Sigma Test Extended
Author: Hindemburg Melão Jr.
Translator (Portuguese to English): Eisque Nezuka
Editor and Reviewer: Scott Douglas Jacobsen
Numbering: Issue 30.B, Idea: Outliers & Outsiders (25)
Place of Publication: Langley, British Columbia, Canada
Title: In-Sight: Independent Interview-Based Journal
Web Domain: http://www.in-sightjournal.com
Individual Publication Date: July 22, 2022
Issue Publication Date: September 1, 2022
Name of Publisher: In-Sight Publishing
Frequency: Three Times Per Year
Words: 13,795
ISSN 2369-6885
Abstract
This article presents the Sigma Test Extended of Hindemburg Melão Jr. as the most difficult and reliable cognitive test for the measurement of the psychological construct of intelligence. With a preamble on intelligence tests and case studies of known high scorers on alternative tests and mainstream intelligence tests, concluded by analysis of distributions and norms, and endorsements, the formal Sigma Test Extended is presented in the paper in full.
Keywords: Alfred Binet, Anderson-Darling, Bruce Whiting, Cattell Culture Fair, chi-square comparison, Christopher Philip Harding, Cronbach’s α, David Letterman, Ferris Eugene Alger, FIDE ratings, Francis Galton, g factor, Gaussian distribution, intelligence, IQ, James Cattell, Johannes Douglas Veldhuis, Keith Raniere, Kevin Langdon, Kim Ung-yong, Kolmogorov-Smirnov, Leta Speyer, Lewis Terman, Marilyn vos Savant, Mega Test, Nobel Prize, Rick Rosner, Robert Bryzman, Sigma Society, Sigma Test Extended, USCF ratings, Wechsler.
Sigma Test Extended
*Please see the footnotes and citation style listing after the article.*[1],[2]
*Original publication here (in Portuguese): https://www.sigmasociety.net/sigmatest-extended, exception non-original submission permitted.*
Sigma Test Extended aims to be the most difficult and reliable cognitive test for measuring the “intelligence” construct, especially for people with an IQ above 160 (σ=16), requiring a wide range of cognitive skills at different levels of depth and complexity.
At the same time, it is a test that does not require specialized knowledge. Only general knowledge of elementary school, middle school, and high school. In some specific cases, it may be necessary to make small queries about the meaning of some words, but there is no need for specialized training in any specific area.
The ultimate goal of an accurate intelligence test is not to measure your ability to solve the questions on the test itself. The aim is to use these questions as an indirect means of discovering other, more important competencies. Therefore, one cannot lose sight of the primary objective to be achieved, otherwise one runs the risk of creating addicts to IQ tests, instead of discovering talents for Science, Mathematics, and other important fields of knowledge.
This is the purpose of STE, measuring the ability to solve diverse real-world problems, problems ranging from everyday issues to problems with an Olympic level of difficulty, requiring a combination of divergent and convergent thinking at different levels of sophistication, whose issues are compatible with the skill levels you want to measure. This is an important differentiator, because IQ tests have severely skewed ceilings. The Stanford-Binet V, for example, can have the ceiling extrapolated by up to 225 IQ, as can be seen in the following table:
However, the most difficult questions on the Stanford-Binet V can be easily solved by people with an IQ of 135 to 140. This produces a very large disparity between measured IQ and true IQ. Anyone with an IQ of 140, as long as they are fast enough and have a good cultural level, can reach over 200 IQ on this test, generating a gigantic amount false diagnoses of genius. This does not mean that distortions are always upwards. The way in which standardization is done, this would not be possible, because if it were like that, the average would be displaced. Therefore, upward distortions occur at approximately the same frequency and magnitude as downward distortions. As a result, really great people can score far below their true potential on this test. This has been proven several times. In the study carried out by Lewis Terman, starting in the year 1921, 1528 children with an IQ above 135, none of the 1528 selected children won a Nobel Prize, nor any other international prize of great importance in scientific areas or in Mathematics. But among the children who failed the test, two of them were awarded the Nobel Prize in Physics. This makes it evident that the Stanford-Binet, while very good and accurate for measuring IQs between 70 and 130, is not appropriate for higher levels. Terman’s group included about 100 children with an IQ over 175, but none of them won 1 Nobel, with the average IQ of Nobel laureates in Science being 154. This is another serious inconsistency in the scores produced by the Stanford-Binet at the highest scores.
How Terman’s study was carried out with people screened as children, it could be argued that the problem was not inherent in the test, but in the fact that they were screened too early. In fact, this is also one of the problems, but it is not the only one. It is not enough to explain all the observed anomalies. To better clarify this point, it is worth citing the cases of people registered in the Guinness Book for having the highest IQ in the world based on Stanford-Binet scores applied at different ages:
The first record of this modality in the Guinness Book occurred in 1966, in which Chris Harding was presented as the person with the highest IQ in the world, for having obtained a score 196-197 in the Stanford-Binet (I believe that the 1960 standardization form was used, Stanford-Binet L-M). In a normal distribution with a mean of 100 and a standard deviation of 16, only one in 1 billion people have an IQ above 196. However, the number of people screened with the Stanford-Binet was in the few thousand. In the standardization process, the samples were also in the few thousand. Thus, the best that could be done was to place the test ceiling close to 155 to 160, and even then there would still be the problem that the most difficult questions were at a difficulty level close to 140, so scores 160 would only indicate higher speed to solve problems level 140, instead of indicating an intellectual level of 160.
In the 1970s and 1980s, Kevin Langdon and several other people started showing up with scores of 196-197, claiming to share the record for the highest IQ. Some of the people who applied for registration as the person with the highest IQ in the world between 1966 and 1978 were:
- Christopher Philip Harding
- Kevin Langdon
- Bruce Whiting
- Robert Bryzman
- Leta Speyer
- Johannes Douglas Veldhuis
- Ferris Eugene Alger
Also, there were other cases after 1978 claiming the record, with nominal Iqs above 197:
- Kim Ung-yong with IQ 210
- Marilyn vos Savant with IQ 230, then corrected to 228, to 218, to 186, then 190
- Keith Raniere, with IQ 242
Finally, Guinness removed this modality. One of the likely reasons is the apparent clear fact of inadequate standardization allowing fair comparison. The adjustment metrics from childhood to adulthood scores were skewed. Also, the use of different tests produced very different scores. Another reason aggravating this was the controversy over Marilyn being accused of falsifying the dates in her report and Keith Raniere being arrested, accused of several crimes, including murder. In Marilyn’s case, I think her version is very plausible. She claims to have taken the test at age 10, but it was incorrectly recorded on her chart as if she had been tested at 11 years and 4 months. About this controversy, to the point of knowing the facts, I side with Marilyn. I explain the reason: in 2004 and 2005, I worked as a consultant at the main Psychology publisher in Brazil. I standardized and revised several tests of IQ. I could see that the number of registration errors in the data of the people examined was absurdly large, reaching more than 5%. It was very common for people registered with birth year 2040, birth month greater than 12, among others. So, I think, it’s much more likely the psychologist who examined her got the date wrong. Considering Marilyn’s history, I have no reason to question her sincerity, while the history of recording errors in psychometric reports is frequent. In Keith’s case, the facts and evidence against him are plentiful and unquestionable.
The important point is a test applied to a few thousand people in the standardization process, does not allow an establishment of a ceiling above 160 with the aggravating factor that the ceiling of difficulty does not exceed 140. Howeve, even if the test was able to measure up to 196, and even if everyone in the world was examined with the Stanford-Binet (considering that some people would be children and others would be very old), one wouldn’t find more than 3 or 4 in the world with an IQ above 196. However, in a sample of a few thousand people, there were 10 people with an IQ above 196, with some reaching 242, whose rarity is many orders of magnitude outside the limit of the number of people ever born A rarity level of 1 in 2.86 × 10^15 where the number of people already born is about 10^11.
It is a fact. This sample of a few thousand is not representative of the general population. Therefore, it is natural that more people with high IQs would be found in this sample than in a random sample of the population. If you apply an IQ test to Harvard or Cambridge students, it is natural that the average score is much higher than the average score of the general population. Also, it is very likely that some of the 10 smartest people in the US or the UK are in these institutions. The main problem is not the statistical anomaly. The biggest problem is that 100% of those people with IQs above 196 didn’t stand out as scientists, mathematicians, or authors of brilliant intellectual works that matched the measured IQs.
