significado de “Xadrez às cegas” e “mate anunciado”. Esse vídeo ajuda a entender a dinâmica de uma simultânea às cegas: https://youtu.be/LUo89Cl9FPY. É um vídeo antigo e de baixa qualidade, mas para exemplificar o mecanismo do evento, creio que seja apropriado.
Farei uma descrição resumida: numa simultânea, uma pessoa (simultanista) joga ao mesmo tempo contra vários oponentes (simultaneados), cada um dos quais com seu próprio tabuleiro. É diferente de um jogo em consulta, em que vários jogadores podem se consultar mutuamente num único tabuleiro e decidem sobre o melhor lance por votação. Numa simultânea, cada simultaneado tem seu próprio tabuleiro e cada partida segue seu próprio rumo.
Nesse caso, como se trata de uma simultânea às cegas, o simultanista não tem acesso visual a nenhum dos tabuleiros, nem às peças, nem às súmulas, nem a qualquer tipo de registro dos lances ou das posições. Em nenhum momento o simultanista pode olhar para nenhum dos tabuleiros, nem solicitar qualquer tipo de informação que o ajude a se lembrar das posições das peças, nem de qualquer peça específica, nem que o ajude a se lembrar da ordem dos lances, nem qualquer outro tipo de informação que possa de algum modo auxiliar sobre as partidas. A posição de cada uma das peças em cada um dos tabuleiros fica registrada exclusivamente na memória do simultanista e essas posições são atualizadas mentalmente a cada lance. Além disso, a cada lance o simultanista precisa fazer os cálculos das variantes e sub-variantes necessários para tomar suas decisões sobre o lance a ser executado, tomando cuidado para não confundir as lembranças das variantes calculadas com as lembranças das variantes efetivamente jogadas, entre outros cuidados.
O jogo se desenvolve da seguinte forma: o simultanista permanece de costas para os tabuleiros e comunica seus lances a um assistente (speaker), que executa cada lance do simultanista no respectivo tabuleiro. Em seguida, o simultaneado daquele tabuleiro executa sua resposta sobre o tabuleiro e o speaker comunica verbalmente ao simultanista qual foi o lance executado por aquele simultaneado. Então o speaker passa ao tabuleiro seguinte, onde novamente o simultanista declara seu lance e este é executado nesse tabuleiro pelo speaker etc.
Há versões mais “fáceis” (ou menos difíceis), nas quais o jogador às cegas pode ter acesso a uma lista com todos os lances anotados, como nos torneios de Melody Amber, em que, além de serem jogos individuais, em vez de simultâneos, os competidores podem também visualizar um tabuleiro vazio, o que facilita os cálculos e reduz os riscos de se esquecer da posição de alguma peça. Mas nas regras mais rigorosas, como no meu recorde de 1997 que foi registrado no Guinness, não era permitido ter acesso ao histórico dos lances, nem ver um tabuleiro vazio, nem qualquer outro tipo de auxílio similar. É equivalente a estar todo o tempo com os olhos vendados, do início ao fim do evento.
Esse recorde estabelecido em 1997 foi numa simultânea às cegas a 9 tabuleiros, num dos quais anunciei mate em 12 lances. O rating médio de meus oponentes foi estimado em cerca de 1400. Obtive 7 vitórias, 1 empate e 1 derrota.
Os recordistas anteriores eram: Joseph Henry Blackburne (mate em 8 lances numa simultânea às cegas a 10 tabuleiros, no ano 1877), Samuel Rosenthal (mate em 8 lances numa simultânea às cegas a 4 tabuleiros, no ano 1885) e Garry Kasparov (mate em 8 lances numa simultânea às cegas a 8 tabuleiros, no ano 1985). Houve também um evento em 1899, no qual Harry Nelson Pillsbury anunciou mate em 8 numa simultânea às cegas a 10 tabuleiros, mas houve erro de contagem. Seguindo a sequência ditada por Pillsbury, o mate se produzia em 7 lances.
No caso de Kasparov, há alguns detalhes que precisam ser esclarecidos: ele jogou uma simultânea às cegas contra os 8 melhores computadores da época, inclusive o campeão mundial Mephisto Amsterdam 68000 RISC 12MHz. O rating médio dessas máquinas era cerca de 1500 e os melhores chegavam a 1800. O melhor computador do mundo em 1985 era justamente o Mephisto Amsterdam, cujo rating divulgado pelo fabricante era 2265, mas posteriormente foi medido pela SSDF em 1827 (com base em 1020 partidas). Na partida contra Mephisto Amsterdam, Kasparov jogou uma bela combinação com sequência de mate em 8 lances, mas não há registro sobre ele ter anunciado o mate. De qualquer modo, como ele sacrificou uma Torre e duas peças no início da combinação, está claro que ele calculou corretamente a sequência inteira.
Em 2005, a rede Globo fez uma reportagem para o programa “Fantástico” celebrando os 100 anos dos testes de QI, e fui indicado como a pessoa com QI mais alto do Brasil, no nível de 1 em 200 milhões. Esse é um exemplo de “reconhecimento” que eu não tenho certeza se foi corretamente atribuído. Na pergunta sobre QI, comento esse assunto com mais detalhes.
Recentemente, o amigo Domagoj Kutle me honrou com um amável convite para publicar em sua excelente revista DEUS VULT, e solicitou que eu enviasse também uma pequena biografia. Minha namorada Tamara gentilmente me ajudou a elaborar esse material, incluindo algumas de minhas realizações. Creio que isso se encaixaria aqui, por isso vou colar o texto:
Melao mini-bio, by Tamara Rodrigues:
Hindemburg Melao Jr. was born in Brazil, in a family with few resources, and only attended school until the 11th grade, having learned almost completely as self-taught.
In 1998 he was registered in the Guinness Book as the holder of the world record for longest announced checkmate in blindfold simultaneous chess games. (video)
Between 2006 and 2010 he developed an artificial intelligence system to trade in the Financial Market; in 2015, his friend and partner Joao A.L.J. incorporated a hedge fund to use this system and started to be registered in fund rankings (BarclayHedge, IASG and Preqin), winning 21 international high performance awards.
In 2007, Melao solved a problem that had been unsatisfactorily solved for 22 years, by creating “Melao index”, an index to measure performance adjusted at risk that was more accurate, more predictive and conceptually better founded than the traditional indexes of William Sharpe (Nobel prize 1990) and Franco Modigliani (Nobel 1985). (video)
In 2003 he solved a 160+ year old problem by proposing a new formula for calculating BMI, superior to the traditional one and superior to the formula proposed in 2013 by Nick Trefethen, Chief of the Dept. of Numerical Analysis at the University of Oxford, Leslie Fox Prize(1985), FRS prize, (2005), IMA Gold Medal (2010). Trefethen’s 2013 formula is an incomplete version of Melao’s 2003 formula.
In 2000 Melao developed the first method for standardization of intelligence tests that produces scores in scale of ratio and in 2003 he applied this method in the Sigma Test norm (he also calculated new norms for Mega and Titan tests using the same method), thereby solving a problem of Psychometry that exists more than 90 years ago and was pointed by Thurstone and Gardner as a central question of Psychometry more than 45 years ago.
In 2002 Melao found the best solution to a problem that has existed for more than 520 years and had been attacked for more than 65 years, the Shannon Number, which was only matched in 2014 by Stefan Steinerberger, professor of mathematics at Yale University.
In 2015 Melao showed that the method recommended by the Nobel Prize in Economics Harry Markowitz, for portfolio optimization, has some flaws, and proposed some improvements that make this method more efficient and safer.
In 2021 Melao pointed out flaws in the recommendation of the 2003 Nobel Prize in Economics, Clive Granger, regarding the use of the concept of cointegration, and presented a more adequate solution to the same problem.
In 2022, Melao solved a problem that had been open for 16 years, in which he established a method for calculating chess ratings based on the quality of the moves. Also presented an improved version of the Elo system, applying both methods to calculate the ratings of more than 100,000 players between years 1475 and 2021, the results were published in a book, along with the description of the two methods.
At 9 years old Melao deduced one of the fundamentals of Fractal Geometry and at 13 he developed a method to calculate logarithms. At age 19 he developed a method for calculating factorials of decimal numbers without using Calculus. (more details)
Also at the age of 19 (1991) he developed an invisibility machine project, which in 1993 he inscribe in a contest of ficction Literature (although the project is consistent with Scientific Method), but did not win. In 2003 Susumu Tachi, Emeritus Professor at the University of Tokyo and guest Professor at MIT, created (independently) a simplified version of this project and built a prototype.
In 2020 Hindemburg presented a study showing that Jupiter’s Great Red Spot cannot be 350+ years old, as was believed. The correct age is around 144 years old. (interview)
In 2000 Melao had a chess theoretical novelty elected one of the 10 most important in the world by the Sahovski Informator jury, the world champion Anand was one of the judges and Anand’s vote was that this novelty should be the 8th most important.
In 2004 Baran Yonter, founder of Pars Society (IQ>180, sd=16), estimated that Melao IQ should be above 200 (sd=16).
In 2005 the production of the program “Fantástico”, from Globo (second-largest commercial TV network in the world), made a special report on intelligence, celebrating the centenary of the creation of IQ tests, and Melao was nominated as the person with the highest IQ in Brazil, with a rarity level of 1 in 200 million. (video1, video2)
In 2009 Melao was nominated by Albert Frank to participate in a John Hallenborg project with people whose IQ is at the rarity level above 1 in 1 million.
In 2000 Melao updated and extended his “Alpha Tests” that he had created in 1991, added new questions, and created the Sigma Test.
In 2022 he extended the Sigma Test by creating the extended version.
Melao is author of more than 1700 articles on Science, Statistics, Psychometrics, Econometrics, Chess, Mathematics, Astronomy, Physics, Cognitive Science, Ethics, Philosophy of Science, History of Science, Education etc.
Detailed bio of Melao (documents, videos, interviews, articles, reports etc.) at: https://www.sigmasociety.net/hm
Embora eu tenha praticado Artes Marciais por vários anos (talvez ~11 anos se somar todos os períodos ativos), não cheguei a obter nenhuma certificação, porque o tempo foi distribuído entre muitas modalidades diferentes e não cheguei à faixa preta em nenhuma delas. Mas cheguei a alcançar um nível técnico razoável. Para armas curtas, talvez eu esteja no percentil 99,9% e no caso específico de nunchaku, talvez 99,999%. Esse é um vídeo de 2016, eu já estava meio velho e enferrujado https://youtu.be/jCw–5H34x4. No mesmo canal há também vídeos com outras armas (espada, tonfa, kama, sam-tien-kuan etc.).
Em 2020 fui convidado para um grupo dos 26 melhores astrofotógrafos planetários do Brasil. Embora não haja certificado para isso, fiquei muito feliz porque é um de meus hobbies favoritos. Eu gostaria de aproveitar essa oportunidade para agradecer ao amigo Vinícius Martins, que me ensinou quase tudo que sei sobre processamento de imagens planetárias, creio que em pouco tempo ele será um dos 5 melhores astrofotógrafos do mundo, ele combina 3 elementos fundamentais para isso: um talento extraordinário, um amor imenso por essa atividade e um profundo conhecimento que se amplia e se atualiza constantemente.
Entre as certificações que não possuo, uma das mais interessantes é a de CFA, conferida a gestores de investimentos. É interessante porque entre 2006 e 2010 desenvolvi um sistema de inteligência artificial para operar no Mercado Financeiro que entre 2015 e 2020, quando foi utilizado por um fundo europeu, conquistou 21 prêmios internacionais de alta performance nos rankings da Barclay’s Hedge, Preqin e IASG, sendo também o segundo melhor sistema de investimentos do mundo entre 2011 e 2016. Entretanto, eu fui proibido pela CVM de prestar serviços de gestão porque não possuo o certificado CFA. Em 2014, foi realizado um abaixo-assinado para pleitear que a CVM (entidade reguladora do Mercado de Capitais no Brasil) emitisse para mim um certificado em caráter extraordinário. A reivindicação se apoiava na redação da Instrução 306 da CVM e no fato de que meu sistema tinha acumulado mais que o dobro do lucro do fundo que ocupava o primeiro lugar (à frente de 282 outros fundos, todos administrados por gestores certificados) no ranking da InfoMoney, maior ranking de fundos do Brasil. Entre as pessoas que assinaram a petição em meu favor, houve vários professores universitários, vários gestores profissionais e vários membros de sociedades de alto QI, inclusive Dany Provost de Giga Society. Entretanto, a reivindicação não foi aceita e continuo não possuindo esse certificado. Aliás, os dois gestores mais famosos do mundo, Warren Buffett e George Soros, também não possuem certificado de gestor, então estou em boa companhia. Buffett resolveu esse problema incorporando uma empresa que compra outras empresas, em vez de administrar um fundo. Soros resolveu o problema colocando seu amigo Jimmy Rogers como gestos (Jimmy possuía a certificação necessária), eu resolvi o problema comercializando licenças de uso de meu sistema, com um limite de volume de aplicação para cada licença e um período de renovação.
Entre as certificações que não possuo, posso incluir também CNH, embora eu dirija fora da Lei (sou praticamente um gângster). Eu deixei de ir à escola no 5º ano, depois eu retornei algumas vezes, por pressão de meus pais. Eu voltava, continuava matriculado alguns meses, esgotava minha paciência, parava novamente, meus pais me pressionavam a voltar, eu novamente voltava etc. Cheguei a concluir o ensino médio (11º ano) e entrei na faculdade de Física, mas não gostei do curso e parei definitivamente depois de 2 meses. Na primeira semana de aula, eu revisei o livro de Física I e apontei mais de 200 erros, enviei meus comentários ao autor, com uma nota introdutória tentando ser diplomático, para que ele não se sentisse ofendido, mas ele nunca respondeu. Também apontei dois erros conceituais graves nos métodos utilizados no laboratório de Física, que deveriam impactar nos resultados dos experimentos; um deles, sobre as bolas de papel amassado, é o mesmo “experimento” realizado no Departamento de Matemática da Universidade de Yale, onde também cometem o mesmo erro. Nesse caso, o Prof. Dr. Paulo Reginaldo Pascholati teve uma conduta honrada, recebeu com humildade minhas críticas, fez alguns experimentos para investigar se o erro que eu indicava era procedente, constatou que eu tinha razão e, na aula seguinte, ele assumiu publicamente o erro. Achei a conduta dele exemplar, nesse aspecto, entretanto a apostila não foi corrigida e continuaram a fazer o experimento incorretamente.
Enfim, decidi que universidade era perda de tempo e seria mais produtivo estudar por conta própria, mas não é tão simples assim, e essa decisão se mostrou questionável em algumas ocasiões. O distanciamento da carreira acadêmica tem alguns aspectos positivos, outros negativos. Um dos aspectos positivos é que posso selecionar minha própria grade curricular, seguir meu próprio ritmo e me aprofundar o quanto quiser em cada tópico. Um dos aspectos negativos é que se torna mais difícil ter acesso a bibliografia satisfatória e mais difícil ainda publicar em periódicos indexados. Com isso, praticamente coloquei a mim mesmo numa situação de ostracismo.