Marilyn herself, in an interview on the David Letterman show, made the following comment (excerpt from the interview):
D: I have uh, I have miserable teeth. I mean, they’re healthy… [Paul laughs aloud] They’re just odd, they’re odd. You know, I can eat things through fences. [laughter] Not that there’s any call for that, but uh… Allright, now Marilyn, let’s get back to you and your… uh… head. [laughter] Uh, what uh… now how do we know you’re the smartest woman in the world?
M: Well, you probably don’t know that, I don’t think anyone really knows that, not that many people have taken an IQ test. And so I had the highest score on the Benet… so far… but this very…
D: [trying to interrupt] Now when did you…
M: …small minority of people in the world have taken a test, and… [dramatically] what did Benet know, for heaven’s sake? [Paul & Dave both chuckle as Marilyn rambles] I mean back in 1904, he didn’t… [laughter] he didn’t stumble over a Rosetta Stone, he said, “This is what I think I’m gonna do,” and everybody’s been imitating him ever since.
Chris Harding, in a 2013 article stated:
“Genius is not intelligence. Genius is creative ability of the highest possible kind. True, most geniuses are highly intelligent, but this depends on the field their genius was recognized in. And here there is a plethora of problems. Recognized by whom; which people, what society, when and where. There is an old joke that goes something like I will believe in psychologists devising tests from geniuses when monkeys devise tests for psychologists. I do have ideas of my own on this, but so far no one seems interested in this. I was listed in the Guinness Book of World Records seven editions 1982-88 under “Highest IQ” and was given a certificate for this. I was also listed in 500 Great Minds of the Early 21st Century in 2002. All such lists-comparisons are temporary. There appears less and less match between persons and outcomes these days. Humanity hangs by it’s intellectual neck on the tree of tragedy –there are no Leonardo’s in the 19th, 20th, and so far in the 21st Century. Yet he/she must still exist we should think? With mass education has come the noisy ones but no Geniuses to show for it all. Bad money has driven out good money, bad people good people. The masses have come to judge the best and are part of this process to drive out the very people they need most, all in the name of incorrectly accessed political correctness. Today the system has driven down performance; today big institutional science has been a spoiler of great insights delaying progress everywhere. Today it is business as usual. The criminal come to the top. My greatest fear is that an end is coming to the centuries of progress that mankind has grown use to. The age of genius may be at an end. I’m sorry to ramble on this in such a `scatter gun’ way.”
Marilyn’s statement is superficial because it is compatible with the TV show aimed at the mass audience, but her columns in Parade magazine are very high and deep, consistent with the IQ 186-190 that she got on the Mega Test. Chris Harding’s statement, although short and on a topic that doesn’t offer much depth, also reveals a very high intellectual level. His opinion on the meaning of “genius” is questionable, but for a one-paragraph text it is acceptable. And the key point is that both recognize that scores measured by conventional IQ tests present several problems and cannot be taken too seriously when used to try to assess intelligence at higher IQ levels.
This shows that, although scores in the range of 70 to 130 are able to measure intelligence reasonably well, as the scores move away from the mean, what the tests measure gradually ceases to be intelligence and becomes something more shallow, such as reasoning speed for trivial questions or mechanical repetition of tasks. The problem is that as the IQ to be measured increases, the test continues to measure the same variable, but the meaning of intelligence changes. For children aged 8 to 12 with an IQ between 80 and 130, it may be appropriate to measure the ability to spell words without making mistakes as a satisfactory criterion for determining written communication aptitude. However, if applying this same method to try to estimate communication aptitude writing by Shakespeare or by Dostoevsky, it is evident the result will be skewed. It is neither because these writers are too quick at spelling nor because they are infallible at it. They can even make more mistakes than a well-trained 8-year-old who has “talent” at spelling. The point is, this criterion is no longer useful at the levels of Shakespeare, Goethe, or Dostoevsky. In fact, it ceases to be useful at much lower levels, close to 125 or 130. The same problem occurs when trying to use elementary questions like the Stanford-Binet ones to measure intellectual levels above 140.
The fact is the Nobel prize-winner average IQ is at the rarity level of one in 3,000, while the frequency of Nobel prize-winner in the population is less than one in 1 million, also corroborates that scores above 130 on the Stanford-Binet are highly distorted, dramatically failing to “let go” of the brightest people, while at the same time incorrectly selecting several who are not really bright, but just quick at performing trivial tasks.
This is not a defect unique to the Stanford-Binet. All the best IQ tests including WAIS, Raven, Cattell, DAT, D70, etc., have this same problem (and, obviously, there are more and worse problems in tests that aren’t the best). One of the main reasons for this is the same as already mentioned: these tests attempt to measure IQs at levels well above 140, but do not include questions with a difficulty level above 135.
To solve this problem, in 1973, Kevin Landgon created the LAIT (Landgon Adult Intelligence Test). Tthe first really difficult intelligence test, capable of measuring correctly until close to 165. In 1982, Ronald Hoeflin published his Mega Test, later the Titan Test, Ultra Test, and Power Test. The Hoeflin tests could correctly measure up to about 170 or even 180 IQ.
Thus, a new era of intelligence testing has been inaugurated. The traditional tests used in clinics to measure in the range of 70 to 130 continued to exist, covering more than 95% of the population, and it also became possible to measure intelligence at much higher levels. However, these tests have not yet reached the “critical point” that allows us to correctly identify genius minds. The people with the highest scores on the Hoeflin tests are undoubtedly very smart: Rick Rosner, Chris Langan, Marilyn Vos Savant, etc. With scores of 190 or above. But when you compare the intellectual output of these people with that of a Nobel laureate with an IQ of 160, the difference is blatantly favorable to the Nobel Prize. Something was still missing from the variables to be measured at the top of the difficulty level. In the years and decades that followed, other tests were created, including the Eureka, Logima Stricta, and the Sigma Test.
Sigma Test, since its first version, tries to be innovative in several aspects. This does not mean that it has achieved this purpose, but, at least, we are trying. Some of the results obtained have been encouraging. There is controversy over how much difficulty the Sigma Test can actually measure correctly. Some people think the actual ceiling is no more than 180, others think it goes up to 200 or a little more. This is difficult to determine until the number of people evaluated is large enough or until some great genius internationally recognized as such (Fields Medal, Abel Prize, Nobel Prize in Physics) who is evaluated by the Sigma Test.Regardless of the difficulty ceiling, Sigma Test brings other relevant innovations. Some of them have already been experimentally corroborated. Among these innovations, the most important is the new standardization method, first introduced in 2000 and first applied in 2003.
The new normalization method used in Sigma Test is distinguished from all others by generating scores whose antilogs are on a scale of proportion. Furthermore, this method makes it possible to correctly calculate the corresponding percentages, avoiding the inflated results that are produced by traditional methods. This topic is covered in more detail in other articles.
Another differentiator is the variety of cognitive processes required to solve the questions. This is extremely important for measuring intellectual capacity in a wide range of settings. The ability to play chess, for example, measures a very specialized and very narrow latent trait, which cannot be interpreted as representative of general intelligence. Chess skill is positively correlated with intelligence, but as the rating moves away from the average, this score is determined more and more by chess-specific skill and less and less by general intelligence. The same happens if a test uses exclusively series of figures, or if it exclusively uses a series of numbers. The measured variable cannot be interpreted as representative of general intelligence. This statement runs counter to some “psychometric mantras” repeated for decades – in particular about homogeneity (the higher, the better) and about g saturation, so it requires a little more detailed analysis:
Series of figures have the virtue of minimizing the requirement for knowledge, preventing cultural and age factors from interfering with the result. This is a good thing. On the other hand, they limit the ceiling of difficulty and complexity, but the main problem is excessive homogeneity.
There are many different ways to measure homogeneity. One of the best and most common is through Cronbach’s α.
In order to understand how Cronbach’s α works, first, it is worth explaining how the Kuder-Richardson works: the idea is simple. The test is divided into two equivalent halves and the score that each person obtained in each half is verified. This division can be between odd and even questions. It can be by lottery, or by any other reasonable criterion. If the halves are equal, each person is expected to score approximately the same score on each half. The idea of Cronbach’s α is similar, but all covariances between all items are considered, making this measure independent of the criterion adopted to separate the two halves. This is almost equivalent to comparing all possible combinations of two halves.
It is positive and desirable that a good test has a high Cronbach’s α (above 0.7), because it indicates that the test items are contributing to measure the same variable. This everyone knows and repeats religiously. On the other hand, it is bad if Cronbach’s α is excessively high (above 0.9), because it indicates that the test items are not covering a sufficiently wide range of the characteristics that should be measured, that is, the items are excessively redundant and specialized. This fact is apparently neither known nor well understood, so it requires a little more detailed explanation. For this, I will use a didactic example:
A test consisting exclusively of 60 numerical series tends to present Cronbach’s α greater than a test that includes 20 numerical series, 20 series of figures and 20 analogies. If the difficulty distributions are the same on both tests, then the one with 60 numerical series is likely to have a higher Cronbach’s α, in which case having a higher Cronbach’s α may be worse. In other words, a Cronbach’s α of 0.85 may be better than 0.92.
An analogous effect can also produce illusions about g saturation, making a test appear to be more g-saturated than it actually is, simply because it is excessively homogeneous. In a test that is too homogeneous, the first factor extracted may be sufficient to explain more than 80% or 85% of the variability, not because the test is in fact more saturated with the g factor, but because within the limits of what is being evaluated by this test. Test, a leading factor common to all items accounts for 80% to 85% of the variance or even more.
In this context, pseudo saturation of g is a bad symptom, unless the ultimate goal is to measure the ability to solve series of numbers and figures. But this is usually not what you want to measure. The purpose of a good intelligence test is to gather an appropriate list of questions to assess your ability to solve real problems. The objective is not the score on the test itself, but to ensure that this score is able to reflect the ability to solve different problems in real life. In this, STE stands out, as it includes several problems with a structure very similar to real problems.
The ability to solve series of pictures is also useful, because this same ability also contributes to solving other problems in other situations. However, the direct measurement of the type of skill you want to know is preferable to measuring a correlated attribute. To clarify this problem, let’s analyze two more well-known variables: weight and height.
People’s weight and height are moderately correlated variables. This means that by knowing a person’s weight, one can estimate that person’s height. However, if it is possible to directly measure one’s height, this is better than measuring weight and trying to estimate height based on weight. If it is not possible to measure height, and the only information available is weight, it is possible to use this information to try to roughly estimate height, but the error can be very large, because there are short people with a lot of fat mass and there are tall very thin people.
Therefore, if there is a group of variables more closely related to height, such as femur size, foot size, arm size, then measuring these variables should provide a more accurate estimate of height than trying to estimate height with based on weight. Femur size is not exactly proportional to height, but variation in femur size preserves the proportion to variation in height much better than variation in weight to variation in height. The same applies to foot size and arm size. When you consider femur size, foot size, and arm size together, you can make a much more reliable estimate for height than if you tried to estimate height on the basis of weight.
So using a series of figures test to estimate intelligence is like using weight to estimate height, that is, it works, but the errors and distortions are large. Furthermore, as you get closer to the higher levels of weight, the error also increases and the same happens when you want to measure correctly at the highest levels of height, because the higher levels of height rarely correspond to the highest levels of weight. The tallest people in the world are not the same as the heaviest people in the world. Usually, the heaviest ones are normal height or just a little above normal.
But if the measurement were based on the size of the femur, arm, and foot, estimating height based on each of these variables, then averaging the results, the estimate for height would be much closer to the correct value. Another detail to consider is that in addition to the correlation between femur size and height being much stronger than between weight and height, this correlation is preserved at the highest levels, so that the largest people in the world also have larger femurs, bigger arms and bigger feet. Therefore, the measurement of these body parts remains effective in estimating the correct height of people at all levels, from the average population to the tallest people in the world.
Likewise, the use of items with the properties of the Sigma Test questions, closely related to the cognitive processes that represent intelligence, covering a wide variety of cognitive characteristics and skill levels, provides a much more accurate and realistic estimate for intelligence.
There are also disadvantages to the Sigma Test, which produces less fair results if it is applied to rural groups or groups with a level of education far below the Middle School grade. But I don’t see much need to create tests aimed at this audience, because there are already good tests for that, including Logima Stricta and some of the excellent tests by Iakovos Koukas and YoungHoon Kim. So my focus is on trying to fill a gap that has existed since the early days of IQ tests, which is trying to correctly measure the intellectual level in the higher strata. The Binet tests were able to measure correctly up to about 135, then the Langdon and Hoeflin tests were able to correctly measure up to about 170. The Sigma Test Extended aims to realistically and accurately measure above 190 and perhaps above 200.
As already mentioned, Hoeflin tests pioneered the correct measurement of IQ at levels far above the limits of traditional IQ tests, but as there was no proper method for calculating the corresponding percentiles, norms were calculated using the methods available to standardization, resulting in skewed estimates, especially near the ceiling.
The “correct” ceiling for Mega Test, based on data that was available on the Miyaguchi website and using the same standardization method as the Sigma Test 2003 standard is about 186, very close to the nominal ceiling of 190+ (~ 193) which was adopted by Hoeflin. The ceiling calculated by Grady Towers was 202. Bob Seitz also made an attempt to establish a new norm that would fit the correct levels of rarity, and he came up with around 170, very close to the rarity norm I found in 2003 for the ceiling of the MegaTest (168.5). This divergence between the results obtained by Towers and by Seitz already signaled a disparity between the true rarities and the rarities obtained based on the hypothesis that the scores were normally distributed. By the late 1990s, the problem was well established: the actual rarity did not agree with the IQ scores measured in the tests. But the solution to this was not yet clear.
The nominal IQ score does not present major problems. The Mega Test ceiling presents an error of 7 points, which is tolerable and for lower scores the error is smaller and smaller. However, the corresponding percentile is very different from the correct one. The theoretical level of rarity for IQ=193, assuming the distribution of scores were perfectly adherent to a Gaussian, would be one in 325,000,000, but the correct level of rarity, given the true shape of the distribution of scores, is about one in 435,000. If you consider the correct ceiling to be 186 instead of 193, then the rarity level is one in 130,000. So the true level of rarity differs from the level indicated in the standard by a factor greater than 2000. A huge mistake. The data on Miyaguchi’s website is incomplete, so the 186 IQ value indicated as “correct” for the ceiling may be slightly different, perhaps close to 190. However, the percentile distortions are too large to be explained by some bias present in the data available on the Miyaguchi website. This is a serious methodological error that has been systematically repeated for decades.
Hoeflin’s and Landgon’s tests differ in some important points. Langdon’s tests, as well as some tests by Cooijmans, Robert Lato and others, followed a similar line to Raven’s tests (figure series), while Hoeflin’s tests followed a more similar line to that of Binet and Wechsler (diversified).
At this point, it is worth recapping how the first attempts to measure intelligence were, in fact. I won’t be redundant with the Historical Summary article on Intelligence Tests; Anyone interested can access it for more details. Here I will give a much briefer summary focused on the topics we are covering.
The Binet test represents an important advance in the evolution of cognitive tests. After the attempts by Francis Galton (1884) and James Cattell (1890) to measure intelligence proved unsuccessful, Alfred Binet (1904) tried to approach the problem from a different perspective. Galton and Cattell believed that it would be possible to measure the elementary components of intelligence, while Binet decided to measure the combined result of these components in synergistic action, obtaining much more promising results, making it possible to identify mild deficiencies and some aptitudes. This suggests that the combined use of questions that require different types of thinking working together in solving complex problems may work better than questions that try to measure each type of thinking separately. The STE follows a similar line, betting on the measure of a combined set of skills to solve complex problems, with the differential of including questions that reach levels much higher of difficulty than the Stanford-Binet ceiling (140), reaching and surpassing 190 and even 200.
While Binet test is one of the best for correctly measuring IQs between 70 and 130, it fails badly by continuing to produce scores far above what it is actually capable of measuring. The same problem is present in the tests by Wechsler, Cattell Culture Fair, and others. The extrapolated Stanford-Binet nominal ceiling reached 225, but the actual ceiling never went above 140. I’m not saying the IQ 140 is low; to say so would be a gross error. What I am saying is that a test with a ceiling of 140 would be like a clinical ruler to measure height with a maximum limit of 1.87 m. The 1.87 m threshold is not low, but it is also not enough to serve a considerable fraction of the population.
In fact, the problem with the Stanford-Binet standard is worse than that. It is as if it were a ruler with a nominal ceiling of 2.15 m, but that started to get crooked and with the 1 cm intervals getting smaller and smaller for heights above 1.80 m. On this ruler, the size of 1 cm in the range of 1.50 m to 1.80 m is approximately uniform, but above 1.80 m, each 1 cm interval becomes increasingly narrow. When it gets close to 2.15 m, every 1 cm is so short that it is less than half a 1 cm in the region between 1.70 m and 1.80 m. With a ruler skewed at this level, measurements are only reasonably reliable up to 1.80 m or, with a little optimism, up to 1.85 m.