Portanto certificados são úteis, mas é importante compreender as limitações e as distorções que podem apresentar, para não correr o risco de tratá-las de forma burocrática, a ponto de serem colocados acima da real capacidade verificada empiricamente de forma contínua. Certificados refletem as opiniões de pessoas ou de instituições que muitas vezes não estão suficientemente qualificadas para fazer avaliações corretas sobre os méritos e para decidir com imparcialidade. No exemplo do CFA, as certificações são literalmente distribuídas com base em critérios excessivamente condescendentes, que nem de longe são suficientes para selecionar as pessoas qualificadas ao exercício da função de gestor, por isso mais de 95% dos gestores certificados geram prejuízos a seus clientes. Talvez esse efeito seja mais notável no Mercado de Capitais do que em qualquer outra atividade, mas também ocorre frequentemente em Jornalismo, Publicidade, Administração etc., em que algumas pessoas sem formação nessas disciplinas eventualmente podem ser mais qualificadas do que pessoas certificadas, mas para proteger os menos competentes, são criadas leis que impedem as empresas de contratar os mais competentes, usando certificados como instrumento de discriminação e de apologia à mediocridade.
Escrevi uma versão extensa dessa resposta, na qual discuto algumas falhas no sistema educacional no Brasil e no mundo, justificando porque me afastei da vida acadêmica. Também aponto e analiso os erros cometidos por Richard Lynn em seu estudo sobre os QIs em diferentes países e explico porquê não seria correto tentar justificada o problema educacional no Brasil com base no suposto baixo QI médio da população, bem como reviso a estimativa para o QI médio de alguns países, inclusive Guiné Equatorial, Israel e Brasil. O texto ficou com 10 páginas A4, por isso achei melhor colocar como um apêndice.
Jacobsen: Qual é o propósito dos testes de inteligência para você?
Melão Jr.: o atributo mais importante dos seres vivos é a inteligência. Sem inteligência não existiria Ética, Leis, Ciência ou Arte. Para delegar corretamente as tarefas mais importantes às pessoas mais qualificadas, é necessário identificar e ranquear corretamente as pessoas de acordo com as habilidades de cada uma. Por isso medir corretamente a inteligência e utilizar os resultados como critério para atribuir cargos e tarefas, conforme o nível de competência, é extremamente importante, mas infelizmente não é o que acontece. Há dois grandes problemas:
- O primeiro é que o mundo é dominado pelo nepotismo;
- O segundo é que não existem testes de inteligência apropriados para medir corretamente nos níveis mais altos.
No final do século XIX, os primeiros testes de Galton e Cattell não conseguiam medir satisfatoriamente a inteligência, mas foi uma tentativa interessante. A hipótese de que a velocidade dos reflexos, a acuidade visual, a acuidade auditiva etc. poderiam ser indicativos relevantes do nível intelectual se mostrou inadequada. Em 1904, Binet e Otis conseguiram resolver esse problema, utilizando questões que exigiam a o uso combinado de várias habilidades cognitivas – em vez de tentar medir aptidões primárias, como fez Galton –, mas os testes de Binet só mediam corretamente até cerca de 140. As tentativas de Terman, em 1921, de utilizar os testes de Binet para selecionar futuros gênios falharam. Entre as 1528 crianças selecionadas com QI acima de 135 (mais de 70 com QI acima de 177), nenhuma ganhou um Nobel nem qualquer prêmio similar, enquanto duas das crianças não selecionadas ganharam prêmios Nobel. O teste funcionava muito bem até cerca de 130, as crianças selecionadas publicaram mais livros, mais artigos, tiveram maior renda média do que as crianças do outro grupo, porém nos níveis mais elevados, o teste falhou e deixou escapar algumas das crianças mais brilhantes. Os resultados desse estudo tiveram um efeito extremamente deletério, prejudicando a credibilidade nos testes de QI aos olhos do público em geral e aos olhos de muitos expoentes intelectuais de áreas científicas, tecnológicas, culturais e educacionais, por isso seria importante esclarecer os limites de até que ponto esses testes podem medir corretamente, para que não se crie expectativas irreais e para que não sejam aplicados incorretamente fora de desses limites.
Em 1973, Kevin Langdon criou o LAIT (Langdon Adult Intelligence Test) e com isso conseguiu elevar o nível de dificuldade até perto de 170 e a validade de constructo até 150; em 1985, Ronald Hoeflin deu mais um passo importante com o Mega Test, elevando o nível de dificuldade até cerca de pIQ 190 e validade de constructo até 170, e essas contribuições ampliaram os horizontes de aplicação dos testes de inteligência, que antes funcionavam bem até o nível aproximada de 1 em 100, enquanto os novos testes passaram a funcionar até 1 em 100.000. Por outro lado, a partir dos anos 1990, começaram a surgir alguns testes de fantasia com tetos nominais que chegavam a 250, embora o teto real de dificuldade não chegasse a 180 e o teto de validade de construto fique em torno de 150, como o ISIS Test de Paul Cooijmans. Alguns desses testes de fantasia continuam surgindo até hoje e isso agrava o preconceito nutrido por muitas pessoas contra os testes de QI, porque se a pessoa tem um pensamento crítico refinado e uma atitude cética, ela percebe que há inconsistências em resultados como o de Feynman (123) e Rosner (193, 196, 198 etc.). Ambos são muito inteligentes, e os problemas que Feynman resolveu são mais difíceis que os problemas que Rosner resolveu, o que poderia ser interpretado como indicativo de que Feynman fosse mais inteligente, então como é possível que um sistema padronizado sério de avaliação atribua 190+ para Rosner e 123 para Feynman? Alguma coisa obviamente não está certa nisso, e as pessoas geralmente não identificam exatamente onde está o erro, por isso concluem, de forma generalizada, que todos os testes de QI não funcionam, ou sequer elas sabem que existe mais de um tipo de teste de QI. Por isso o esclarecimento sobre qual é o intervalo no qual cada tipo de teste funciona contribui para combater esse tipo de preconceito. Se o QI verdadeiro de Feynman, com base na dificuldade, complexidade e profundidade dos problemas que ele resolveu sobre eletrodinâmica quântica, superfluidos etc. fosse colocado na mesma escala em que é representado o QI de Rosner, o QI correto de Feynman estaria perto de 235. E para explicar esse número acima de 200, teria antes que mostrar que a distribuição dos escores não é gaussiana etc. etc. Então aquela aparente inconsistência inicial desapareceria e tudo ficaria mais claro e mais lógico. O mesmo acontece para o QI fictício de Einstein de 160, cujo valor correto, se colocado na mesma escala dos escores medidos pelos testes, seria perto de 250.
Em 2000, o Sigma Test trouxe soluções aos 3 problemas citados no texto introdutório, tendo como foco principal a validade de constructo, utilizando questões baseadas em problemas do mundo real que exigem uma combinação de pensamento convergente e divergente em diferentes níveis de dificuldade, complexidade e profundidade, compatíveis com os níveis de QI a serem medidos. Mais recentemente, o Sigma Test Extended elevou o teto de dificuldade até cerca de pIQ 225 e de validade de constructo até cerca de 210. Entretanto, numa população com 7,9 bilhões, a pessoa adulta mais inteligente do mundo deve ter rIQ em torno de 201, equivalente a cerca de pIQ 245, portanto bastante fora dos limites que o STE pode medir. Apesar disso, para algumas das 100 ou 200 pessoas mais inteligentes vivas, o STE poderia fornecer medidas fidedignas da inteligência real, com boa validade de constructo nesse patamar, além de oferecer um desafio intelectual estimulante. Isso consertaria algumas lendas urbanas disseminadas em várias fontes, como a de que o QI médio dos ganhadores do Nobel em Ciência é “apenas” 154. Com o uso de um teste adequadamente padronizado, com nível de dificuldade apropriado e boa validade de constructo, o QI médio dos ganhadores do Nobel em Ciência deve ficar entre 170 e 190. Com o uso de testes apropriados é possível reposicionar corretamente os escores, tanto para cima quanto para baixo. Isso também venceria alguns preconceitos contra os testes de QI, porque uma das razões para rejeição se deve justamente aos resultados bizarros para Feynman (123), Fischer (123*), Kasparov (123, 135), Shockley (<135), Alvarez (<135), irmã de Feynman (124) etc., porque isso tira a credibilidade dos testes, já que é muito mais provável que esses escores estejam errados do que essas pessoas terem QI abaixo do nível de 1 em mil, quando na verdade devem estar acima de 1 em 1 milhão (e Feynman perto de 1 em 1 bilhão). Quando podemos mostrar que os testes são capazes de medir corretamente também nos níveis muito altos e fornecer resultados realistas, consistentes com as realizações dessas pessoas em problemas do mundo real, consegue-se restaurar a credibilidade para testes de inteligência como instrumentos sérios e confiáveis, capazes de desempenhar uma das funções mais importantes que é justamente fazer prognósticos precoces de genialidade. [* Embora muitas fontes mencionem o QI 187, 181 ou 180 para Fischer, seus laudos de 1958 mostram um escore 123]
Assim, embora não haja testes capazes de medir corretamente no nível necessário para apontar a pessoa mais inteligente viva, ou ranquear as 10 mais inteligentes, houve um progresso substancial desde os primeiros testes de Binet, e se Terman estivesse vivo hoje e desenvolvesse o mesmo estudo de 1921, mas começando em 2000, e se ele utilizasse o STE em vez do SB, muito provavelmente as crianças mais inteligentes estariam todas (ou quase todas) selecionadas em seu grupo, e os resultados subsequentes teriam sido confirmatórios inclusive nos níveis mais altos, corroborando a tese que ele defendia, de que é possível prever precocemente a genialidade, mas não com os testes que existiam naquela época. A tese, em si, estava correta, assim como o helicóptero de Leonardo Da Vinci, mas a tecnologia ainda precisava avançar um pouco mais para que a tese dispusesse dos subsídios necessários para ser testada adequadamente.
Jacobsen: Quando a alta inteligência foi descoberta para você?
Melão Jr.: Acho difícil determinar isso com precisão. A primeira vez que fui examinado em clínica, tinha 3 anos, mas aos 6 meses de idade eu conversava com razoável fluência, então havia algumas evidências mais precoces.
Jacobsen: Quando você pensa nas maneiras pelas quais os gênios do passado foram ridicularizados, vilipendiados e condenados, se não mortos, ou elogiados, lisonjeados, plagiados e reverenciados, o que parece ser a razão para as reações extremas e o tratamento de gênios? Muitos vivos hoje parecem tímidos diante das câmeras – muitos, nem todos.
Melão Jr.: não creio que seja um problema do passado. Continua presente em muitas culturas primitivas, como no Brasil e em vários países da África. A grande maioria da população adota uma postura de hostilidade, inveja e boicote não apenas contra gênios, mas contra qualquer pessoa que possa estar obtendo algum tipo de sucesso. Recentemente minha namorada me mostrou um vídeo de Ozires Silva, que foi Ministro da Infraestrutura e presidente da Petrobrás. Ele comenta que durante um jantar no qual estavam presentes alguns membros do comitê do Nobel (link par ao vídeo: https://youtu.be/m3u-E5XdzZ4) ele perguntou por que eles achavam que o Brasil não tinha nenhum ganhador do Nobel, já que vários países latino-americanos com menor população e menor PIB tinham inclusive mais de um Nobel. Um dos membros do comitê comentou “vocês, brasileiros, são destruidores de heróis”. Infelizmente isso é um fato que continua presente em nosso cotidiano.
Na época que eu conheci as comunidades de alto QI, 1999, alguns nomes famosos eram William James Sidis, Marilyn vos Savant, Chris Langan, Rick Rosner, Grady Towers etc. Langan era segurança numa boate, Rosner era modelo nudista e também trabalhou algum tempo como segurança, Grady Towers era segurança em um parque e teve uma morte trágica e prematura em 2000. Sidis passou suas últimas décadas de vida em subempregos e colecionando placas de carro. Marilyn foi colunista de uma revista e conseguiu um padrão de vida razoável com isso, bem como um bom prestígio e reconhecimento fora das comunidades de alto QI, e também muitos invejosos odiosos. Com exceção de Marilyn, as outras pessoas que citei ganhavam um salário mínimo e ainda passavam parte do tempo sem emprego, enquanto muitas pessoas são contratadas para ocupar cargos que elas nem sequer estão qualificadas, ganhando pequenas fortunas, além de prestígio e reconhecimento.
Essa situação é muito triste. Embora Langan não fosse o homem mais inteligente das Américas, como ele reivindicava em 2000, ou da história do mundo, como ele começou a reivindicar algum tempo depois, ele é indiscutivelmente uma pessoa muito mais inteligente e mais competente do que 99% dos Ph.Ds. em qualquer área e mais do que 99,9% dos CEOs das empresas. Ele talvez não tivesse uma cultura tão vasta e os conhecimentos especializados necessários para resolver grandes problemas científicos, mas certamente ele daria melhores soluções administrativas e políticas do que qualquer presidente que os EUA já tiveram. Eu não sei se ele seria o melhor presidente, porque ser um excelente presidente não se resume a resolver problemas. Ele precisaria também ter sensibilidade, empatia, bondade, honestidade e outros atributos. Mas geralmente muitas pessoas têm esses atributos no nível necessário. O que normalmente falta a elas é exatamente a inteligência. Eu não estou dizendo que Langan ou Rosner deveriam ser presidentes. Mas, ponderando sobre pontos positivos e negativos, eu apostaria neles como presidentes melhores que a média dos presidentes recentes.
A perseguição e a opressão algumas vezes podem acontecer de maneira silenciosa, e isso costuma ser até pior, porque é mais difícil de detectar e combater. Como é possível que uma pessoa com o potencial intelectual de Langan não tenha sido descoberto por uma grande empresa que o contratasse pagando um salário milionário para que ele resolvesse os problemas internos de modo a gerar mais lucro para a empresa do que outras pessoas menos competentes trabalhando na mesma função? Há erros grotescos nisso. A grande maioria das empresas está contaminada por multidões de incompetentes e trapaceiros, que em vez de contratar e promover com base nos méritos, fazem quase exatamente o contrário, porque se sentem ameaçados por quem é mais competente do que eles. Isso é um completo desastre não só para as empresas nas quais eles trabalham, mas para toda a harmonia da civilização. Na Noruega, na Suécia, na Holanda, na Finlândia, na Suíça, na Dinamarca etc. esses problemas são muito raros, mas no brasil isso é uma constante que afunda o país. Nos EUA talvez o problema não seja tão grave quanto é no brasil, mas quando olhamos para os casos de Langan e Rosner, fica claro que há falhas graves na atuação dos headhunters, deixando de contratar algumas das pessoas mais capacitadas do país, que passaram a maior parte da vida em atividades subprofissionais. Eu citei os exemplos de Langan e Rosner, mas o mesmo vale para um grande número de pessoas com QI muito acima da média, que estão trabalhando em atividades incompatíveis, com rendimentos muito abaixo do que merecem, produzindo menos do que deveriam, enquanto pessoas muito menos capacitadas estão em cargos elevados, cometendo erros absurdos e afundando empresas ou até mesmo afundando nações inteiras. Minha namorada é engenheira ambiental e excepcionalmente inteligente, ela trabalhou numa empresa de grande porte onde ela resolvia problemas que economizavam mensalmente dezenas de milhares de dólares cortando desperdício, além de contribuir para reduzir a poluição. Uma das soluções envolvendo a substituição de um duto gerou uma economia de alguns milhões. Se ela fosse colocada num cargo mais elevado, no qual a atuação dela tivesse maior alcance, poderia poupar dezenas ou centenas de milhões para empresa. Entretanto, ela foi convidada para participar de um esquema de corrupção, ela se recusou, a pessoa que fez o convite ficou com receio de que ela os denunciasse e a demitiu.