The below image shows an example of a distorted (uneven interval) scale where up to a certain point (the first 10) the intervals are uniform, but then they get increasingly narrower:![]()
Using a ruler that had each unit spaced this way would obviously produce big errors. This is basically what happens with almost all IQ tests, including the Sigma Test before 2003, because although this method for standardization had already been devised and published in 2000, first Sigma Test standard had to be determined by comparison with other tests already standardized by existing methods and the number of tests in Sigma Test in 2000 was still not enough for adequate standardization using the new method. Therefore, the first standard applying this method was in 2003.
Therefore, all traditional IQ tests and all high range IQ tests had this distortion up to 2003 and this distortion causes several problems.
If there were such an error in a ruler or a tape measure, where one part of the ruler was correct and another was distorted, it would be easy to correct it by using the “healthy” part to compare side by side with the anomalous part, and then repair the error. But on an IQ scale this is much more difficult and complex to correct. On a crooked ruler with a distorted scale, the problem is noticed visually, but the distortions in the scale of an IQ test are invisible and can only be detected with an adequate statistical treatment. In addition to the detection not being trivial, the correction is even more difficult because it is necessary to establish a reference scale that is invariant. Binet tried to do this using ages and it was an interesting initial idea, but it was quickly found that it didn’t produce an interval scale. To produce a ratio scale is even more difficult.
The solution adopted in the 2003 Sigma Test standard manages to generate a proportion scale taking advantage of Bill McGaugh’s idea of converting Chess rating into IQ. However, FIDE rating, USCF rating and especially online ratings are highly distorted, in addition to the inflationary effect. Therefore, before it was necessary to establish an appropriate rating scale from which a potential ratio scale would be established and then this could be applied to the IQ, it is clear that Bill McGaugh’s formula could not be used in its original form either, because it was calculated based on the FIDE rating, but it was an important inspiration.
The rating calculation method is described in this book https://www.saturnov.org/livro/rating and the distribution of scores using this method is this:

By way of comparison, the distribution of the FIDE ratings is as follows:

And the distribution of USCF ratings is this:

Converting FIDE ratings with this distribution into IQ scores or converting USCF ratings into IQ, it would require some acrobatics, but even then there would be major distortions. That’s why it was first necessary to recalculate the ratings. In this process, I’ve already taken the opportunity to improve the traditional method, in addition to introducing a new one based on the quality of the bids. Furthermore, the two distributions, the IQ and the rating were fitted to suitable curves, rather than using the forced assumption of a Gaussian distribution. Altogether, 91 continuous and 17 discrete distributions were tested to verify which one is the most appropriate to represent this data set. In the preliminary selection, Kolmogorov-Smirnov was used to assess the goodness of fit. In a later step, Anderson-Darling and a chi-square comparison were used with a fitting model of a neural network. In cases where the discrete distribution made the comparison impossible because it contained the n-factorial function, this was replaced by Gamma (n+1). The following graph shows a summary of all tested curves:

The distributions tried were these:

After determining the most suitable curves to represent the distribution of the IQs and the most suitable for the rating distribution, some further adjustments were made to correct for the self-selection that varies with the rating band and with the IQ band and does not vary in the same proportion. More details on the procedures are described in volumes I and II of the book “CHESS – 2022 Best Players in History, Two New Rating Systems“.
By these means, it was possible to slightly refine the values of some parameters used in the standardization of the Sigma Test, highlighting some of the conceptual and quantitative advantages that were already present in the 2003 standard.
The end result is that IQ measured by ST or STE generates scores on practically the same scale as other high range IQ tests, i.e. a person with a score of 180 on the Mega Test should score around 180 on the STE, while two other people with a score of 150 and 120 on Mega Test should also get around 150 and 120 on STE respectively. For scores above 170 and especially above 180, ST generates slightly lower (and more correct, less inflated) scores than other tests. For scores below 170, there is practically no difference.
The ST and STE percentiles are realistic, so they are much lower than those generated by the other tests. Therefore, if your goal is a certificate with too many nines to hang on the wall, unfortunately, Sigma Test won’t be able to help you. But if you are sincerely curious to know your real intellectual capacity, based on a correctly standardized scale and with an adequate level of difficulty, and if you want to know the true percentile in which you are in relation to the world population, among other information (*), STE is exactly what you are looking for.
(* A supplementary information that cannot be calculated based on other standards is the “proportion of potential”. If you are interested in knowing exactly what this means, please read this article: https://www.sigmasociety.net /scalesqi. In summary, the ratio of potential determines the number of people with IQ=100, working together, to achieve the same level of “intellectual output” as a person with IQ=x. This calculation requires that the scores are on a proportion scale so that the values are not distorted).
Another detail that I would like to comment on is the difference between intrinsically difficult questions and very difficult questions.
Questions that are just laborious, but not really difficult, measure perseverance, persistence, patience and other attributes rather than actually measuring intelligence. When testing with no time limit is applied, it is necessary to take some additional care, to prevent a person from having a higher score just by dedicating larger time. For each problem, there is a curve that determines the probability of success as a function of the time devoted to it and this curve reaches an asymptotic limit that means that after a certain limit, dedicating more time does not contribute to increasing the probability of success in a proportion that justify the greater amount of time invested. When this curve is similar to a straight line, it indicates that the problem is inappropriate because it predominantly depends on mechanical effort and work, but if the curve is similar to a logistic one, it indicates that the problem predominantly depends on intellectual capacity. That’s because in the most difficult problems, if the person solves 5% of the problem in 5 minutes, he will solve approximately 10% in 10 minutes, 50% in 50 minutes, and so on. These are problems characterized by repetitive tasks, where repeating 10 times implies going twice as far as repeating 5 times. But in cases of predominantly intellectual problems, it is different. In the first 10% to 20% of the time, the person makes almost no progress, just trying to understand and outline a solution strategy. Then the resolution begins and at this stage, advances occur quickly with 50% to 70% of the central region of the logistic curve. As you progress in the resolution, getting closer to the definitive answer, you realize that there are small details that can still improve the answer. But these details require more and more time and are smaller and smaller and contribute less and less to the final result. The curve below represents this situation:

It reach a point where the person concludes that it doesn’t make sense to spend more time to keep improving the response, because they would need to dedicate a lot of time to producing small increments. On some of the great problems of science, this takes centuries. Newton’s solution, for example, was later improved by Einstein. In the future, it will be improved again. The atomic model has also experienced several stages of evolution and this happens in different situations in which one is dealing with a difficult and predominantly intellectual problem. If it is a laborious problem, where the resolution is more repetitive and mechanical, the graph that determines the percentage resolved as a function of time is more similar to the one below, where the time devoted to the resolution grows almost linearly with the percentage resolved.

The type of problems desirable for a good intelligence test is the one that presents the behavior of graph 1. And all the items in the STE are designed with this objective in mind.
Graph 1 is a simplification, because many times there can be several stagnations in the resolution process. The person advances quickly, until he encounters some difficulty that impedes the advance until a strategy is developed to solve it. Then it goes back to solving the problem, then it hits another obstacle, etc. Several of the more difficult problems in STE have this characteristic, where the person needs to have more than one insight during the solving process in order to be able to keep moving forward.
Since the time that Langdon created the first high range IQ test until the mid-1990s, there were less than half a dozen such tests. But from the 1990s onwards, several others were created and currently there are hundreds. I don’t know all the high range tests that currently exist, so I can’t generalize, but I can say that many of these tests are made up of difficult questions, but they are not really difficult. This is common in tests with a series of numbers or figures, where if a person spends enough time, testing many different alternatives in an organized way. At some point, he will discover the underlying pattern. Of course, the use of some heuristics can speed up this process, but they are very basic heuristics. After a person trains to solve many tests of this type, he ends up becoming “specialized”. There are also issues depending on the person having a vast vocabulary to solve an analogy, without there being any intrinsic difficulty in the analogy itself. The same applies to association problems. Certainly ST and STE are not immune and have their own flaws and limitations, but, as far as possible, we have tried to avoid some of the problems listed here.
Compared to the best traditional IQ tests, such as Stanford-Binet and Wechsler, the high range IQ tests adequately solve the problem of measuring correctly at the highest levels of difficulty, reaching 170 or even 180 and in this respect the ST did not bring great contributions, except perhaps for pushing the ceiling up a little as far as you can measure correctly. But there are other aspects in which the ST made relevant contributions:
- Generation of scores on a ratio scale
- Correct determination of percentiles and rarity levels
- Unprecedented determination of proportions of intellectual production potential
- Adequacy of different cognitive processes to the skill level measured
- Other possible advantages: https://www.sigmasociety.net/escalasqi
Mothers and fathers often find their kids the most beautiful in the world, so it’s possible that my opinion of ST and STE is skewed. So it’s best to rely on the opinions of other people who have been tested with Sigma Test and have given their testimonials. A list of these opinions can be accessed here: https://www.sigmasociety.net/depoimentos. So, although, maybe, my opinion is biased, ST and STE were built thinking about solving some of the weaknesses (from my point of view) that are present in other tests. I believe that the ST and STE are the psychometric instruments that best meet my criteria for correctly measuring intellectual level at the highest levels. Some other deeply talented people would agree with this opinion, others might not. This space is open to receiving new positive and negative opinions about ST and STE.