Em “A República”, Platão comentava sobre a importância de que os reis fossem filósofos e os filósofos fossem reis. Isso me parece o mais natural, substituindo “filósofos” por “competentes” o que geralmente é quase sinônimo de “inteligentes”. E substituindo “reis” por um significado moderno equivalente, que pode ser CEO de grandes empresas, prefeitos, governadores e presidentes. Nos EUA há vários mecanismos para descobrir e orientar crianças e jovens talentosos, há vários programas especializados. De acordo com Eunice Maria Lima Soriano de Alencar, nos anos 1970 havia mais de 1200 programas educacionais para crianças superdotadas nos EUA. Como é possível que esses programas tenham “deixado escapar” Langan e Rosner? Como uma entidade respeitada como instituto Hollingworth não os descobriu? Não é possível que eles não tenham se destacado na escola. No brasil eu acharia normal isso, o brasil deixa quase todos os grandes talentos escorrerem pelo ralo. Mas nos EUA acho surpreendente que isso tenha acontecido. Há registros de que Langan teve escore perfeito no SAT e recebeu bolsas de estudo em duas universidades, mas parece que ele perdeu a bolsa porque chegou atrasado um dia, porque seu carro quebrou. Isso é bastante ridículo. Mesmo que ele faltasse em todas as aulas, provavelmente ele aprenderia mais e melhor do que 99% dos colegas que estivessem presentes em todas as aulas. As universidades não concederam bolsas como reconhecimento pela genialidade dele, mas como uma “esmola”, com condições restritivas de retirar a esmola se ele não cumprisse determinados critérios.
Esse desperdício de grandes talentos é um dos principais motivos que leva um país à ruína. A China está alcançando e superando os EUA em grande parte porque a China tem investido mais seriamente e mais pesadamente em educação especial de crianças talentosas, enquanto os EUA estão cometendo erros grosseiros como esse, deixando que grandes mentes como a de Langan, Rosner, Towers sejam desperdiçadas em trabalhos como segurança de boate ou de parque, enquanto pessoas menos capacitadas lideram grandes empresas, governam cidades e estados.
O nepotismo não é um fenômeno exclusivamente familiar. É muito mais abrangente, levando à colocação de pessoas subqualificadas em cargos que deveriam ser ocupados por outras com mais méritos. Não há otimização na delegação de cargos, responsabilidades, tarefas, incentivos, prêmios etc. E essa ausência de otimização é obviamente penalizada. Concorrentes que otimizam melhor isso, assumem a liderança.
No Brasil a situação é muito mais grave, porque não existem tais programas. Houve algumas poucas iniciativas isoladas, que chegavam a atender poucas dezenas de crianças, mas que não duraram muito tempo.
Os testes de inteligência são extremamente importantes para serem utilizados nesses processos de descobertas de talentos. Ainda que os testes apresentem várias falhas, é melhor que sejam aplicados na medida do possível, com os erros e remendos, do que se deixassem de ser aplicados e essa calamidade se perpetuasse. Algumas das gigantes de tecnologia criam seus próprios testes para selecionar seus colaboradores, geralmente esses testes não são tão bons quanto os hrIQts, mas pelo menos eles demonstram compreender a necessidade disso. Embora estejam remendando mal o problema, pelo menos estão tentando fazer algo para identificar jovens talentos e engajá-los em projetos relevantes, nos quais possam contribuir para o desenvolvimento da Ciência, da Tecnologia e para o bem comum, portanto essas empresas agem melhor que o governo em relação a isso.
Jacobsen: Quem parece ser os maiores gênios da história para você?
Melão Jr.: Leonardo, Newton, Aristóteles, Gauss, Ramanujan, Arquimedes, Euler e Einstein.
É difícil julgar os casos de Hawking, Galois, Faraday, Al-Hazen e outros, porque Hawking teve que enfrentar dificuldades extremas, é difícil saber qual teria sido a magnitude de seu legado se ele não tivesse adoecido. É possível que Hawking seja uma das 5 ou 10 pessoas mais inteligentes da História, embora sua obra efetiva não seja uma das 100 mais expressivas, por não ser uma representação justa de seu potencial, pois ele infelizmente não teve a oportunidade de “competir” em condições de igualdade com outros grandes gênios. Galois nasceu numa condição muito privilegiada culturalmente, intelectualmente e economicamente, mas infelizmente morreu muito jovem. Isso não significa que ele teria produzido muito mais se tivesse vivido até os 90 ou 100 anos, porque analisando a vida de outros grandes matemáticos e cientistas, a maioria dos trabalhos mais importantes que realizaram foi antes dos 25 anos, eventualmente entre 25 e 30. Além disso, há muitos casos de pessoas que produziram quase tudo que puderam antes dos 20, depois não apresentaram avanço nem acúmulo de produção (Paul Morphy, por exemplo, ou Arthur Rubin). Então a notável precocidade de Galois não indica necessariamente que ele teria produzido mais do que Gauss ou Euler, se tivesse vivido muito mais tempo. Mas mesmo que ele não alcançasse o nível de Euler, é provável que ele teria deixado um legado monumental. Faraday – assim como Edison, Leonardo e eu – não recebeu educação formal, o que pode ser interpretado como uma desvantagem, embora talvez não seja de fato. A vida acadêmica pode atrapalhar, em muitos casos, é difícil julgar com segurança. Para saber se pessoas com QI acima de determinado nível teriam vantagem ou desvantagem estudando como autodidatas, seria necessário realizar experimentos com vários pares de gêmeos com QI no intervalo desejado, em que um entre cada par de gêmeos seria forçado a seguir carreira a acadêmica e o outro forçado a não seguir. Haveria vários problemas para executar tal experimento, porque gêmeos são raros e gêmeos com QI acima de determinado nível talvez simplesmente não exista nenhum caso como exemplo, e o estudo exigiria uma amostra com pelo menos algumas dezenas. Outro problema é a questão ética, de forçar uma pessoa a frequentar a unidade e forçar outra a não frequentar. Isso é especialmente grave no caso de gêmeos monozigóticos, porque provavelmente ambos teriam preferências semelhantes, e algum deles teria que ser “sacrificado” nessa situação, forçado a fazer algo diferente do que gostaria.
Na época em que conheci as comunidades de alto QI, falava-se muito em Sidis como o maior gênio da história, um gênio injustiçado e incompreendido. Há um pouco de verdade nisso, mas também há muitos exageros e distorções. Sidis é um caso incomum e muito difícil de julgar, porque a história dele está misturada com lendas e fantasias. Meu primeiro contato com a “história” de Sidis foi por meio de um artigo de Grady Towers, em 1999, que depois ele modificou em 2000. Hoje sei que havia muitas informações incorretas naquele texto, mas na época eu acreditei no que estava lá, e cheguei a considerar a possibilidade de que Sidis realmente fosse a pessoa mais inteligente da História. Atualmente vejo Sidis como uma vítima de seus pais, um prodígio forçado com talvez 180 a 200 de QI, que poderia ter sido um bom pesquisador e levado uma vida agradável e produtiva, mas foi transformado numa atração circense. O QI 250-300 que durante anos foi atribuído a ele parece ter sido invenção de sua irmã, os 54 idiomas que se afirmava que ele falava foram reduzidos para 52, depois 40, depois 26 e atualmente parece que se considera que ele talvez falasse de fato 15 a 20 idiomas. A lenda sobre ele conseguir aprender 1 idioma em 1 dia parece ser simplesmente falsa. Ele não obteve um Ph.D. Cum Laude em Harvard aos 16 anos, mas sim um B.Sc., o que ainda é uma realização expressiva, mas não tanto. Cerca de 12% dos estudantes de Yale se graduam Cum Laude, Magna Cum Laude ou Summa Cum Laude. Em alguns anos (como 1988) essas porcentagens podem aumentar bastante, chegando a mais de 30%. Eu não sei as porcentagens em Harvard, mas suponho que não seja tão diferente. Então é de fato expressivo, mas não tão impressionante quanto seria esperado por alguém com supostos 250-300 de QI.
A tendência da irmã dele em exagerar quase tudo acaba aumentando o ceticismo sobre quais alegações sobre ele são reais. O fato é que ele não deixou um legado científico nem matemático que justifique a superavaliação que se costuma fazer sobre ele. As ideias dele sobre buracos negros foram precedidas em mais de 100 anos por Laplace e Michell, as ideias dele sobre Evolução já haviam sido mais bem desenvolvidas por Darwin e Wallace, aliás, a abordagem de Sidis é bem mais superficial que a de Darwin e Wallace, sendo mais semelhante à de Anaximandro e Aristóteles. Contudo, permanece a dúvida sobre o nível de produção intelectual que ele poderia ter alcançado se não tivesse se afastado da vida acadêmica, ou, mesmo afastado da vida acadêmica, mas produzindo Ciência e Matemática fora da universidade.
Em termos de precocidade, Gauss, Galois, Neumann e Pascal me parecem mais notáveis que Sidis, inclusive porque Gauss foi um prodígio natural, enquanto Sidis foi uma mistura de prodígio natural e prodígio forçado. Galois, Pascal, Neumann também foram prodígios naturais e forçados, mas não tão forçados quanto Sidis. Essa pressão a que Sidis foi submetido talvez o tenha prejudicado e provocado o desfecho que essa novela acabou tendo. Acho difícil avaliar.
Por isso se essa pergunta me tivesse sido feita em 2000, talvez eu fizesse uma análise menos crítica e mais superficial e apontasse Sidis como o maior gênio. Atualmente eu teria dúvidas inclusive se ele teria escore muito alto nos hrIQts, talvez ele chegasse a 190 em alguns testes, mas em outros não passaria de 180. No que diz respeito à produção intelectual, os registros não mostram nada tão extraordinário.
Jacobsen: O que diferencia um gênio de uma pessoa profundamente inteligente?
Melão Jr.: habitualmente o conceito de “gênio” é utilizado para indicar capacidade excepcional em diferentes áreas científicas, artísticas, esportivas, culturais etc. Nesse contexto, uma das principais diferenças seria o nível de especificidade, pois o gênio poderia indicar um talento notável em qualquer área de atuação (Música, Futebol, Ballet etc.), inclusive atividades nas quais não seja exigida inteligência em alto nível. Em contraste a isso, a pessoa profundamente inteligente teria seu talento ligado exclusivamente a atividades nas quais a notabilidade exija nível intelectual muito elevado (Física, Matemática, Literatura, Xadrez etc.).
Mas esse conceito é inadequado, em minha opinião, porque com o desenvolvimento de máquinas que superam os melhores humanos em diferentes modalidades, torna-se importante não misturar máquinas “inteligentes” com outras máquinas. Poderia parecer aceitável dizer que Usain Bolt é um gênio do atletismo, mas seria estranho dizer que um Bugatti Chiron é um gênio, embora o que o Chiron faz excepcionalmente seja o mesmo que Usain Bolt faz. Por isso é necessário determinar critérios objetivos de classificação que sejam aplicáveis igualmente a todas as entidades orgânicas e inorgânicas, sem discriminação, um critério que funcione bem e não produza classificações bizarras. Não seria razoável dizer “ah, Chiron é um carro, portanto critério não se aplica a ele”. Isso seria uma discriminação rasa e incorreta, porque em poucas décadas haverá carros capazes de conversar sobre Filosofia e demonstrar teoremas matemáticos, inclusive híbridos que sejam parte humanos e parte carros, e se um dos critérios para ser considerado genial for “não pode ser um carro”, haveria uma grave inconsistência. Um critério sério e justo precisa ser bem planejado, não pode ser um palpite ingênuo que não contempla as possíveis exceções.
Os talentos para modalidades intelectuais, quando atingem determinado nível de excelência (algo como 5 desvios padrão acima da média) podem ser considerados “gênios”, mas para atividades nas quais o nível intelectual não desempenha um papel importante (Boxe, Futebol, Atletismo etc.), creio que o termo correto deveria ser escolhido com mais cuidado, para evitar que máquinas não intelectuais sejam incorretamente classificadas como “gênios” (um carro veloz ser classificado como “gênio” por ser veloz me parece um erro etimológico, mas se este carro pudesse realizar tarefas intelectuais, a situação mudaria). Em algumas circunstâncias, as máquinas precisam ser reconhecidas como gênios, caso contrário haverá inconsistências graves na sintaxe do idioma, apoiadas exclusivamente em preconceito contra máquinas. AlphaZero ou MuZero, por exemplo, em minha opinião eles (especialmente MuZero) se encontram numa “zona cinza” de difícil avaliação. MuZero pode aprender sozinho a jogar Xadrez, Go, Shogui, jogos de Atari, e alcançar nível muito alto, superior ao dos melhores humanos do mundo em alguns desses jogos, que são reconhecidos como jogos intelectuais. Por isso uma tentativa de ajuste post facto nos critérios, com o único propósito de desqualificar MuZero como um gênio, isso me pareceria um sinal de discriminação injusta. Mesmo porque, as próximas gerações de MuZero tendem a apresentar cada vez melhor o que entendemos como “inteligência geral”, e em algum momento não haverá como evitar reconhecer que algumas máquinas também precisam ser classificadas como “inteligentes”.
A dúvida é se caberia melhor a MuZero a classificação de “idiot savant” ou de “gênio”. A meu ver, seria melhor “gênio”, porque idiot savants normalmente não são muito criativos e não se sobressaem em atividades que exijam resolver problemas sofisticados e profundos. São muito bons em memorizar e repetir, sejam cálculos mentais ou execuções de músicas, mas não conheço nenhum caso de idiot savant que tenha se destacado como enxadrista ou como cientista. Talvez fosse possível reformular os significados de gênio e de idiot savant de maneira que MuZero ficasse mais bem classificado como savant, sem comprometer a essência desses significados. Uma classificação adequada não poderia “empurrar” Bobby Fischer ou Kasparov para o grupo de savants, por exemplo. A classificação precisaria ser cuidadosa, para não criar inconsistências com o único objetivo de remover MuZero do grupo de gênios, nem apresentar outros tipos de arbitrariedades.
Em algumas outras atividades nas quais não há necessidade de um intelecto excepcional, sendo suficiente QI perto de 120 aliado a um talento excepcional para uma área específica, creio que o termo “gênio” não deveria ser aplicável. Mike Tyson ou Usain Bolt não precisam de muito mais que 120 de QI, e alguns veículos sem qualquer traço de inteligência, que não pensam, podem vencer Bolt na modalidade que ele se notabilizou, então a excelência nessa modalidade talvez não deva ser encarada como “genialidade”.
Em alguns casos é mais difícil avaliar se o termo “gênio” seria ou não aplicável. Sistemas de Inteligência Artificial como AIWA, que é especializada em compor músicas, e faz isso num nível muito alto, a meu ver, também não deveria ser classificado como “gênio”, e nesse caso os grandes compositores humanos também não deveriam ser classificados como “gênios” com base exclusivamente em seu talento para compor. Se esse talento para compor músicas estivesse acompanhado de um nível intelectual compatível com o critério intelectual de genialidade, então a classificação como “gênio” seria aplicável com base nisso. O mesmo valeria para lutadores de Boxe, agricultores ou profissionais de qualquer área, que não seriam classificados como “gênios” com base em seus talentos para suas atividades de maior destaque, mas sim por sua inteligência.
Nessa acepção, poderia haver gênios latentes e gênios efetivos. A genialidade latente estaria no potencial intelectual de produzir contribuições relevantes para ampliar os horizontes do conhecimento, revolucionar os paradigmas científicos, etc. Enquanto o gênio efetivo seria aquele que concretamente faz essas coisas. Uma pessoa profundamente inteligente, que não tenha realizado contribuições notáveis, poderia ser um gênio latente, tendo em aberto a constante oportunidade de se tornar um gênio efetivo, a partir do momento que utiliza seu potencial para o desenvolvimento científico, ou para inovações em matemática ou em algum campo importante do conhecimento.