For these reasons, in Sigma Society, as the cut-off is 132, within the range in which other tests also work well, there was no problem in accepting other tests as criteria for admission, because the distortion is not great for scores up to this level. In Sigma III, there were some doubts about whether to accept other tests. It was decided to initially keep only the ST with the possibility of accepting other tests later as well. As of Sigma IV, only the ST itself was accepted. For these same reasons, STE will be accepted as the standard exam for admission to Sigma VII and the Deliberative Council in Immortal Society. It will also be used as criteria for admission to Sigma VI, Sigma V, Unicorn, Platinum, Sigma IV, Immortal Society, Sigma III and Sigma Society.
Having made these clarifications, we hope that everyone who accepts this challenge will enjoy the pleasant intellectual adventure offered by the STE questions and obtain fair and accurate results.
Sigma Test Extended is a harder, larger and newer version of our Sigma Test. See below some opinions about the Sigma Test:
“I’m really enjoying the SIGMA test. I’ve already printed it out and started answering your questions. Allow me to congratulate you on your test. In fact, it’s incomparably better than the IQ tests I’ve taken.” Renato P. dos Santos, Ph.D. in Physics, Post-Doctoral in Artificial Intelligence, Universitaet Karlsruhe, Research Institute for Symbolic Computation, Researcher and Preceptor of Ph.D. students, member of British Blockchain Association, referee of International Journal of Physical Sciences, Journal of Virtual Worlds Research, Concurrency and Computation: Practice and Experience, Financial Innovation and Advanced Theory and Simulations, Honorary member of Immortal Society (IQ>164).
“I appreciate immensely the Sigma Teste because I believe that in many questions are needed both intelligence and imagination to solve them.” Petri Widsten, Ph.D. Summa Cum Laude in Chemestry, University of Helsinki, best Ph.D. Thesis of Finland 2002-2003, 1st place in several IQ Contests, include in “World IQ Challenge”, member of Sigma Society VI (IQ>196).
“The SIGMA test was one of the most interesting things I have done in the realm of puzzles because the later questions were so clever and had so many different levels of solution. I finished the test as a personal challenge, and it gave me great satisfaction. Some of the SIGMA test puzzles are REALLY beautiful. They are a work of art!” Peter David Bentley, D.Phil. and Post-Doctoral in Physiscs, University of Oxford, co-founder of Ludomind, Managing Director of INFICON Ltd., member of Sigma Society V (IQ>180).
“Thought tests and puzzles always have amused me, this is the first IQ-test I have bothered to send in for scoring. I found myself increasingly absorbed by the intellectual art behind the questions in this test. Together with achievement, I rank creativity on top of the scale, which you elegantly have combined with divergent / convergent thinking. Thank you for creating a great test. I now look forward to take the Sigma Test VI! Provided my scores are sufficient, I intend to apply for membership in the Sigma Society.” Ulf Westerlund, Ph.D. in Neuroscience, member of AANS (American Association of Neurological Surgeons) and EANS (European Association of Neurological Surgeons), member of Sigma Society IV (IQ>164).
“I also want to say to you that the Sigma Test is incredibly brilliant. It was by far the best test I have ever taken and enjoyed it very much.” Dylan Taylor, MBA at University of Chicago, Chairman & CEO of Voyager Space, Young Global Leader in 2011 Prize (World Economic Forum), Global Leadership and Public Policy for the 21st at Harvard Kennedy School, highest score on the English version of the Giant Test, Honorary Member of Immortal Society (IQ>164).
“Thank you for a fascinating, thrilling and a very challenging test! I will recommended it to friends and colleagues who might be interested in this kind of challenge. My next mission will be Sigma Test VI.” Kristian Heide, Ph.D. in Astrophysics, world record in Think Fast game, member of Sigma Society IV (IQ>164).
“I would like to take the Sigma Test. (Which I believe has the best end excellent questions.)” Emrehan Halici, M.Sc. in Electrical Engineering, President of Turkish Intelligence Foundation (1995-…), Vice President of FIDE – Fédération Internationale Des Échecs (1998-2002), Member of The Turkish Parliament (1999-2002).
More comments on the Sigma Test here: https://www.sigmasociety.net/depoimentos
INSTRUCTIONS:
Try to answer all the questions, including those you are not sure about.
There is no time limit, there are no restrictions on the use of auxiliary tools. Dictionaries and encyclopedias can be consulted at will.
Along with your answers, please also submit the scores you obtained on other tests (clinical IQ tests, online tests, high range tests, SAT, GRE, ACT, etc.), the date you were examined with each test (can be approximate), the score obtained (informing standard deviation) and the name of the test. We also ask that you inform the other societies in which you participate or have participated and other information that you consider important.
In parentheses is the approximate IQ corresponding to the difficulty of the questions at that level. This helps to avoid oversights by underestimating the difficulty of some question, as well as avoiding wasting time looking in simple and easy questions for complications that don’t exist.
A book will soon be published with the 1,000 people with the highest IQs in history and the 100 people with the highest IQs today. Many other details about IQ tests, inflated scores, etc will be discussed in this book.
Sigma Test Extended – Questions
Level I (100) Average
- In 1976 Marcelo was 11 years old. Assuming he is still alive, how old will be in 1999?
- If 13 bullets cost $ 3.90, how much do 31 bullets cost?
- A large box measures 60 cm wide, 50 cm long and 30 cm deep. What is the maximum number of boxes measuring 10 cm wide, 10 cm long and 10 cm deep that fit inside the big box?
- If 12 people do a job in 12 days, how many people are need to do the same job in 1 day?
- A collection consists of 12 volumes; each volume has 300 pages; each page has 50 lines and each line has 100 letters. What is the total number of letters in the collection?
Level II (110) Above average
- A company has enough stock to supply its clientele of 2,500 people for 12 months. How long would this stock last if the clientele grew to 6,000 people?
- If one horse can pull 600 kg, how many horses are needed to pull 6,150 kg?
- The sum of ages of Fernanda and Andreia is 18 years. What are their individual ages, given that Andreia is twice as old as Fernanda?
- We have 7 cubes with edge = 1 cm each. They are glued together in such a way that the total external surface after gluing is as small as possible. Calculate the area of this surface. The image below shows an example of cube organization in which the criterion of minimizing surfaces is not satisfied. (EXT 2022)

Level III (120) Superior Intelligence
- Ricardo weighs 30% more than José. If Ricardo were to lose 10% and José gains 20% of weight, which one of them would weigh more after that. Explain.
- A planetary system has, in addition to the main star, 9 planets. Each planet has 7 primary satellites. One out of every 21 primary satellites has 3 co-orbital satellites. How many celestial bodies are there all together?
- On a staircase with 1,000 steps there was 1 gram of gold on the 1st step, 2 grams on the 2nd, 3 grams on the 3rd, 4 grams on the 4th, 5 grams on the 5th and so on, so that there was 1 kg of gold on the last step. Given that 1 gram of gold is worth 11 dollars, calculate the total value of the gold on the staircase (in dollars).
- Inside a room is a bookcase, a gold cube, and a platinum cylinder. The height of the cylinder is equal to its diameter. The 3 objects are on the ground, and that is flat within the limits we can measure. The top plane of the shelf is parallel to the ground plane. If the cube is on top of the shelf and the cylinder is on the floor, the distance between the top of the cube and the top of the cylinder will be 204 cm. If the cylinder is on top of the shelf and the cube is on the floor, the distance between the top of the cube and the top of the cylinder will be 156 cm. How tall is the shelf? (EXT 2022)
Level IV (132) Gifted, Talented, High Abilities
- In a room 99% of the people are men. How many men would have to leave the room in order for this percentage to decrease to 98%? It is known that the number of women in the room is 3.
- On a chessboard with 64 squares (8 x 8), two kings can occupy 3,612 different positions. How many different positions can two kings occupy on a chessboard with 117 squares (13 x 9). Two kings may not be on the same square at the same time or occupy adjacent squares.
- Marcelo had apples, half of which he gave to his brother. The latter gave 75% of the apples that he had gotten to be equally shared between his three cousins: Anderson, Joao and Mané. Anderson bought 7 apples more and gave half of all his apples to his brother Mané. Mané’s apples then totaled 17. How many apples did Joao get?
- Maria went to a farm to buy eggs. Returning home, she gave half of them to her sister who, in turn, gave a third of those she had gotten to her boyfriend. The latter, after eating one third of the eggs that he had gotten, gave the rest to his cousin. Given that each egg weighs 70 grams, that Maria cannot carry more than 2.5 kg, and that the eggs were raw, calculate how many eggs the cousin of Maria’s sister’s boyfriend received.
- The mayor Joao and an important bachelor businessman, called José, held a large barbecue. Aside from the businessman José, the mayor Joao and his wife, the number of people present equaled the number of 100 dollar notes that the mayor spent multiplied by the the number of 100 dollar notes that the businessman spent. Given that, on average, every person consumed the equivalent of US$6.40 and that the mayor invested US$ 1,700, calculate how much the businessman José invested. (Note: the businessman José, the mayor Joao and his wife took part in the consumption)
Level V (144)
- A Formula-1 race car is racing around a circular track, completing the first lap in 3 minutes with an average speed of 144 km/h. In what time must a second lap be driven in order for the average speed of the two laps to increase to 300 km/h?
- When Antonio looked at his watch, he noticed that the hour hand was lying exactly over the minute hand. What time will it take for this to happen again? (both hands move at constant rates)
- A train with 2 cars is traveling at a speed of 80 km/h from town X to town Y, located 800 km from each other. At the same moment that the train departed, a passenger started to walk back and forth from one end of car B to the other at a speed of 100 cm/s. Arriving in town Y, the passenger had already gone and returned 720 times. The length of car A is that of car B plus one fourth of the length of the locomotive, and the length of the locomotive equals the length of car A plus one fifth of the length of car B. What is the total length of the train?
- What percentage of the Moon’s surface is illuminated by the Sun at specific moment? Justify. (Moon test)
- The image below is a photo montage of the Moon over the Atlantic Ocean. Assuming it wasn’t a montage, what country was the person who took the photo in? Justify your answer. (Moon test)

Level VI (156)
- Several faucets were used to fill up six tanks. For one hour, all the faucets discharged water in a reservoir, which distributed it between four of these tanks: A, B, C and D. After that, for one hour, the faucets discharged water in a double funnel which directed half of the water to tanks E and F and the other half to the reservoir which, in turn, continued to distribute its water between tanks A, B, C and D. With this, tanks A, B, C and D were full. To fill tanks E and F up, it was necessary to use one faucet, which, for two hours, distributed its water between tanks E and F. After this all the six tanks were full. What was the number of faucets initially used? (Note: all the faucets had the same water flow rate and all the tanks had the same volume).
- Several rectangles are drawn on a plane surface in such a way that their intersecting lines form 18,769 areas not further subdivided. What is the minimum number of rectangles that must be drawn to form the described pattern?
- Several straight line segments are drawn on a plane surface in such a way that their intersecting lines form 1,597 areas that are not further subdivided. What is the minimum number of line segments that must be drawn to form the described pattern?
- On a plane surface 1 + 10^1,234,567,890 triangles are drawn. What is the maximum number of areas, not further subdivided, that can be formed as these triangles intersect each other? (Contributed by Rodrigo de Almeida Rodrigues)
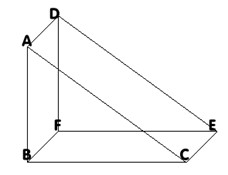
- According to Fermat’s Last Theorem, a^n + b^n = c^n has no solutions for n > 2 (a, b, c and n must be positive integers). In 1992, I proved this in a simple, yet incorrect manner. This was my reasoning: Fermat’s Theorem is a generalization of Pythagoras’ Theorem, which asserts that the sum of areas of the squares drawn on the legs (short sides) of a right triangle equals the area of a square drawn on the hypotenuse of the same right triangle (a^2 + b^2 = c^2). If we try to generalize that theorem, going from 2 to 3 dimensions (a^3 + b^3 = c^3), we have a triangular prism formed by displacement of a right triangle along an axis perpendicular to its face, as illustrated by the figure below. We can construct a cube on one of the three quadrangular faces of that prism. Two of those faces correspond to the legs of the right triangle (ADFB, BFEC) while the larger face corresponds to the hypotenuse (ADEC). It is possible to construct a cube on one of the faces, implying that the 4 sides of that face have the same length. This affects the whole prism, causing the cube constructed on the other face to have the same size than that constructed on the first, for if AB=BF and BF=BC, then AB=BC. In that way, no cube can be constructed on the third face, for if AC represents the hypotenuse, then AC cannot be equal to to AB. Therefore, a^n + b^n = c^n has no solution for n=3. Following the same line of reasoning, we can show that it has no solution for any number of dimensions larger than 2. What is the error in this proof?
- João was kidnapped by aliens and taken to a distant planet. He gets two challenges. If he solves one of them, he will gain his freedom and be able to return to Earth. If he solves both, he will also win 100 tons of the mineral he prefers, gold or platinum, which will be delivered to his home on his planet. Challenge 1: on this planet where he is, an alien climbed on top of 3 mountains A, B, C, located respectively at latitudes 27º, 27.5º, 27º. From point A, points B and C appear 68.174 degrees apart. From point B, points A and C appear 54.821 degrees apart. From point C, points A and B appear to be 57.086º apart. The distance between points A and B is 100 km. What is the approximate diameter of this planet? (EXT 2022)
- Challenge 2: This planet has part of its surface covered by oceans and part by rocks/land. João is taken to an island on which there is a volcano, the top of which is the highest part of the island. When he returns to the mainland, João realizes that, from the beach, it is still possible to see the top of the volcano, almost disappearing into the horizon. Knowing that the height of this volcano is 3500 m, what is the distance from this beach to the top of this volcano? (EXT 2022)
Level VII (168)
- A certain gear system consists of 5 concentric, superposed discs: A, B, C, D and E, which are mounted on a solid platform, taken as a stationary reference. The discs have different sizes and spin at different speeds. All the discs spin at constant rates, some clockwise, some anticlockwise. Each disc has a red dot on its surface, and initially all these red dots are not lined up. At a given moment, all the discs start to spin simultaneously, each at its own speed, without any contact between them. It takes 7 minutes for disc A, 13 minutes for disc B, 17 minutes for disc C, 19 minutes for disc D and 23 minutes for disc E to complete a full 360-degree spin. After a certain time, all the red dots were aligned, disc A being in the same position that it was 2 minutes after the discs started to spin, disc B being in the same position that it was 3 minutes after the discs started to spin, disc C being in the same position that it was 4 minutes after the discs started to spin, disc D being in the same position that it was 7 minutes after the discs started to spin, and disc E being the same position that it was 9 minutes after the discs started to spin. How much time elapsed from the moment the discs started to spin until the discs reached that configuration for the first time?
- Pedrinho entered Dona Maria’s Stationer’s Shop and asked her to sell him a geometric ruler for drawing a spiral with a small concentric circle. Dona Maria, a Sigma Society member, told the boy that there were no rulers for drawing spirals. But after thinking the problem over, she found a way to make a drawing like that, and described the method to the boy. She sold the boy the material needed right away, which he paid with a US$ 10.00 note, receiving some change. He went home and made the drawing without any problems. Describe a method to perform Pedrinho’s task having the same US$ 10.00 at your disposal for buying the material needed. The drawing must show a satisfactory agreement with the described pattern (a spiral with a small concentric circle), without large irregularities in the spiral. (Modified in 31 Aug 2001 at the suggestion of our friends Petri Widsten and Nikos Lygeros, as the earlier question with the 9 cubes was similar to one of the questions of the Eureka Test).
- A man takes a deep breath, filling his lungs completely with air. Then he holds his breath and a tape measure is used to measure his chest circumference, which turns out to be 106 cm. After that, the man exhales so that all the air is expelled from his lungs. His chest circumference is measured again, and is now 84 cm. Having $10 at your disposal for buying material, find out the volume of air that his lungs are able to hold.
- The speed of a person’s reflexes can be determined based on the time elapsed between a stimulus and the response of that stimulus. For example: A lamp remains unlit while we observe it. On receiving the stimulus “the lamp was lit”, the reaction is to be “close the eyes”. The shorter the time between “the lamp was lit” and “close the eyes”, the faster the reflexes. Describe a method to determine the speed of a person’s reflexes, without using a chronometer or any other equipment allowing the measurement of time intervals shorter than 1 second. It is possible to devise a rough method on a US$ 1 budget for equipment, and a sophisticated method with good precision having US$ 1,000 at one’s disposal. Describe a method for both budgets.