Algumas pessoas consideram que a diferença fundamental entre um gênio e uma pessoa profundamente inteligente está na criatividade, mas a criatividade é um dos componentes da inteligência. As pessoas muitas vezes confundem o raciocínio lógico (que também é um dos componentes da inteligência) com a própria inteligência. Mas o comportamento inteligente é uma combinação ampla de muitos processos cognitivos, inclusive memória e criatividade.
A diferença entre “gênio” e “profundamente inteligente” é mais quantitativa e está associada às proporções em que estão presentes determinados atributos. A criatividade aparece no gênio como um elemento fundamental, mas não porque o gênio seja criativo e a pessoa profundamente inteligente não seja (ambos são), ou sequer porque o gênio seja sempre mais criativo (embora geralmente seja). No conjunto de atributos, considerando raciocínio lógico, criatividade, memória de trabalho, memória de longo prazo etc., o gênio possui e utiliza esse conjunto de traços latentes na resolução de problemas inéditos com maior eficiência. Como a criatividade geralmente é um dos quesitos mais importantes para isso, acaba sendo natural associar a genialidade à criatividade.
Jacobsen: A inteligência profunda é necessária para o gênio?
Melão Jr.: Para o conceito de gênio que descrevi, sim. Na resposta anterior acabei respondendo a essa.
Jacobsen: Quais foram algumas experiências de trabalho e empregos que você teve?
Melão Jr.: Desde 2006 trabalho no desenvolvimento de sistemas de inteligência artificial para operar no Mercado Financeiro. Atualmente estou interessado em resolver o problema de prolongar a vida indefinidamente, preservar a memória e a identidade em dispositivos inorgânicos que tenham uma interface adequada de comunicação com o cérebro, ressuscitar pessoas, restaurar corpos severamente danificados e outros problemas menores que são subconjuntos desses e pré-requisitos para esses.
Jacobsen: Por que seguir esse caminho de trabalho específico?
Melão Jr.: o desenvolvimento de sistemas automáticos para operar no Mercado Financeiro é uma atividade desafiadora intelectualmente e oferece uma recompensa monetária razoavelmente justa, embora a ausência de uma network empresarial imponha muitos obstáculos. O nível de dificuldade, complexidade e profundidade dos problemas que precisam ser resolvidos para obter lucros consistentes a longo prazo com operações long-short é extremamente elevado. Há algumas maneiras fáceis de ganhar 3% ao ano ou pouco mais, praticando Buy & Hold do índice ou de Blue Chips, em que o ganho é pequeno, mas muito fácil. Porém se a pessoa quiser lutar para obter lucros perto de 30% ao ano ou acima, o desafio é extraordinariamente difícil e poucas pessoas no mundo conseguem isso de fato. Como parte desse trabalho, fiz alguns avanços interessantes em Econometria e Gerenciamento de risco. Em 2007, solucionei um problema que havia sido resolvido de forma insatisfatória durante 22 anos, ao criar um índice para medir o desempenho ajustado ao risco que era mais acurado, mais preditivo e conceitualmente mais bem fundamentado do que os índices tradicionais de William Sharpe (prêmio Nobel 1990) e Franco Modigliani (Nobel 1985). Em 2015 mostrei que o método recomendado pelo Prêmio Nobel de Economia Harry Markowitz, para otimização de portfólio, apresenta algumas falhas, e propus algumas melhorias que tornam esse método mais eficiente e seguro. Em 2021 apontei falhas na recomendação do Prêmio Nobel de Economia de 2003, Clive Granger, quanto ao uso do conceito de cointegração, e apresentou uma solução mais adequada para o mesmo problema. Entre outras contribuições em processos de otimização de algoritmos genéticos, ranqueamento e seleção de genótipos, reconhecimento de padrões etc.
Jacobsen: Quais são alguns dos aspectos mais importantes da ideia de superdotados e gênios? Esses mitos que permeiam as culturas do mundo. Quais são esses mitos? Que verdades os dissipam?
Melão Jr.: parece haver diferentes mitos entre diferentes estratos intelectuais. Para a maior parte da população, com QI abaixo de 130, parece que pensam no gênio como uma pessoa maluca, reclusa, antissocial, fisicamente frágil, e todos os defeitos físicos e psicológicos que eles conseguem imaginar, como uma necessidade mórbida de empurrar para baixo a pessoa por não tolerarem o fato de que ela se sobressai em alguma coisa e ainda por cima ter pequena vantagem em quase tudo. Muitos filmes, livros e revistas tentam reforçar esse estereótipo. Mas há outras ideias incorretas que são disseminadas em outras faixas de QI. No nível de 130 a 180, por exemplo, parece haver uma supervalorização dos resultados em testes de QI, sem uma compreensão correta sobre os limites de até que ponto esses testes produzem escores acurados e fidedignos.
Outro mito está relacionado ao nível de raridade. Pessoas que não tenham noções de Psicometria (quase todas fora das sociedades de alto QI) acham que superdotados são muito raros, algo como 1 em 1 milhão ou até mais raros. Eles geralmente também não têm noção da diferença entre “superdotado” e “gênio”, inclusive alguns acham que superdotado é mais inteligente do que gênio.
Jacobsen: Alguma opinião sobre o conceito de Deus ou a ideia de deuses e filosofia, teologia e religião?
Melão Jr.: minha família era católica. Eu me tornei ateu aos 11 anos, depois de estudar sobre algumas religiões. Num processo de transição que durou alguns anos entre os 17 e 25 anos, acabei me tornando agnóstico. Eu cheguei a me interessar pela Fé Bahá’í aos 27 anos e aos 28 me tornei deísta e escrevi um artigo no qual apresento argumentos científicos sérios sobre a existência de Deus. Digo “argumentos sérios” porque todos os argumentos pseudocientíficos que conheço sobre o assunto são tentativas desesperadas de “provar” uma crença a priori. É diferente de uma análise imparcial que conduz a uma conclusão que não havia servido como motivação inicial. Continuo sendo deísta, cheguei a fundar minha própria religião e estou escrevendo um livro sobre o assunto.
Jacobsen: Quanto a ciência influencia na visão de mundo para você?
Melão Jr.: A Ciência é o único caminho que conhecemos por meio do qual se pode desenvolver modelos adequados para representar a realidade senciente, modelos funcionais, capazes de fazer generalizações e previsões, em que os resultados obtidos são razoavelmente conforme as previsões, sem que as previsões dependam da sorte para acertos casuais. A Ciência é imprescindível no processo de aquisição do conhecimento e desenvolvimento tecnológico. Por outro lado, é importante compreender as limitações da Ciência, como um corpo de disciplinas que nos oferece um método valioso, mas que não está imune a falhas. O grande diferencial da Ciência não está no conhecimento que ela produz, mas sim no método que permite que ela se corrija a si mesma e faça isso constantemente, atualizando-se, refinando-se, ampliando-se etc., de modo que todo o conhecimento científico, mesmo que seja fundamentalmente incorreto, tem alguma utilidade prática e funciona razoavelmente bem dentro dos limites que a Teoria da Medida estabelece. O modelo cosmológico de Ptolomeu, por exemplo, mesmo sendo fundamentalmente errado, permitia fazer previsões muito acuradas. Algumas vezes as teorias científicas podem não representar estruturalmente de forma acurada os fenômenos naturais, mas ainda que as explicações teóricas não sejam as mais corretas, elas funcionam. Os conhecimentos obtidos por outros meios, como a Filosofia, a Religião ou a cultura popular, geralmente têm menor probabilidade de “funcionar”, e mesmo quando funcionam, é difícil regular os parâmetros que determinam seu funcionamento, devido à ausência de uma teoria subjacente que esteja organizada por um modelo matemático.
Jacobsen: Quais foram alguns dos testes realizados e pontuações obtidas (com desvios padrão) para você?
Melão Jr.: não há uma resposta simples a essa pergunta. Aliás, entre todas as perguntas dessa entrevista, talvez essa seja a mais difícil, porque além de dar uma resposta correta, preciso tentar ser diplomático para não parecer muito arrogante. Minha namorada já me perguntou dezenas de vezes qual é o meu QI, Tor já me perguntou isso pelo menos 5 vezes, e eu geralmente me esquivo do assunto, porque é demorado ter que explicar tudo. Mas eu vou responder aqui e quando outras pessoas me perguntarem novamente, eu vou fornecer o link dessa resposta, inclusive porque em questões anteriores e no texto introdutório comentei um pouco sobre testes clínicos, hrIQts, estimativas e comparações. Com isso, creio que será possível expressar minha opinião sobre esse tema de forma razoavelmente completa e acurada em menos de 50 páginas, aproveitando as respostas anteriores como pré-requisitos.
Fui examinado pela primeira vez aos 3 anos de idade, e cheguei até os testes para 9 anos, porque não tinham acima de 9 anos para crianças que não sabiam ler. Eu não sei qual o nome dos testes, mas o desvio padrão provavelmente era 24. Há vários pontos complexos que precisam ser examinados sobre isso, porque a evolução da inteligência em função da idade não é linear, como na fórmula simplificada de Stern, o desvio padrão não é 24 em todas as faixas etárias abaixo de 16 anos, a maioria das crianças muito jovens examinadas são prodígios forçados que os pais tentaram ensinar muita coisa desde que nasceram, mas não foi assim no meu caso, meu pai saía para trabalhar antes de eu acordar e voltava depois que eu já estava dormindo, minha mãe trabalhava quase o dia todo, por isso nenhum deles tinha sequer tempo para ficar muito comigo, quanto menos para me treinar como um prodígio forçado. Outros pontos a considerar são que o desenvolvimento intelectual não termina aos 16 anos (nem 17 ou 18 ou 19), nem chega ao limite numa idade fixa para todas as pessoas, nem permanece estável ao chegar em determinada idade. Portanto a interpretação de que a idade mental de 9 anos aos 3 anos corresponde a um ratio IQ 300 é grosseiramente incorreta e ingênua. Mesmo depois de converter a escala com desvio padrão 24 para 16, chegando a 233, continua incorreta. A curva de evolução da inteligência em função da idade também varia de uma pessoa para outra. Por isso não é razoável tomar como base testes aplicados na infância para tentar estimar qual será o QI em idade adulta. Há vários casos de QIs medidos na infância que se mostram muito distantes dos corretos em idade adulta, embora alguns possam “acertar por sorte”, como no caso de Terrence Tao, que teve o QI medido em 230 e, por sorte, realmente o QI dele está perto disso. No meu caso, é possível que também o QI medido tenha chegado perto do valor correto “por sorte”, mas os testes utilizados, o método utilizado, etc. não são apropriados.
Outro detalhe é que eu não sei se eu continuaria resolvendo as tarefas típicas de crianças com mais de 10 anos, mas é possível que sim, porém a precocidade em resolver tarefas típicas de crianças mais velhas não diz quase nada, ou diz muito pouco, sobre o nível intelectual que será alcançado em idade adulta, porque as habilidades medidas não fornecem informações úteis para esse tipo de prognóstico. O tipo de habilidade que indicaria um nível intelectual muito alto (200+) em idade adulta não tem relação com o mesmo tipo de tarefa que uma criança de 8, 9 ou 10 anos, ou mesmo 20 anos, poderia realizar, mas sim com a solução de problemas que indicassem traços de criatividade e pensamento profundo para aquela idade. O evento na aula de Geografia aos 9 anos, por exemplo, foi um indicativo muito mais relevante do que o resultado do teste aos 3 anos, não apenas porque aos 9 anos já havia alcançado maior maturidade e estava mais perto do potencial que teria quando adulto, mas também, e principalmente, porque o tipo de problema envolvido estava mais estreitamente relacionado aos processos cognitivos necessários a adultos geniais.
Conforme comentei no texto introdutório, em outras respostas, em alguns artigos e em alguns fóruns, os testes de QI e os hrIQts apresentam problemas na validade de constructo, erros no cálculo da norma e inadequação do nível de dificuldade. Eu já tive uma experiência muito ruim com Paul Cooijmans em 2001 e eu não pretendo voltar a perder tempo com isso. O Space, Time & Hyperspace (STH) de Cooijmans propunha medir o QI até 207 (σ=16), embora a dificuldade real das questões mais difíceis desse teste não seja muito maior que 170. Mas isso não é o principal problema. O STH contém vários erros primários que invalidam completamente o teste e a norma, embora muitas pessoas o considerem um dos “melhores” hrIQts. Em 2001 escrevi para Cooijmans sobre isso e apontei a ele um desses erros, mas ele se recusou a conversar a respeito disso e não admitiu o erro dele. Eu não tenho paciência para lidar com pessoas que agem como ele. Vou descrever exatamente qual o problema usando um exemplo:
O enunciado geral para todas as questões do STH era a seguinte:
a : b :: c : d
Significando: “a” está para “b” assim como “c” está para “d”.
Dados “a, b, c” determine “d”.
O enunciado, juntamente com o teste, podem ser acessados em https://web.archive.org/web/20040812113534/http://www.gliasociety.org/
Segue um print do que está no link acima:

O enunciado geral diz que há uma relação da 1ª figura para a 2ª figura que deve ser descoberta e, em seguida, essa mesma relação deve ser aplicada na 3ª figura para produzir a 4ª figura. Esse é o único enunciado geral para todas as questões desse teste, apresentado no início do teste, e funciona assim nas questões 1 até 9, mas não é assim na questão 10 nem em 16 outras questões entre as 28 que constituem esse teste.
Ele queria que na questão 10 fosse descoberta a relação da 1ª figura para a 3ª figura e, em seguida, essa mesma relação fosse aplicada na 2ª figura para produzir a 4ª figura! Mas em nenhum momento ele pediu isso no enunciado. O que o enunciado pede é exatamente o que descrevi acima. Se a pessoa responde exatamente o que o enunciado está pedindo, a pessoa perde 1 ponto!
Há várias outras questões no STH com esse mesmo erro básico de lógica. Nessa situação surreal, se a pessoa acertar todas as 28 questões exatamente em conformidade com o que pede o enunciado do teste, a pessoa receberá apenas 11 certos e terá escore 135 em vez de 205 pela norma atual, ou 140 em vez de 207 pela norma antiga.
Como Cooijmans não aceitou conversar a respeito disso, eu conversei (na época) com 3 outras pessoas capacitadas para opinar: Petri Widsten, Albert Frank e Guilherme Marques dos Santos Silva.
Petri Widsten teve o escore mais alto no Sigma Test, no STH e foi campeão em vários concursos de lógica e de QI, inclusive http://www.worldiqchallenge.com/rankings.html, onde Petri teve quase o dobro do escore bruto de Rick Rosner. Petri rapidamente concordou comigo sobre isso, inclusive com prejuízo para as próprias respostas dele, porque ele havia respondido o que ele achava que o Cooijmans gostaria de receber como resposta, não o que seria a resposta mais certa. Todas as vezes que me lembro desse assunto, fico estressado, porque Cooijmans é uma pessoa muito teimosa. Eu não acho que Cooijmans seja estúpido ou desonesto; eu acho que ele é inteligente e ele tenta fazer o que ele acredita ser certo, mas a teimosia dele é maior do que a inteligência dele.
Albert Frank foi professor de Lógica e Matemática na Universidade de Bruxelas, campeão veterano de Xadrez na Bélgica. Albert também concordou comigo e fez alguns comentários sobre Lógica formal que categorizam o tipo de erro cometido pelo Cooijmans.
Guilherme Marques dos Santos Silva é membro de Sigma V e foi campeão no concurso de QI “Ludomind International Contest IV”, também concordou comigo e “desistiu” de terminar de fazer o STH depois que viu esse erro absurdo. Ele disse que faltavam poucas questões para terminar, mas devido ao grave viés na correção, não teve interesse em prosseguir.
Além das pessoas com as quais conversei naquela época, também conversei recentemente com Tianxi Yu sobre esse tipo de problema. Yu tem escore 196, σ=15 no Death Numbers, que é considerado um teste sério e com norma desinflada. Ele comentou que já encontrou erros em vários testes, e ele postou uma extensa e detalhada crítica pública sobre isso em um grupo, citando os diversos tipos de erros que o incomodam. Há vários pontos nos quais discordo das opiniões de Yu, mas em relação aos testes, nossas opiniões são muito semelhantes.
Logo que tomei meu primeiro contato com as sociedades de alto QI e conheci o site do Miyaguchi (1999), cheguei a me interessar em fazer o Power Test, que eu considero um dos melhores em termos de validade de constructo e com nível adequado de dificuldade. Na época eu tinha 27 anos e uma opinião diferente da atual, eu tinha três objetivos com o Power Test: um deles era a diversão, outro era bater o recorde de Rick Rosner de QI~193 e o terceiro era entrar em Mega Society. Naquela época era utilizada a norma calculada por Garth Zietsman para o Power Test, com teto 197, mas antes de eu terminar de resolver todas as questões, o Power Test deixou de ser aceito em Mega Society e o teto foi “revisado” para 180. Então eu perdi completamente o interesse.
Garth Zietsman é um estatístico competente e a norma que ele calculou, provavelmente utilizando Teoria de Resposta ao Item, é consistente e muito bem fundamentada. Se os mesmos itens utilizados no Mega, Titan e Ultra estavam no Power, então as dificuldades individuais desses itens foram mantidas e determinavam a norma do Power. Por isso quando o teto do Power Test foi modificado para 180, isso foi um erro. Simplesmente foram desconsideradas as mais de 4.000 aplicações do Meta, Titan e Ultra, que serviram de base para a norma calculado por Zietsman, e foi calculada uma nova norma baseada em poucas dezenas de pessoas. O procedimento correto seria somar os novos dados (sobre os resultados de cada item respondido pelas pessoas examinadas com o Power) ao banco de itens que continha as questões do Mega, Titan e Ultra, calibrar novamente os parâmetros de dificuldade, poder discriminante e acerto casual (se aplicável) de cada item, então revisar as normas dos 4 testes de Hoeflin que compartilhavam aqueles itens. Assim os níveis de dificuldade seriam preservados igualmente em todos os testes, mantendo uma escala unificada.
Mas da maneira como foi feito, a norma do Power ficou distorcida para baixo em relação aos outros três testes de Hoeflin. Para esclarecer melhor o problema, vou citar um exemplo: no Power Test a questão sobre a fita de Moebius está sendo tratada estatisticamente como se tivesse parâmetro b = +2.81, ou seja, 50% das pessoas com QI 145 (σ=16) devem acertar essa questão. Entretanto, a mesma questão sobre a fita de Moebius ao ser aplicada em outro dos testes de Hoeflin está sendo tratada estatisticamente como se tivesse parâmetro b = 3,88 ou seja, 50% das pessoas com QI 162 (σ=16) devem acertar essa questão. Isso é uma inconsistência grave, porque ou a questão tem dificuldade 2,81 em todos os testes nos quais ela é utilizada, ou 3,88 em todos os testes. A questão não pode ter dificuldade 3,88 em alguns testes e 2,81 em outros. A normatização de Zietsman é consistente nesse aspecto, de modo que o teto do Power produz uma norma na mesma escala em que estão as normas do Mega, Titan e Ultra.
Um dos motivos que provocou essa redução no teto do Power é porque algumas pessoas já haviam levado um ou mais dos outros testes de Hoeflin nos quais os itens do Power estavam presentes, por isso a probabilidade de acertar esses itens na segunda tentativa era maior, aumentando ainda mais na terceira e quarta tentativas. Mas a maneira correta de lidar com isso seria ajustando todas as normas de todos os testes que continham aqueles itens, em função do número de vezes que aqueles itens já haviam sido resolvidos pela pessoa examinada, com normas personalizadas para cada pessoa, ou com base em quantos e quais dos três outros testes a pessoa já havia resolvido (uma equação para isso poderia ser facilmente determinada com o uso de análise de clusters, por exemplo).
Também poderia simplesmente verificar os escores de pessoas que haviam feito mais de um teste (ou o mesmo teste mais de uma vez) e o efeito disso sobre a probabilidade de acertar cada item repetido no segundo, terceiro ou quarto teste que continha o mesmo item. Embora esse ajuste global no conjunto de itens não fosse tão acurado e refinado quanto a análise desse efeito sobre cada item individual, como sugeri acima, isso já ajudaria a aprimorar as normas em todos os 4 testes, em vez de distorcer a norma do Power em relação a todos os outros.
Enfim, há uma quantidade preocupante de erros nos hrIQts, tanto nos cálculos das normas quanto nas respostas aceitas como corretas, entre outros problemas. Por isso o Sigma Test sempre adotou uma política de transparência, sendo aberto a debates, se a pessoa tivesse algum escore acima de 180 em qualquer teste e ela acreditasse que alguma resposta dela estava certa e ela achasse que recebeu uma avaliação incorreta, ela podia contestar a correção de uma questão que ela escolhesse. Se ela tivesse razão, ela podia contestar a correção de mais uma questão, e assim por diante, até que a contestação dela fosse improcedente. O Moon Test e o Sigma Test Extended adotam uma política semelhante de transparência, mas o escore mínimo em outros testes para ter esse direito a contestação é 190 tanto no Moon Test quanto no Sigma Test Extended. Isso permite revisar eventuais erros, além de permitir que a pessoa examinada tenha a oportunidade de defender o que ela considera certo, na hipótese de ela achar que merecia mais pontos do que recebeu. Em minha opinião, todos os testes deveriam adotar uma política semelhante.
Se houvesse algum teste com características apropriadas, eu consideraria a possibilidade de fazer outro teste, embora eu esteja mais velho e mais burro. Basicamente deveria ser um teste com boa validade de constructo nos níveis mais altos, teto apropriado e dificuldade apropriada. Além disso, deveria ter um sistema formal de “reclamação” que permitisse contestar o resultado. Sem isso, não vejo razão para perder tempo com essas coisas. Um hrIQt pode facilmente consumir 50 horas e se for um teste realmente difícil, com nível adequado de dificuldade, pode consumir mais de 500 horas. É um tempo que poderia ser aplicado em atividades mais interessantes e produtivas. Por isso, a menos que o teste reúna uma série de virtudes notáveis que justifiquem o esforço, eu não teria interesse. Na verdade, há um teste que, na minha opinião, atende a esses quesitos, mas eu não posso resolver porque eu sou o autor. Isso me faz lembrar de um assunto que foi discutido há poucas semanas num grupo:

Na verdade, alguns problemas que eu já resolvi são mais difíceis que os problemas mais difíceis do Sigma Test Extented. Então há algumas pistas úteis nisso.
Algumas pessoas já fizeram estimativas de meu QI e já fizeram algumas comparações. Em 2004, o fundador de Pars Society (QI>180), Baran Yonter, estimou meu QI em mais de 200 (σ=16, G), isso é equivalente a mais de 240 pIQ (σ=16, T). Achei que ele estivesse sendo gentil, mas em 2005, quando fui indicado para a produção do programa de TV “Fantástico”, da rede Globo, como a pessoa mais inteligente do Brasil, descobri que outras pessoas tinham opiniões semelhantes à de Baran sobre mim. Eu me senti lisonjeado com as indicações, mas eu não sei se realmente sou a pessoa mais inteligente do Brasil e eu disse isso ao jornalista, mas ele insistiu, e como eu havia sido o mais indicado, e também por uma questão de vaidade, acabei aceitando fazer a matéria, cujo vídeo está disponível em minha página e meu canal.
É necessário fazer uma ressalva importante em relação à correta determinação da pessoa mais inteligente do Brasil, porque há um brasileiro que ganhou uma medalha Fields (Artur Ávila) e há um brasileiro que prestou contribuições fundamentais ao desenvolvimento das lógicas paraconsistentes (Newton da Costa), ambos são pessoas muito inteligentes, mas com perfis diferentes do meu, por isso seria difícil fazer uma comparação adequada para saber com segurança quem é o mais inteligente do Brasil, porque cada um deles é profundamente especializado em uma área muito específica, enquanto meus talentos e realizações se distribuem por uma grande variedade de áreas diferentes. Como resultado da maior especialização, o nível de profundidade que eles alcançaram é maior, mas essa maior profundidade não reflete uma maior profundidade de raciocínio, e sim maior profundidade de conhecimento. Além disso, eu só estudei até o 11º ano, enquanto eles fizeram doutorado e pós-doutorados com excelentes orientadores, o que me coloca numa situação de “correr com as pernas amarradas” em comparação a pessoas que correm montadas em cavalos. As pessoas que trabalharam nos mesmos problemas nos quais eu trabalhei estavam equipadas com ferramentas matemáticas mais sofisticadas, acesso a computadores muito mais potentes, acesso a vasta bibliografia de alta qualidade, receberam treinamento formal muito mais prolongado, intensivo e sob orientação de cientistas experientes, enquanto todo o meu “treinamento” foi auto-administrado, praticamente sem recursos bibliográficos e com modestos recursos computacionais. Muitas vezes precisei criar minhas próprias ferramentas estatísticas antes de usá-las na resolução dos problemas, e depois eu descobria que já existiam ferramentas prontas para as mesmas finalidades. Durante o desenvolvimento de meu sistema para operar no Mercado Financeiro, situações como essa se repetiram muitas vezes.
Um detalhe que é importante esclarecer: eu comentei (no apêndice) que a qualidade média do ensino no Brasil é péssima, então qual seria minha desvantagem por não ter frequentado esse ambiente péssimo? E a resposta é simples: muitos dos melhores acadêmicos brasileiros vão estudar nos melhores centros de pesquisa e universidades da Europa, dos EUA, Canadá, Austrália, Japão etc. Além disso, há alguns poucos pesquisadores realmente bons no Brasil, e quando um jovem talento recebe orientação de um pesquisador de primeira magnitude, isso faz uma diferença muito grande. Portanto há uma vantagem substancial nas oportunidades de Artur e Newton da Costa se comparados com a minha situação, porque eles tiveram acesso a muito mais recursos, além das vantagens em orientação e treinamento.
Em relação às outras pessoas que trabalharam nos mesmos problemas que eu, e eu resolvi esses problemas antes delas ou melhor do que elas ou as duas coisas, quase todos são de outros países: Nick Trefethen é Chefe do Dep. de Cálculo Numérico na Universidade de Oxford e coleciona alguns prêmios internacionais de Matemática (Leslie Fox Prize 1985, FRS Prize 2005, IMA Gold Medal 2010), Susumu Tachi é Professor Emérito na Universidade de Tóquio e Professor Convidado no MIT, Stefan Steinerberger é professor de Matemática em Yale, William Sharpe é professore na Universidade da Califórnia e Nobel de Economia em 1990, Franco Modigliani é Professor na Universidade de Roma e Nobel de Economia em 1985, Clive Granger foi professor na Universidade de Nottingham e Nobel de Economia em 2003, entre outros. Então as pessoas que trabalharam em alguns dos problemas que eu resolvi constituem uma “concorrência de peso”, além de eles terem acesso a mais recursos, mais assessores etc., portanto acho que eu ter realizado trabalhos melhores que os deles, ou ter solucionado problemas relevantes antes deles, talvez represente algum mérito para mim, eu não tenho falsa modéstia em admitir isso.
O fato é que a determinação correta da pessoa mais inteligente de um país não é algo tão simples, não é um jogo de egos e vaidades. É necessário que haja embasamento real para isso. Por exemplo, eu acho que Petri Widsten tem excelentes chances de ser a pessoa mais inteligente da Finlândia, não apenas pelo excelente resultado dele no Sigma Test, mas também porque a tese dele de doutorado, além de muito inovadora, foi premiada como a melhor tese do país no biênio 2002-2003 e ele venceu vários concursos de lógica. O conjunto desses resultados, e outros detalhes menores, como ele ser fluente em mais de 10 idiomas, sugerem um nível intelectual real com raridade acima de 1 em 5 milhões, que é a população da Finlândia. Entretanto há outras pessoas muito inteligentes na Finlândia, como Rauno Lindström ou Bengt Holmström. Embora a Finlândia seja um país culturalmente mais homogêneo, de modo que não há uma diferença de oportunidades tão grande quanto no meu caso, ainda assim a comparação ainda é difícil, por isso não seria prudente afirmar categoricamente que determinada pessoa (Petri ou Rauno ou outro) é a mais inteligente da Finlândia. O mais apropriado seria atribuir uma probabilidade a cada um. Petri teria em torno de 95% de probabilidade de ser a pessoa mais inteligente da Finlândia, Talvez Rauno 2%, Bengt 1% e alguém entre as outras pessoas 5 milhões de pessoas 2%. No caso do Brasil, minha vantagem seria bem menor que a do Petri em relação aos outros fortes candidatos.
Em 2005, o amigo Alexandre Prata Maluf, membro de Sigma V, Pars Society e OlympIQ Society, estimou que meu QI deveria ser semelhante ou pouco acima do da Marilyn Vos Savant. Creio que a intenção dele foi fazer um elogio, porque a Marilyn é um ícone nas sociedades de alto QI, mas não gostei da comparação, porque não é uma comparação justa. Os problemas do mundo real que eu já resolvi são muito mais difíceis do que os problemas que ela resolveu. Não excluo a possibilidade de que ela talvez tenha um QI similar ao meu, mas ela precisaria provar isso com resultados concretos, solucionando problemas com grau de dificuldade compatível.
Recentemente, tomei conhecimento de que em 2018, num grupo privado, meu nome havia sido indicado numa postagem com título “Name the top 5 people (alive) with the highest measured IQs in the world today! Name, IQ and Test.” Achei surpreendente eu ter sido citado, porque desde 2006 eu estava afastado das sociedades de alto QI e só retornei há poucos meses, em fevereiro de 2022, mesmo assim Rasmus Waldna, da Suécia, muito gentilmente se lembrou de mim e sugeriu meu nome, e a indicação dele recebeu mais curtidas do que receberam os nomes de Terence Tao, Chris Hirata, Rick Rosner, Marilyn e Langan. Também foram indicados os nomes dos amigos Tor e Iakovos. Compreendo que foi um tópico informal, e as reações positivas das pessoas podem ter sido influenciadas por fatores extrínsecos à capacidade intelectual, algumas pessoas podem ter curtido por simpatia, por exemplo, ou porque gostam do meu cabelo, mas mesmo assim fiquei feliz com a lembrança e o reconhecimento, e feliz também por ver alguns amigos nessa lista.