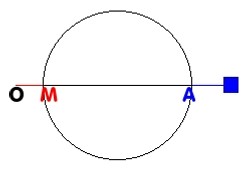
- In 1993, in an essay about Science and Religion, I described a project regarding the possibility to build an “invisibility machine”. On describing the details, I realized that some problems were insolvable, not only because of technological limitations but also for physical reasons imposing theoretical and possibly insurmountable limits. The project starts from the central idea that in order to make an object invisible, it is necessary for an external observer looking in its direction to visually stop noticing its presence. This can be done in the following way: A sphere is constructed, and its whole external surface is covered with minute, high-resolution TV cameras and monitors. Millions or even billions of cameras and monitors are to cover the whole sphere in such a way that each monitor transmits the image captured by a camera located in the point diametrically opposite to that monitor. The result will be as shown in the figure below. The image of the object (blue square) is captured by a camera located in point A, which transmits the image to a monitor in point M. As a result, an observer in point O will see the blue square as if there were nothing in front of him. In that way, everything inside the sphere will be invisible to the external observer. But this scheme presents two problems. One of them can be solved in theory while the other one is insolvable. Indicate those two problems and explain why one of them can be solved but the other one cannot.
- Many Mensa members have approved by the Raven’s test (Standard or Advanced). Assuming all Mensa members had approved by the Raven Standard Progressive Matrices and assuming the norm indicated below is correct and accurate, what percentage of Mensa members were approved without actually having an IQ above 132? Disregard cases of fraud (people who knew the answers before taking the test). The uncertainty in the score for each person examined is 2.6 points in raw score. (EXT 2022)

- Following the previous statement, what percentage of people were not approved by the RSPM, but whose IQ is above 132? (EXT 2022)
- In a 256-dimensional Euclidean orthonormal hyperspace, we have a 6-dimensional hypersphere and we want to split it into as many pieces as possible, but we can only make 12 cuts. Pieces cannot change position. Each slice is a 5-dimensional Euclidean orthogonal hyperspace (hyperplane). How many pieces can we get this way? (Sigma Test VI 2003)
Level VIII (184)
- The porous and gray “lead” inside a pencil consists of a mixture of graphite and clay. The ratio of graphite to clay is not known. On writing on a sheet of paper, a fine layer of “lead” remains on the surface of the sheet. Describe a method for calculating the mass of “lead” in the dot of the letter “i”. You may use only US$10 to buy the material needed for the experiment.
- We have a cylinder with a radius of 50 cm and a tape measure 0.01 cm thick. The height of the cylinder equals the width of the tape measure. The thickness of the tape measure is invariable and one of its wider sides is inextensible. What is the minimum length of tape necessary to wind it around the cylinder 9 times, all rounds overlapping, as in a roll of scotch tape. The top and base of the cylinder may not be covered with tape. The solution must be given with 14 significant digits and it is not allowed to cut the tape or cut or deform de cylinder.
- A sophisticated aircraft is hovering like a hummingbird over a terrain located on the equatorial line of a planet, at an altitude of 1,000 m. The planet is completely spherical and homogeneous, and has a small satellite on a circular orbit on a plane parallel to its equator. At 15:58:30h a man parachutes down from the aircraft, descending perpendicularly to the ground. At the moment that he jumps off the aircraft, he notices a satellite starting to rise on the eastern horizon. He lands and, without leaving the landing site, continues to observe the satellite, which at 17:40:00 h reaches the zenith. He remains in the same place, observing…and at 19:20:00h sees the satellite disappear on the western horizon. Still in the same place, at 22:40:00h, he sees the satellite rising again in the east. What is the approximate diameter of that planet? Explain how you arrived at your answer and the usefulness of all the pieces of information given. Explain also why the result cannot be exact. (If you have doubts as to the meaning of zenith, horizon, equator, orbit etc., you may consult dictionaries or encyclopedias).
- We have a regular, rigid and massy tetrahedron (T1) with edge 1, and we want to make a cut through which another rigid, massy tetrahedron (T2) can pass, completely crossing this hole and coming out completely on the other side. What is the maximum edge that the T2 tetrahedron can have? The answer must be presented with 50 digits. (EXT 2022)
- We have a rigid, massy cube with edge 1, and we want to make a cut through which a regular, rigid and massy tetrahedron can pass, completely crossing this hole and coming out completely on the other side. What is the maximum edge that this tetrahedron can have? The answer must be presented with 50 digits. (EXT 2022)
Level IX (202)
- Describe a practical and fast method that can be used with good precision to determine the number of words in a person’s vocabulary.
- If Jupiter were hollow and the top of its clouds were a rigid membrane 1 mm thick, how many planets like Earth would fit entirely inside it? (Moon test)
- Estimate or calculate realistic percentiles for the raw scores of the following tests: Mega Test, Titan Test. Feel free to justify with formulas and arguments, if you want, trying to be as concise and objective as possible. (EXT 2022)
- Estimate or calculate realistic percentiles for the raw scores of 2 high range IQ tests of your choice. Feel free to justify with formulas and arguments, if you want, trying to be as concise and objective as possible. (EXT 2022)
- Estimate or calculate realistic percentiles for the cut-offs for the following high-IQ societies: 1. Mensa
2. Intertel
3. Colloquy
4. Cerebrals
5. ISPE
6. Prometheus
7. Epimetheus
8. HellIQ
9. Mega Society
10. Omega Society
11. Pi Society
12. Pars Society
13. OlympIQ Society
14. Sigma V
15. Giga Society
16. Sigma VI
17. Choose another 2 societies with theoretical percentile 1-10^-9 or higher. (EXT 2022) - There was a brilliant anthropologist, a member of Sigma V, named John. During an expedition to Africa, he was imprisoned by a tribe of cannibals and sentenced to serve as a meal. But the “legislation” of this tribe offered prisoners an opportunity to be released if they were able to overcome a challenge. In João’s case, the challenge consisted of the following: two eggs would be presented to him, one raw and the other boiled. Each egg would remain inside a box. The walls of these boxes are rigid and opaque. The boxes are shaped like cobblestones. One of the boxes has a window on one of its sides, and this window is covered with a wire mesh, through which it is possible to see the egg that is inside it. The challenge is to identify which is the raw egg within 2 minutes. Eggs cannot be broken, they cannot be taken out of the boxes, the boxes cannot be opened and it is not allowed to insert anything inside the boxes. João is informed that this challenge will be presented to him within 90 days. Until that time expires, he can count on the support of the villagers to investigate a way to solve the problem. In addition, João can have all the “sophisticated” instruments and everything else available in the village and surroundings. When the date to face the challenge arrived, at sunrise, João had his eyes blindfolded and his hands tied. A few minutes later, a village elder boiled an egg, dried it, placed it in a box and closed it. He took a raw egg and put it in another box, then closed it. The two boxes were placed on a table, where they remained until nightfall. Then John was untied and the blindfolds were removed from his eyes, he was provided with the requisite equipment and was placed in front of the table where the boxes with the eggs were. He examined them carefully and was able to identify where the raw egg was. The challenge was repeated for 20 consecutive days, always with different eggs, and in the 20 times he managed to make the correct identification. In view of this, the cannibals, admired, recognized the value of the remarkable anthropologist. They decided to release him and even presented him with many jewels. Describe a procedure that John may have used to be able to identify which box had the raw egg.

- The two photos below were taken in August 2020, by Hindemburg Melao Jr. at coordinates -22.947594, -45.476772 and by Alisson Correa Chervinski at coordinates -29.755334, -57.076461. What was the distance from the center of the Earth to the center of the Moon at that moment? Justify your answer in detail. (visit the Moon Test page to download higher resolution images) (Moon test)
Level X – EXTRA (221) (at least 80% of the previous questions must be correct for your answers at level X to be analyzed)
- An Arab man and an Israeli woman are abducted by extraterrestrials. The E.T.s promise to return them to Earth unharmed, provided that they succeed in the following task: three rooms are designated A, B and C. Each room is square and measures approximately 25 m2. The rooms are connected in such a way that each room has two doors, and each door provides access to one of the other two rooms. The three rooms are acustically isolated and have no furniture or windows. The walls, doors, ceiling and floor of the rooms are solid and opaque, and contain no cracks, holes, hidden passages or the like. The man is placed in room A and the woman in room B. They both receive the following instructions:
1. They both have 1 hour to traverse the three rooms and return to the room where they started, always walking in the direction A – B – C – A.