Em 2001, David Spencer me comparou a Leonardo Da Vinci e Pascal. Em 2016 o amigo João Antonio L.J. me comparou a Newton e Galileu, e a maneira como ele escreveu e no contexto em que foi dito, achei um elogio comovente e sincero. Em 2017, novamente fui comparado a Leonardo (por Aurius). Em 2020, a revista Empiricus publicou um artigo de Bruno Mérola sobre gerenciamento de risco, no qual o autor comparou meu Melao Index com o índice de Sharpe (Nobel de 1990), e na análise que ele fez, apresentou fatos e argumentos demonstrando que meu índice é superior ao índice de Sharpe. Na verdade, meu índice também é superior ao de Modigliani (Nobel de 1985), Sortino e todos os outros, mas no artigo ele só mencionou o índice de Sharpe por ser o mais utilizado no mundo, por ser mais tradicional e mais conhecido, e citou o meu por ser o mais eficiente. Em 2021 fui comparado a Feynman e novamente a Leonardo, numa situação interessante, em que a pessoa (Francisco) fez uma análise razoavelmente detalhada da comparação para justificar sua opinião. Em 2021, novamente fui citado como possivelmente a pessoa mais inteligente do brasil por Luca Fujii, um dos maiores talentos precoces da Matemática brasileira, mas como ele ainda é muito jovem, não chegou a manifestar todo o seu brilho intelectual e por isso ainda não é tão famoso, mas será em breve. O Luca é uma pessoa com muitas virtudes morais, além de intelectuais, assim como o João Antonio L.J., por isso me sinto realmente honrado que essas pessoas tenham opiniões elevadas a meu respeito, e também porque sei que não dizem isso só para me agradar, mas sim baseados em critérios profundos, critérios muito bem fundamentados e bem ponderados. O João leu mais de 1000 de meus artigos, o Luca leu meus dois livros e seguramente leu centenas de meus artigos. Portanto, além de serem excepcionalmente capacitados, também tinham conhecimento sobre o que estavam falando.
Enfim, acho que os problemas do mundo real que resolvi, as pessoas que tentaram resolver os mesmos problemas e os prêmios que essas pessoas já ganharam e outros problemas que elas já resolveram, as opiniões de alguns expoentes das sociedades de alto QI a meu respeito talvez respondam um pouco sobre meu QI, certamente mais e melhor do que um teste padronizado poderia dizer.
Jacobsen: Que filosofia ética faz algum sentido, mesmo o sentido mais viável para você?
Melão Jr.: Não conheço nenhum autor que represente minhas opiniões sobre qualquer assunto de forma suficientemente acurada e completa. Sempre há detalhes nos quais ocorrem divergências. Em meu livro sobre a existência de Deus, um dos capítulos trata de Ética, no qual exponho minhas opiniões sobre isso. Há alguns artigos nos quais discuto questões relacionadas à Ética, esse é um deles: https://www.saturnov.org/liberdadeedireitos
Jacobsen: Que filosofia política faz algum sentido, até mesmo o sentido mais viável para você?
Melão Jr.: há um provérbio polonês que diz “No capitalismo o homem trai o homem. No socialismo ocorre o contrário”. Em teoria, quase todos os sistemas políticos tentam ser razoavelmente bons, com diferentes prioridades, mas cada um visando, a seu próprio modo, objetivos nobres e elevados, embora utópicos e superficiais em pontos básicos, por isso ao serem instaurados na prática, fica claro que as vicissitudes humanas corrompem qualquer sistema, porque os sistemas teóricos não fazem previsões adequadas sobre como lidar com humanos reais. Creio que num futuro não muito distante, se não nos destruirmos por uma guerra, a liderança política do planeta estará “nas mãos” de máquinas inteligentes, e haverá um sistema muito mais lógico e justo do que qualquer sistema existente atualmente. Estará longe de ser um sistema perfeito, mas será muitíssimo superior a qualquer coisa que conhecemos, pois esses sistemas serão capazes de analisar interações muito mais complexas e profundas das relações humanas entre grandes grupos e como essas relações evoluem a longo prazo, aproximadamente do mesmo modo que os melhores programas de Xadrez superam por larga margem a qualidade de análise dos humanos, “enxergando” de forma muito mais correta e mais profunda e fazendo previsões mais acuradas do que qualquer humano. O problema é que existe um risco elevado de que sejamos escravizados pelas máquinas, ou algo assim, ou haja uma união simbiótica entre humanos máquinas, ou parasitária, é difícil prever, vai depender de algumas decisões que tomarmos nos próximos anos e décadas.
Jacobsen: Que metafísica faz algum sentido para você, mesmo o sentido mais viável para você?
Melão Jr.: a teoria do multiverso está no limiar entre a Física e a Metafísica. A palavra “multiverso” é uma construção inadequada, mas o significado é plausível e até mesmo provável.
Jacobsen: Que sistema filosófico abrangente de visão de mundo faz algum sentido, mesmo o sentido mais viável para você?
Melão Jr.: o que eu descrevo no livro que citei acima, no qual apresento argumentos que me parecem conclusivos sobre a existência de Deus, e abordo outros temas filosóficos e científicos.
Jacobsen: O que dá sentido à vida para você?
Melão Jr.: não acho que haja necessidade de haver algo que dê sentido à vida além dela mesma. A vida tem um sentido intrínseco. Mas posso afirmar que proteger minha mãe e proporcionar o melhor possível a ela era algo que me dava alegria. Ela faleceu em 2016. Fiquei sem me alimentar adequadamente e sem dormir adequadamente durante alguns meses. Eu já havia pesquisado sobre criogenia e sabia que essa tecnologia não oferece perspectivas realistas de trazer a pessoa de volta à vida, porque as membranas de trilhões de células são rompidas com o choque térmico, deixando o citoplasma vazar, um processo com baixa probabilidade de ser revertido. Comecei a pensar numa forma de ressuscitá-la, mas acho muito difícil que a pessoa ressuscitada pudesse ter restaurada exatamente a mesma personalidade e mesmas memórias, portanto não seria a mesma pessoa. Se as memórias e a personalidade dela tivessem sido armazenadas integralmente em um HDD ou SSD, ou algum dispositivo com propriedades similares, então talvez fosse possível restaurar a mesma pessoa, num genuíno processo de ressuscitação. A alegria de viver se foi com a morte dela. Em 2018, conheci minha namorada, Tamara, que está morando comigo desde então e posso dizer que ela tem sido minha alegria de viver, minha vida seria muito pequena e descolorida se não fosse por ela. É uma honra para a espécie humana que existam pessoas profundamente empenhadas em fazer o que é certo e justo, como ela, que elevam a dignidade humana a um patamar próximo da perfeição.
Jacobsen: O significado é derivado externamente, gerado internamente, ambos, ou algo mais?
Melão Jr.: em dedução o significado é atribuído, em última instância, arbitrariamente. A pessoa determina o que é um triângulo e aquilo será um triângulo. Em indução finita, o significado é inferido a partir da análise da amplitude de variação das propriedades observadas em entidades de mesma classe em comparação à dispersão das mesmas propriedades observadas em entidades de classes diferentes.
A evolução no conceito de “planeta”, por exemplo, ilustra bem como isso acontece. Os gregos classificavam a Lua, o Sol, Mercúrio, Vênus, Marte, Júpiter e Saturno como planetas. Nem todos os gregos, na verdade. Aristarco, Seleuco, Ecfanto (supondo que Ecfanto tenha de fato existido) e Filolau não adotavam o mesmo critério. Com Copérnico, o Sol deixava de ser considerado um planeta, enquanto a Terra passava a ser classificada como planeta, porque o critério dos gregos era que os planetas se moviam. Quando foi descoberto Urano, em 1781, também passou a ser classificado como planeta, porque suas propriedades gerais se ajustavam melhor a essa classe de objetos, e o mesmo aconteceu quando foi descoberto Ceres, em 1801. Porém, pouco depois, foram descobertos Palas, Vesta, Juno e outros objetos com órbitas muito semelhantes às de Ceres, todos muito menores que os demais planetas e compartilhando quase mesma órbita. Em poucos anos havia mais de 10 objetos com essas características, o que levou a reconsiderar se os critérios utilizados para classificar os planetas eram apropriados. Então surgiu o conceito de “planetoide” depois modificado para “asteroide” para incluir essa classe de objetos. Na época em que Plutão (1930) foi descoberto, como ele estava muito fora da zona de asteroides e seu tamanho foi originalmente estimado como sendo semelhante ao da Terra, foi classificado como planeta. Em poucos anos se verificou que ele era muito menor do que se pensava. As primeiras estimativas de 1931 atribuíam a Plutão 13.100 km de diâmetro, depois 6084,8 km, depois 5760 km, depois 3000 km, 2700 km, 2548 km, 2300 km, 2390 km e os dados mais recentes indicam cerca de 2376,6 km. Por isso, na época em que foi descoberto, era plausível que fosse classificado como “planeta”, mas ao constatar que era muito menor e menos massivo, a situação mudou. Essa questão é analisada com mais detalhes em meu livro sobre esse tema. Quando foram descobertos outros objetos transnetunianos, já se começou a considerar que talvez Plutão ficasse mais bem classificado como um daqueles objetos, em vez de ser considerado um planeta. Os planetas telúricos (Mercúrio, Vênus, Terra e Marte) tinham superfície rochosa, densidade média aproximadamente entre 4 e 5,5 vezes a da água, diâmetro aproximadamente entre 5.000 e 13.000 km, enquanto planetas jovianos (Júpiter, Saturno, Urano, Netuno) tinham “superfície” fluida, densidade média aproximadamente entre 0,7 e 1,7 vezes a da água, diâmetro aproximadamente entre 50.000 e 140.000 km. Mas Plutão ficava muito fora desses dois grupos, sua densidade 1,9 era semelhante à dos jovianos, mas seu tamanho era menor que o dos telúricos. Não se sabia se a superfície era rochosa, mas em princípio se acreditava que sim. Quando foi descoberto Éris – cuja massa é similar à de Plutão e talvez um pouco maior –, finalmente decidiram promover um debate sobre isso e reconsiderar os critérios para classificação de planetas. Em 2006, a UAI decidiu criar uma nova classe de objetos, os “planetas anões”, e Plutão entrou para essa categoria.
Eu pulei alguns eventos importantes, como a descoberta de Galileu e Simons dos 4 grandes satélites de Júpiter, que foram inicialmente considerados “planetas”, porque não existia o conceito de “satélite” até que Kepler sugeriu isso. Algumas vezes, Galileu se referia a esses objetos como “pequenas estrelas”, já que não se sabia muito bem o que eram as estrelas, embora Giordano Bruno já tivesse um palpite promissor.
O significado de “planeta” foi e continua sendo determinado pela comparação com outros objetos que apresentem diferentes níveis de similaridade. Em casos nos quais há grande números de objetos para comparar, como a taxonomia de animais, pode-se fazer as classificações em muitos níveis hierárquicos, com diferentes níveis de similaridade, e os significados são atribuídos de acordo com as propriedades comuns a todos os elementos da mesma classe, ao mesmo tempo em que se tenta selecionar critérios que permitam distinguir de elementos de outras classes. Nas classificações de cachorros e gatos, por exemplo, não é útil considerar o fato de terem 2 olhos, rabo e focinho, porque isso não ajuda a distinguir uma espécie da outra. Tamanho médio poderia ajudar, se a dispersão nos tamanhos fosse mais estreita, mas como as diferentes raças de cachorro variam numa amplitude muito grande, esse critério também não ajudaria muito. Nesses casos, critérios mais sutis e específicos, como morfologia do rosto, morfologia dos dentes e número de dentes acabam sendo mais úteis. O tamanho do focinho pode ajudar, mas o número de dentes tem significado semelhante, por estar relacionado ao tamanho do focinho, com a vantagem de ser mais objetivo e quantitativo.
Enfim, essas são as duas principais maneiras de determinar os significados. Uma é arbitrária, permite que se imponha quais características a entidade deve ter. A outra tenta descobrir quais característicos são comuns a todas as entidades de uma mesma classe e, ao mesmo tempo, são diferentes das características de entidades de classes semelhantes, de modo a possibilitar a distinção entre entidades de uma classe ou de outra. Esses significados são frequentemente incompletos, incertos e sujeitos a revisões, conforme se faz novas descobertas sobre outras entidades cujas características sejam limítrofes em determinada classe, levando a ampliar, estreitar ou reconfigurar os critérios de modo a incluir ou excluir a nova entidade em uma das classes conhecidas, ou, mais raramente, criar uma nova classe inaugurada por essa entidade.
Jacobsen: Você acredita em vida após a morte? Se sim, por que e de que forma? Se não, por que não?
Melão Jr.: o conceito de “morte” é um desligamento, que por enquanto não sabemos como religar, mas brevemente será possível de diferentes maneiras. Esse é um dos tópicos analisados mais detalhadamente em meu livro. O conceito de “alma” também precisa ser examinado com detalhes, para responder a isso, e o tamanho da resposta seria imensa.
Jacobsen: O que você acha do mistério e da transitoriedade da vida?
Melão Jr.: não acho que seja transitória. Por enquanto tem sido, mas isso deve mudar em breve.
Jacobsen: O que é amor para você?
Melão Jr.: é uma tentativa desesperada de inventar uma palavra para representar um sentimento indescritível.
Apêndice:
Sistema Educacional no Brasil e estudo de Richard Lynn sobre QIs em diferentes países.
O sistema educacional costuma ser ruim no mundo inteiro, mas no Brasil é muito pior do que a média de países com PIB similar ao nosso. Estimo que a educação brasileira seja uma das piores do mundo. O Professor Emérito da Universidade de Ulster Richard Lynn oferece uma explicação simplista para isso em seu artigo “QI e riqueza das nações”. Ele não trata da Educação. Trata da Economia, mas o argumento que ele utiliza para justificar as diferenças de renda seria igualmente (e melhor) aplicado à Educação, desde que o argumento fosse válido. Mas o argumento parte de uma premissa falsa. Há muitos erros no trabalho de Lynn. A ideia central que ele defende está certa, mas quantitativamente ele força resultados exagerados. A tese que ele defende – de que existem diferenças étnicas e regionais – está certa, mas as diferenças não são tão grandes quanto ele quer fazer parecer. De acordo com Lynn, o QI médio em Guiné Equatorial é 56. Se isso estivesse certo, seria esperado que o país fosse uma grande tribo de nômades, eles não teriam dominado a técnica de produzir fogo, não teriam construído arados, lanças etc. Mas existe uma civilização urbana lá. Além disso, pessoas com QI abaixo de 60 têm muita dificuldade para aprender a ler e escrever, mesmo vivendo em países com ampla infraestrutura e incentivo à alfabetização. Se mais de 91% da população de Guiné Equatorial sabe ler (supondo que essa informação não seja maquiada), mesmo num ambiente com menor incentivo ao aprendizado, seria muito difícil explicar como essa população com QI médio 56 é predominantemente alfabetizada. Lynn tenta disseminar as crenças neonazistas dele e usa essas pesquisas científicas para tentar ganhar credibilidade para suas opiniões. O QI médio dos judeus Ashkenazi é cerca de 114, a média mais alta do mundo, mas Lynn conseguiu manipular os dados de sua meta-análise para que o QI médio do estado de Israel ficasse em 94.
No caso do Brasil, os resultados de Lynn indicavam QI médio 87 e em revisão mais recente indicam 83,38. Se isso estivesse certo, seria uma boa explicação para baixa qualidade da produção científica brasileira e a péssima qualidade de ensino. Mas os problemas reais que predominam no Brasil são uma combinação de preguiça dos alunos, preguiça dos professores, nivelamento por baixo nas aulas e péssimo metodologia “pedagógica”.
Uma análise mais séria da situação mostra que o QI real médio do brasileiro não é tão baixo quanto os estudos de Lynn sugerem. Muitas pessoas entregam os questionários dos testes de QI sem responder, ou “chutam” todas as alternativas, ou respondem algumas e “chutam” as demais.
Em uma postagem minha no perfil de nosso amigo Iakovos Koukas, fiz um comentário razoavelmente detalhado sobre isso, o qual também reproduzi no grupo IQ Olympiad e reproduzo novamente a aqui:

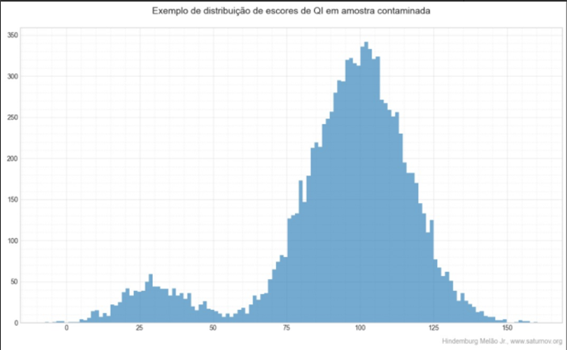
Realmente existem diferenças cognitivas em função da etnia, assim como existem em relação à altura média, tamanho médio do pênis, concentração média de melanina sob a pele etc., mas as diferenças cognitivas são muito menores do que ele tenta “vender”.
De um lado, existe o problema do igualismo ingênuo, defendido por alguns grupos pseudoideológicos, e isso não encontra nenhum respaldo nos fatos. No extremo oposto, existem os grupos de pessoas como Richard Lynn, Tatu Vanhanen e Charles Murray que tentam exacerbar as diferenças raciais e usá-las para justificar a situação de miséria de alguns povos. Tanto o grupo dos eugenistas radicais quanto o dos igualistaristas radicais estão errados, mas entre um extremo e outro existem algumas verdades.
Assim como há diferenças cognitivas marcantes entre espécies, há diferenças entre etnias, porém menos marcantes porque a amplitude de variação genética dentro de uma mesma espécie é menor. Fingir que essas diferenças não existem é um erro, porque o conhecimento correto sobre as particularidades de cada etnia ajuda a fazer diagnósticos mais acurados de diversas doenças cujos sintomas não são os mesmos em todos grupos étnicos, o tempo adequado de exposição ao Sol para a síntese de vitamina D não é o mesmo, e muitas características que seriam interpretadas como “saudáveis” em algumas etnias não são em outras, por isso o uso correto dessas informações ajuda a interpretar com mais eficácia os resultados de hemogramas, analisar anomalias ósseas, dermatológicas e musculares. Conhecer as diferenças fisiológicas, cognitivas e comportamentais de cada etnia é importante; o problema está em usar essas diferenças com o propósito de tiranizar, oprimir ou diminuir os méritos de um povo, isso é antiético e anticientífico, e Lynn tenta fazer isso de forma ostensiva.
No caso do Brasil, parece haver uma distorção perto de 10 a 15 pontos nos números apresentados por Lynn, então o QI médio correto do brasileiro deve ser cerca de 95, um pouco abaixo da média, mas não tanto a ponto de justificar os péssimos resultados do Brasil em Ciência. Os problemas reais parecem ser a preguiça e outros itens que mencionei acima. Há estudos recentes que questionam se o comportamento aparentemente preguiçoso deveria ser classificado exatamente como “preguiça” ou não, mas não vou entrar também nessa discussão para não tornar esse texto ainda mais longo.
Nos anos 1950 e 1960, Richard Feynman esteve algumas vezes no Brasil e fez críticas severas ao sistema educacional brasileiro, ele fez alguns experimentos sociais de improviso e mostrou que estudantes de doutorado brasileiros muitas vezes não compreendiam o básico sobre o que estavam fazendo, agiam mecanicamente, sem a menor noção sobre os fundamentos. Os brasileiros escreveram algumas palavras bonitas em relação às críticas de Feynman, dizendo que pretendiam melhorar alguma coisa, mas a situação atual é talvez até pior do que era na época em que Feynman esteve em nosso país. Além da situação vergonhosa da educação no Brasil, há ainda outros problemas nesse episódio, porque os “educadores” brasileiros demonstraram surpresa e perplexidade com os problemas apontados por Feynman, como se estivessem numa casa pegando fogo, mas não estivessem enxergando que o fogo estava devorando tudo, até que um vizinho entra e mostra o fogo a eles. Então eles agradecem, mostram-se chocados, fazem um discurso de mea-culpa, mas não fazem nada concreto em relação ao incêndio, que continua devastador… É inacreditável que não estivessem enxergando o fogo antes de o vizinho indicar a eles e é inacreditável que continuem sem tomar qualquer providência depois que o problema foi apontado.
Embora os cientistas e educadores não tenham se mobilizado para tentar resolver o problema, alguns expoentes brasileiros da Matemática, que tinham algumas experiências na Europa e nos Estados Unidos, decidiram tentar reproduzir um pequeno oásis, trazendo para o Brasil um pouco do que haviam experimentado em países desenvolvidos. Em 1952, foi fundado o IMPA (Instituto de Matemática Pura e Aplicada). Naquela época, o Brasil estava no Grupo I da IMU (International Mathematical Union), o nível mais baixo. Ao longo de 70 anos, o IMPA tem sido o único lugar no Brasil onde houve uma tentativa sincera de identificar e apoiar alguns talentos notáveis, tentando escapar da burocracia e da ineficiência do Sistema Educacional. Mas o IMPA é apenas 1 instituição situada no Rio de Janeiro. O Brasil é um país grande, com 8.500.000 km^2, de modo que as pessoas que moram longe do RJ muitas vezes não conseguem desfrutar o que o IMPA oferece. Por isso o alcance do IMPA ainda é pequeno. Com a popularização da Internet isso tem melhorado, mas o número de beneficiados ainda é muito limitado, inclusive porque há relativamente pouca divulgação dos eventos do IMPA, a maioria das escolas não inscreve seus alunos em OBM (Olimpíada Brasileira da Matemática), a maioria dos alunos nem sequer sabe que existe OBM. Há alguns professores espalhados pelo Brasil ligados ao IMPA, que tentam contribuir para a identificação de talentos, mas é um processo difícil, eles não recebem incentivo do governo, nem de empresas. Mesmo com esses obstáculos, entre 1952 e 2015 o IMPA elevou o Brasil do Grupo 1 para o Grupo 5 (o mais alto), do qual fazem parte apenas 11 países: Alemanha, Brasil, Canadá, China, EUA, França, Israel, Itália, Japão, Reino Unido e Rússia.
Não sei quais os critérios para ser incluído no Grupo 5 da IMU, mas suponho que seja uma combinação de mérito e política, talvez mais mérito do que política. Digo que há um pouco de política porque há países com duas medalhas Fields ou dois prêmios Abel, mas não fazem parte desse grupo, como Austrália, Bélgica, Irã e Suécia, enquanto o Brasil tem apenas 1 medalha Fields. Claro que esses prêmios não devem ser o único critério, mas são indicativos bastante razoáveis sobre a nata da matemática que se produz em cada país. Também há vários países com 1 medalha Fields e uma tradição matemática mais longa, que também não estão no Grupo 5. Talvez o critério leve em consideração o ritmo de crescimento, e nesse quesito o Brasil talvez seja, ao lado da China e da Índia, um dos que mais tem crescido na produção de Matemática de alto nível.
O fato é que se QI médio do brasileiro fosse realmente tão baixo quanto alega Richard Lynn, e o problema principal no Brasil fosse realmente o baixo QI médio da população, então as ações do IMPA não teriam sido capazes de modificar substancialmente a qualidade e a quantidade da produção matemática de alto nível. Se o problema fosse baixo QI, a solução viria de outras ações, como melhoras nutricionais, por exemplo. As ações do IMPA não alteraram o QI médio da população; apenas alteraram a eficiência na identificação de talentos que já existiam no país, e após a identificação passou a existir oferta de oportunidade e incentivo a esses talentos.
Os números apontados por Lynn, de que o QI médio do brasileiro seria 87, mostram-se inconsistentes com os resultados alcançados pelo IMPA. Mesmo com uma população de 213 milhões, seria difícil que algumas dessas pessoas chegassem ao topo mundial com raridade perto de 1 em 300 milhões se o Brasil estivesse 1 desvio padrão abaixo da média, mesmo porque o IMPA não consegue estender seus benefícios a mais do que 1% a 5% da população mais talentosa. Claro que outras hipóteses seriam aplicáveis, como um desvio padrão maior na distribuição de QI entre a população brasileira ou uma distribuição mais platicúrtica. Mas geralmente o que se observa em grupos com altura média menor é um desvio padrão mais estreito, em vez de mais largo. Isso acontece com praticamente todas as variáveis. O desvio padrão no diâmetro de parafusos maiores é mais largo do que em parafusos menores. Em outras palavras, o desvio padrão percentual geralmente é mantido, então seria estranho uma população com QI mais baixo ter desvio padrão maior. Além disso, seria um ajuste ad hoc para tentar salvar uma teoria que apresenta outros problemas, sendo mais plausível passar a navalha de Occam e aceitar que Lynn está equivocado sobre isso. O QI médio correto do brasileiro é substancialmente maior do que ele diz, assim como os QIs da maioria dos outros povos não-arianos, que ele tenta empurrar para baixo, também são maiores do que os números que ele apresenta.
Examinando objetivamente os fatos, o que os dados sugerem é que o QI médio do brasileiro provavelmente está bem mais perto de 95 do que de 87. Um pouco abaixo da média, mas não tão abaixo quanto Lynn sugere.
Os resultados do IMPA mostram também que talvez a preguiça seja um reflexo do péssimo sistema educacional. Se a preguiça fosse um problema generalizado no país, as soluções implementadas pelo IMPA também não teriam sido suficientes para resolver isso; seriam necessárias outras medidas complementares. Talvez a preguiça seja um problema marcante que atinge mais de 99% da população, mas cerca de 1% não poderia ser rotulada como “preguiçosa”, mas sim como vítima de um sistema educacional muito ruim. Como mais de 99% da produção intelectual vem desse 1%, temos aí um gigantesco problema, e uma completa falta de atenção sobre esse problema, porque os políticos não estão muito preocupados em empreender grandes esforços para conquistar 1% de votos, já que com menos esforço eles podem conseguir mais votos fingindo agradar a um público menos exigente, mais fácil de ludibriar e muito mais numeroso.
Um dos grandes problemas é que os 99% da população também são prejudicados, mas eles próprios não enxergam isso e não cobram do governo medidas que possam contribuir para melhorias a longo prazo, medidas que sejam boas e justas para todos. Cada um quer apenas que o governo adote medidas com resultados imediatos que beneficiem seus próprios umbigos. Desse modo, o problema tende a se perpetuar, como tem acontecido há décadas.
Muitos acadêmicos brasileiros costumam reclamar de falta de verbas e atribuir a baixa produção científica a isso. Outros fazem pior, fingem que há produção científica de boa qualidade no Brasil, apesar da falta de verba. Mas o que os fatos concretos mostram é que países realmente muito pobres, nos quais a maior parte da população vive na miséria, como Etiópia, Nigéria, Congo, Quênia, Gana etc. tiveram cidadãos laureados com o Nobel, enquanto no Brasil nunca houve um ganhador do Nobel. Além disso, quando Einstein desenvolveu seus principais trabalhos, pelos quais ele merecia 3 prêmios Nobel (e mais 2 por trabalhos posteriores), ele não estava recebendo nenhuma verba para suas pesquisas, nem nos anos anteriores. Portanto, embora a falta de recursos imponha limitações severas, não pode ser considerada um impedimento absoluto e muito menos ser usada como pretexto numa situação como essa. Grandes trabalhos foram realizados praticamente sem verba, como boa parte da obra de Newton, durante em 1665.
[Aqui talvez caiba uma pequena ressalva, porque conforme comentei na parte sobre prêmios e méritos, é possível que alguns brasileiros tenham realizado trabalhos com méritos para receber um Nobel, mas não foram laureados por questões políticas, burocráticas etc. Meus trabalhos sobre Econometria e Gerenciamento de Risco, por exemplo, são mais expressivos do que a maioria dos trabalhos dos laureados com o Nobel de Economia nas últimas décadas. A descoberta do méson π, embora tenha sido predominantemente um trabalho operacional, teve um brasileiro como protagonista (César Lattes), mas como o chefe da equipe era Celil Powell, Lattes tinha apenas um B.Sc. e na época (1950) o prêmio só era concedido ao chefe da equipe, Lattes acabou não recebendo o prêmio, embora tenha sido talvez o principal responsável por esse trabalho e foi o autor principal do artigo. Depois da detecção dos mésons π nos raios cósmicos (1947), Lattes era um dos poucos no mundo com o conhecimento necessário para identificar assinaturas deixadas por essas partículas nas placas de emulsão, por isso ele foi convidado a colaborar no CERN (1948) e verificar se eles também estavam conseguindo produzir mésons π, pois a energia necessária para isso era ultrapassada com folga pelo acelerador de partículas utilizado, portanto eles provavelmente já estavam produzindo pions há muito tempo (desde 1946), mas não sabiam exatamente o que deveriam procurar nas câmaras de bolha como sendo assinaturas dos mésons π. Lattes foi ao CERN e fez as identificações. Novamente o trabalho foi distinguido com o Nobel e novamente Lattes ficou fora da premiação. Ao todo, Lattes foi indicado 7 vezes para o Nobel, mas nunca chegou a ser premiado. Oswaldo Cruz também recebeu indicação ao Nobel de Medicina, mas não foi premiado. Talvez Machado de Assis também tivesse mérito para um Nobel de Literatura. Então, embora haja 0 brasileiros laureados com Nobel, talvez alguns tenham méritos para isso. Há um texto detalhado no qual analiso o caso de Lattes, sem os habituais exageros e distorções nacionalistas da maioria dos artigos sobre ele, mas ao mesmo tempo reconhecimento os méritos que ele teve e que não foram devidamente reconhecidos.]
Por um lado, a baixa produção científica reflete a falta de verba, por outro lado a falta de verba reflete a baixa produção científica, porque se houvesse realmente produção científica e tecnológica de boa qualidade, grandes empresas nacionais e internacionais teriam interesse em financiar essas pesquisas, pois teriam lucro com isso. Se empresas privadas não investem na ciência brasileira é porque tal “investimento” não gera expectativa de lucro, porque o nível de produção fica abaixo do que poderia justificar algum interesse sério dos empresários. Eu costumo usar o termo “doação” para a ciência brasileira em vez de “Investimento”, porque o significado de “investimento” é outro. O que os pesquisadores brasileiros reivindicam é basicamente isso: doação.
É importante deixar claro que não sou contra o financiamento da ciência brasileira, seja na forma de investimento, seja na forma de doação. Se eu fosse contra isso, seria uma estupidez. Eu sou contra a péssima gestão da verba destinada à Ciência, aliada ao péssimo sistema educacional e a completa falta de incentivo à produção intelectual. Produção intelectual não é escrever 50.000 papers inúteis para fingir que se está produzindo e continuar “mamando” nas bolsas das agências fomentadoras de “pesquisa”. Produção intelectual de verdade é se empenhar seriamente para resolver problemas reais e importantes. Por isso, em vez de ficar choramingando por falta de verba, o procedimento correto seria uma reformulação completa na palhaçada que acontece na Educação brasileira e na pesquisa “científica” brasileira, precisariam começar a produzir de verdade, com alta qualidade, como acontece no IMPA, e então apresentar fatos substanciais e argumentos consistentes para reivindicar investimentos. Sem isso, o discurso choroso para pedir doação é frágil. Certamente uma multidão de pesquisadores improdutivos me apedrejará por esse comentário, mas os poucos pesquisadores sérios concordarão comigo, embora talvez eles não tenham coragem de reconhecer publicamente a posição que defendem, para não serem linchados pelos colegas.
Talvez haja menos de 1% de pesquisadores sérios no Brasil, entre os quais tive a oportunidade de conhecer alguns, como Renato P. dos Santos, Roberto Venegeroles, André Gambaro, José Paulo Dieguez, Luis Anunciação, Antonio Piza, André Asevedo Nepomuceno, Herbert Kimura, Cristóvão Jaques, George Matsas, Doris Fontes entre outros. Mas infelizmente representam uma pequena fração, e nem sempre eles admitem abertamente a situação desastrosa em que se encontra a ciência brasileira, pois a pressão é grande para que finjam acreditar na encenação da qual a maioria dos outros faz parte. Quando a pessoa assume uma posição justa em relação a isso e diz verdades proibidas, ela começa a ser covardemente boicotadas por todos os lados, por isso é compreensível que muitos prefiram permanecer em silencia, evitando se manifestar, ou simplesmente fingir que concordam com a fantasia que tentam propagar a situação da Ciência e da Educação no Brasil. Muitos criticaram Copérnico devido ao prefácio de seu livro Revolutionibus, por ele não ter enfrentado de peito aberto as crenças dominantes, mas quando se analisa os problemas enfrentados por Galileu, fica claro que a defesa da verdade que contraria os interesses de determinados grupos pode ser muito oneroso. E seria ingênuo acreditar que as entidades que dominam o mundo atualmente (mídias, empresas, universidades, políticos etc.) sejam mais escrupulosos do que eram os eclesiásticos medievais. Certamente há algumas entidades mais idôneas e mais sinceramente empenhadas na defesa do que é certo e justo, mas são exceções, infelizmente. “Ironicamente” as mesmas pessoas que se mostram indignadas com a perseguição a Galileu são as pessoas que hoje praticam o mesmo tipo de abusos, injustiças e perseguições.
Essa é uma situação delicada, porque se a imensa maioria constrói uma farsa e finge que ela é real, torna-se difícil para que uma pequena minoria restabeleça a verdade. Por exemplo: Roberto de Andrade Martins é um pesquisador sério, com pós-doutorados em Cambridge e Oxford, com bons conhecimentos e boa compreensão de Física, Lógica e Epistemologia. Ele é completamente rechaçado pelos colegas e pelos que se dizem divulgadores “científicos”, porque Roberto diz verdades indesejáveis. Roberto nunca foi convidado para os grandes canais de divulgação científica do Brasil, embora ele seja de longe mais qualificado que a esmagadora maioria dos convidados para esses canais. Isso acontece porque nesses canais prefere-se as figuras mais “comerciais”, mais “carismáticas” aos olhos de quem finge se interessar por Ciência, em vez de cientistas sérios que digam verdades proibidas sobre a realidade trágica da ciência no país e da educação no país. Os youtubers que se dizem “divulgadores científicos” no brasil precisam escolher entre a verdade e a popularidade, e quase sempre preferem a segunda opção. Desse modo, vão arrastando uma farsa que em algum momento provocará o colapso do país, assim como aconteceu com a ex-URSS em 1991, ou com o banco Lehman Brothers em 2008. Foram varrendo a sujeira para baixo do tapete, até que chegou a um ponto em que a situação se torneou insustentável e o barraco caiu. Existem alguns poucos divulgadores científicos sérios no brasil, mas estes geralmente atingem um público muito menor, mais esclarecido e que já enxergam o problema sem que seja necessário que alguém mostre a eles. O público que realmente precisaria ser informado permanece “blindado”, para atender aos interesses de ninguém, já que ninguém lucrará com o naufrágio da nação. Certa vez Chomsky declarou que “o propósito da mídia não é o de informar o que acontece, mas sim moldar a opinião pública de acordo com a vontade do poder corporativo dominante”. Nesse caso é pior, porque não estão moldando a opinião pública de acordo com a vontade de ninguém. Estão apenas agindo estupidamente para o malefício de todos.
A hipocrisia é outro problema terrível que atinge grande número de acadêmicos brasileiros e de pseudo divulgadores da Ciência. Quando um estrangeiro vem ao brasil e diz que a ciência brasileira é uma piada, como fez Feynman, pisa e cospe na ciência brasileira, os acadêmicos brasileiros certamente não gostam, ficam envergonhados, mas mesmo assim eles aplaudem o macho alfa, como primatas bajuladores. Porém quando outro brasileiro aponta o mesmo problema, eles rosnam e vociferam contra o herege e tentam evitar que ele fale sobre isso.
Há mais algumas complicações que não podem ser negligenciadas: a maior parte da Ciência de ponta não tem aplicação imediata e pode levar décadas ou séculos até produzir algum retorno para o investidor. O diretor do departamento de Física Matemática da USP, Ph.D. pelo MIT e Post Doctoral pelo MIT, Antonio Fernando Ribeiro de Toledo Piza, que em 1994 quis me conhecer para conversar comigo sobre um trabalho que desenvolvi aos 19 anos, sobre um método para calcular fatoriais fracionários, no meio da conversa ele citou uma ocasião na qual perguntaram a Faraday para que serviam as descobertas que ele havia feito sobre a eletricidade e o magnetismo. Faraday respondeu com outra pergunta: “para que serve uma criança que acaba de nascer?” Essa frase exprime um problema complexo no tratamento da Ciência como “investimento”, porque a expectativa de vida humana atual é curta demais para que alguns investimentos em Ciência sejam enxergados como atraentes aos investidores particulares. São investimentos que só trarão retorno daqui a 50 anos, 100 anos ou mais, para as gerações seguintes, para nossos filhos, netos, bisnetos, é uma árvore que teremos o custo e o trabalho de plantar, adubar, cultivar, proteger, mas são nossos netos que colherão os frutos. Por esse motivo, mesmo em países nos quais a ciência se mostra prolífica, pode não ser atraente aos olhos dos investidores particulares, cujo horizonte de tempo que estão dispostos a aguardar por resultados costuma ser mais curto.
Feita essa ressalva importante, é necessário enfatizar que esse discurso seria falacioso se utilizado para tentar salvar a péssima reputação da ciência brasileira. O que se produz no brasil raramente pode sequer ser chamado “Ciência”. Faz-se tabulação de dados e relatórios descritivos sobre a tarefa. Para usar o argumento de Faraday a citei acima, em defesa do investimento na Ciência, antes seria necessário que o Brasil começasse a produzir Ciência de verdade.
Ciência de verdade envolve inovação, quebra de paradigma, aprimoramento real, análise crítica, profunda, que ultrapassa o óbvio e agrega algum conhecimento novo e útil ao legado da humanidade. No Brasil raramente se faz isso. Na verdade, no mundo raramente se faz isso, mas o nível de escassez de inovações é pior no Brasil do que em outros países com situação econômica similar ou com IDH similar.
Quando digo “quebra de paradigma” não precisa ser algo tão grandioso quanto um novo sistema cosmológico ou a uma teoria de unificação. Pode ser algo básico, como adicionar um pouco de boro às placas de emulsão fotográfica para preservar os registros dos mésons π até descer das montanhas, como fez César Lattes, ou resolver um problema de criptografia homomórfica que estava em aberto há 15 anos, como fez João Antonio L. J., ou desenvolver um novo sistema educacional que permite ensinar em 40 dias o conteúdo de 1 ano a uma criança que tinha notas abaixo da média e depois desses 40 dias a criança passa a ter as melhores notas da escola, como fez Tamara P. C. Rodrigues, ou revisar a fórmula de IMC, como eu fiz. São contribuições pequenas, mas que revelam fatos científicos ainda desconhecidos, ou corrigem conhecimentos que vinham sendo repetidos incorretamente há muito tempo, ou de algum modo contribuem para ampliar os horizontes do conhecimento ou para redirecionar o conhecimento para um caminho mais próximo da verdade. Não é uma completa desconstrução e reconstrução do conhecimento, como fez Newton, mas é um tijolo adicionado ao lugar certo, ou removido do lugar errado e reposicionado no lugar certo. Isso é o mínimo que seria esperado de um cientista, mas na grande maioria das vezes esse mínimo não é atendido, e os títulos de Ph.D. são distribuídos quase como um ritual, em que basta o candidato mostrar que sabe escrever e sabe interpretar um pouco do que esteja em alguns gráficos – com várias interpretações erradas, diga-se de passagem. Dependendo da disciplina, basta mostrar que sabe escrever, nem precisa saber ler um gráfico. Depois de cumprir o ritual, a pessoa recebe o rótulo de Ph.D. e começa a receber verba para prosseguir com essa palhaçada, fingindo que está produzindo Ciência.
A franca maioria das teses de doutorado e dos artigos científicos não apresenta nada de inovador. São títulos conferidos para inflar os egos e atender à vaidade das pessoas, mas não estão associados a nenhum mérito intelectual nem à produção científica original. A pessoa faz uma pesquisa elementar, puramente mecânica, para corroborar alguns resultados sobre os quais já existem centenas de outros estudos similares, e recebe um Ph.D. por isso, e o Estado paga a essas pessoas para fingir que estão produzindo algo relevante e chamam a isso “ciência brasileira”, mas o nome correto, na melhor das hipóteses, seria “tabulação de dados” e “relatórios descritivos”. Digo “na melhor das hipóteses” porque geralmente há vários erros crassos nesses procedimentos, o que torna a situação ainda mais vexatória.
O problema central é que não existe uma cultura de produzir inovações. Apenas repete-se interminavelmente. Não há incentivo à inovação, não há cobrança de inovações, não à recompensa para inovações e, o pior, há inclusive penalidades para inovações. Em 1998, uma amiga (Patrícia E. C.), que estava concluindo seu doutorado na USP, verificou que alguns dados experimentais sobre a morfologia de galáxia anãs era inconsistente com as expectativas. Em vez de seu orientador ajudá-la a tentar compreender o que poderia estar causando aquilo, ele disse a ela para refazer as medições, porque ela deveria ter errado nas medidas ou nos cálculos. Até esse ponto, concordo com ele, porque esses erros costumam ser os mais comuns. Ela refez e obteve resultados estatisticamente equivalentes aos das primeiras medições. Nesse ponto o alerta amarelo se torna vermelho e o orientador dela deveria ter dado mais atenção ao caso. Entretanto, ele disse para ela refazer outra vez! Isso é um completo absurdo. É anticientífico. É destruir “provas” que poderiam contribuir para ampliar, revisar, aprimorar o que se conhecia até então. Esse é o nível a que se encontra a seita chamada de “ciência brasileira”. Se alguma descoberta se opõe aos dogmas estabelecidos, precisa ser ajustada de alguma maneira até que fique em conformidade com os dogmas. Além de não haver incentivos às descobertas, quando há algum indício de que se pode estar diante a algo novo, tenta-se apagar os vestígios da possível descoberta! As pessoas são adestradas para não produzir, não inovar, não descobrir!
Parte do problema da Educação no país não é culpa dos professores, alunos e pesquisadores. Eles apenas dançam conforme a música. Mas uma grande parte do problema é culpa deles, porque eles determinam a música que deve tocar. Além disso, eles podem se recusar a dançar conforme a música, podem colocar fones de ouvido com músicas melhores e podem criar seu próprio centro de excelência, como no caso do IMPA.
A resistência da comunidade acadêmica em admitir esses fatos agrava a situação, porque em vez de tentar consertar os problemas, fingem que os problemas não existem, varrem a sujeira para baixo do tapete e seguem em frente, como se estivesse tudo bem. Recentemente o presidente do Brasil fez um corte brutal nas verbas destinadas à “ciência”. É uma situação delicada, porque o problema da improdutividade científica não se resolve assim. O corte de verba apenas agrava a situação. É ruim destinar verba a um setor que não gera resultados satisfatórios, mas sendo um setor fundamental, o procedimento correto é restaurar esse setor e assegurar que ele funcione como deveria, em vez de matá-lo, tirando-lhe o pão e a água. Precisaria trocar pão e água por uma dieta mais rica, aumentar o investimento em Ciência e simultaneamente reformular os critérios de concessão de bolsas, concessão de verbas, desburocratizar a importação de livros e de produtos científicos e tecnológicos, promover intercâmbios com pesquisadores capacitados, criar prêmios por mérito real relacionado à excelência na produção original de trabalhos relevantes, em vez dos prêmios políticos de fachada, entre muitas outras mudanças desde a educação de base até os títulos de professores eméritos.
Nos anos 1970, a China, a Índia e a Tailândia eram países muito mais pobres e menos desenvolvidos que o Brasil, mas fizeram investimentos massivos na identificação de crianças talentosas e ofereceram condições diferenciadas de incentivo a essas crianças. A Tailândia interrompeu o projeto. China e Índia mantiveram. Em menos de duas décadas, começaram a colher os frutos disso, depois de uma geração, essas crianças se tornaram professores altamente capacitados, que proporcionaram à geração seguinte uma educação ainda mais primorosa, e hoje a China caminha para se tornar a maior potência econômica, cultural, científica e tecnológica do mundo, e a Índia segue de perto. Houve uma reformulação séria e profunda no sistema de ensino para que pudessem chegar onde estão agora. Em vez de fingir que estavam fazendo Ciência, admitiram a improdutividade e a baixa qualidade do que produziam, e começaram a consertar o que estava errado. Um dos grandes problemas no Brasil é exatamente essa incapacidade de admitir os erros.
Footnotes
[1] Founder, Sigma Society; Creator, Sigma Test Extended.
[2] Individual Publication Date: June 8, 2022: https://in-sightjournal.com/melao-1; Full Issue Publication Date: September 1, 2022: https://in-sightjournal.com/insight-issues/.
*High range testing (HRT) should be taken with honest skepticism grounded in the limited empirical development of the field at present, even in spite of honest and sincere efforts. If a higher general intelligence score, then the greater the variability in, and margin of error in, the general intelligence scores because of the greater rarity in the population.
License
In-Sight Publishing by Scott Douglas Jacobsen is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License. Based on a work at www.in-sightpublishing.com.
Copyright
© Scott Douglas Jacobsen and In-Sight Publishing 2012-Present. Unauthorized use and/or duplication of this material without express and written permission from this site’s author and/or owner is strictly prohibited. Excerpts and links may be used, provided that full and clear credit is given to Scott Douglas Jacobsen and In-Sight Publishing with appropriate and specific direction to the original content. All interviewees and authors co-copyright their material and may disseminate for their independent purposes.


I found this interview most interesting and Hindemburg Melão Jr’s ideas about life intelligence science and art etc. to be fascinating and educational. However the length of time he spends answering questions that he wasn’t asked and preparing the reader for an answer to the question is beyond ridiculous. In the real world we must be able to condense summarize and get to the point.
It is understandable that each question requires context first but…
The other criticism I have is that it is unbelievable to me that Malao cannot understand the relevance of the “error“ that he points out in Cooijman’s test (specifically problem 10 where the analogy relates from 1 to 3 and 2 to 4 instead of 1 to 2 and 3 to 4).
This represents a staggering lack of mental flexibility that is actually required in order to exhibit a medium to high intelligence!! There are so many instances in the world where solving problems requires thinking “outside the box”, challenging the authority and seeing the pattern among chaos despite being told that one should not look for a pattern.
To me this is so central in determining intelligence. In fact if he goes back to take Other Cooijmans tests he will find that using this strategy will allow him to solve many more problems. Solving real problems does not always lay within a fixed context; in fact this almost never happens.
So I gently prod Melao to change his stance on this. The fact that Cooijmans includes and requires this kind of flexibility in most of his tests is a testament to their superiority relative to others who do not.
Respectfully
Scott Durgin
LikeLike