2. The both have to remain seated, on the floor, in their respective rooms, until a signal would be emitted, indicating that the time count had started. The signal was as follows: on each door there are two lamps (one on each side of the door), and the nearly simultaneous lighting of the all the lamps constitutes the signal. Each lamp is bright enough for a person to notice easily even when he is not paying attention to it.
3. The moment that the woman touches the doorknob of a room, the man cannot be in that room any more.
4. The moment that the man touches the doorknob of a room, the woman cannot be in that room any more.
5. The woman has to get up from the floor after the man.
6. The man and woman are not permitted to communicate between each other in any way, or obtain from others any information allowing them to figure out where the other one is. They may not beat the walls or the doors, or try to generate any kind of shock wave. On leaving a room and entering another one, it is required to close the corresponding door. Initially all the doors are closed. Two or more doors may not be open at the same time.
7. None of them has a clock or any other instrument that can be used to measure time.
8. 1 minute before the 1 hour period is up the light signal will be given again, indicating that the time is running out.
9. When the 1 hour period is up the man has to be sitting in the center of room A and the woman in the center of room B.
10. The woman may only sit down after the man.
11. The man is told that the woman is exceptionally intelligent.
12. The woman is told that the man is exceptionally intelligent.
The man and the woman did not know each other and had never been in any contact with each other before. They did not communicate with each other during the whole process (to clarify the matter, it can be told that they both were mute and deaf). The experiment is carried out and they manage to perform the task. The experiment is repeated 10 times and each time they complete the task successfully, making it clear that the first time was not due to mere good luck. Afterwards they are returned to Earth where they convert to Zoroastrianism, get married and live happily everafter! Describe the method they used and the way of thinking of both of them.
- Consider that the level of intellectual production of a company is measured by the sum of the productions of its employees and executives working together. Consider a company with 10,000 employees, which selects them through a reliable, accurate, efficient, and well-normed cognitive test with a cutoff of 2 standard deviations above the mean. The total intellectual output of the employees of this company is equivalent to that of a person with IQ = x working alone. Determine the x. Of course, the employees will produce in larger quantity than the person with IQ = x, but if you weigh the intellectual relevance of each work/creation, the fewer number of more relevant work/creation by the person with IQ = x will be equivalent to the largest number of less relevant work/creation out of 10,000 employees together. (EXT 2022)
- As the previous statement, now consider that the total number of people ever born is about 100 billion and assume that the average IQ of the historical population is 100 with a standard deviation 16. If an alien had the same intellectual production capacity as all people who have lived together, what would be this alien’s IQ? (EXT 2022)
- The photo below shows the Clavius crater. Christopher Clavius was a mathematician, astronomer and priest contemporary of Galileo. Clavius was distinguished for his works in Geometry and Algebra. When Galileo showed that the Moon had a rugged topography, rather than being a perfect sphere, as had been believed until then, Clavius argued that if the Moon’s surface were indeed irregular, as Galileo said, then the Moon’s edges must also show this characteristic, but even with telescopes (at the time) the edges of the Moon are very sleek. Faced with this empirical evidence, Clavius proposed that the Moon probably had a perfectly spherical transparent surface beneath which these apparent irregularities were. According science historian R.A.M., Galileo not found appropriate arguments to refute Clavius’ thesis, however there were sufficient resources at the time to show that Clavius was wrong. Point out problems with Clavius’ argument and show that Galileo’s thesis was most likely to be a better representation of sentient reality. (Moon test)

- What is the total number of different positions that can be produced in all possible chess games. Justify your answer in detail. (EXT 2022)
- What is the logarithm (base 10) of the total number of different positions that can be produced in all possible matches of MegaChess, 16×16 version of Chess on the Zillions of Games platform. Justify your answer in detail. (EXT 2022)

Sigma Test Extended ‘s first norm estimate
Current STE (and ST) highest score holder: Petri Widsten, 212. Petri is a Ph.D. Summa Cum Laude in Chemistry, his doctoral thesis was considered the best in Finland in the 2002-2003 biennium, he was also placed first in important international competitions of Logic, Intelligence and Puzzles, including the WORLD IQ CHALLENGE.



Standard based on the combined results of Sigma Test, Sigma Test VI and Moon Test.
Theoretical Percentile: percentile used in all high-IQ societies, based on the assumption that scores are normally distributed across the entire scale. As the actual distribution has dense trails on the right and becomes progressively denser for higher IQs, the percentiles are inflated and incorrect. But as it is the standard used, the table also includes this information for comparison purposes.
True Percentile: Realistic percentile calculated based on the method described in this article https://www.sigmasociety.net/escalasqi, scaling the scores in proportion and determining the true cumulative frequencies.
FEES:
Fee: US $ 100 until 5/31/2022 or up to the first 1,000 people screened
Fee: US $ 316 between 6/1/2022 and 7/31/2022 or up to the first 2,000 people screened
Fee: US $ 1,000 between 8/1/2022 and 9/30/2022 or up to the first 4,000 people screened
Fee: US $ 3,162 between 10/1/2022 and 11/30/2022 or up to the first 8,000 people screened
Fee: US $ 10,000 as of 12/1/2022 or from 16,000 people screened
CUMULATIVE DISCOUNTS:
Anyone who takes the Sigma Test Extended while fewer than 100 people are tested can apply for a new certificate after more than 100 people are tested, with the revised standard.
Persons who were already tested with Sigma Test before 2007 and did not receive a printed certificate: exempt from the fee
People who were already tested with the Sigma Test before 2007 and received a printed certificate: 30% discount on the fee
People who have already been tested with Sigma Test VI: 20% off fee
People who have already been screened with the Moon Test: 10% off fee
The above discounts are cumulative. For example: the person took the Sigma Test and the Sigma Test VI, so your rate will be 0.7 × 0.8 = 0.56 (44% discount).After took the Sigma Test Extended, the person receives a certificate from the Sigma Test Extended and a certificate based exclusively on the Sigma Test questions, since the ST is a subtest of STE. Although question 36 of the STE was not included, as there was no correct answer in this question, it does not interfere with the norm.
Footnotes
[1] Hindemburg Melão Jr. is the author of solutions to scientific and mathematical problems that have remained unsolved for decades or centuries, including improvements on works by 5 Nobel laureates, holder of a world record in longest announced checkmate in blindfold simultaneous chess games, registered in the Guinness Book 1998, author of the Sigma Test Extended and founder of some high IQ societies.
[2] Individual Publication Date: July 22, 2022: http://www.in-sightpublishing.com/ste; Full Issue Publication Date: September 1, 2022: https://in-sightjournal.com/insight-issues/.
Citations
American Medical Association (AMA): Melão H. Sigma Test Extended[Online]. July 2022; 30(B). Available from: http://www.in-sightpublishing.com/ste.
American Psychological Association (APA, 6th Edition, 2010): Hindemburg, M. (2022, July 22). Sigma Test Extended. Retrieved from http://www.in-sightpublishing.com/ste.
Brazilian National Standards (ABNT): HINDEMBURG, M. Sigma Test Extended. In-Sight: Independent Interview-Based Journal. 30.B, July. 2022. <http://www.in-sightpublishing.com/ste>.
Chicago/Turabian, Author-Date (16th Edition): Hindemburg, Melão. 2022. Sigma Test Extended.” In-Sight: Independent Interview-Based Journal. 30.B. http://www.in-sightpublishing.com/ste.
Chicago/Turabian, Humanities (16th Edition): Hindemburg, Melão “Sigma Test Extended.” In-Sight: Independent Interview-Based Journal. 30.B (July 2022). http://www.in-sightpublishing.com/ste.
Harvard: Hindemburg, M. 2022, ‘Sigma Test Extended’, In-Sight: Independent Interview-Based Journal, vol. 30.B. Available from: <http://www.in-sightpublishing.com/ste>.
Harvard, Australian: Hindemburg, M. 2022, ‘Sigma Test Extended’, In-Sight: Independent Interview-Based Journal, vol. 30.B., http://www.in-sightpublishing.com/ste.
Modern Language Association (MLA, 7th Edition, 2009): Melão Hindemburg. “Sigma Test Extended.” In-Sight: Independent Interview-Based Journal 30.A(2022): July. 2022. Web. <http://www.in-sightpublishing.com/ste>.
Vancouver/ICMJE: Hindemburg M. Sigma Test Extended[Internet]. (2022, July 30(B). Available from: http://www.in-sightpublishing.com/ste.
License
In-Sight Publishing by Scott Douglas Jacobsen is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.
Based on a work at www.in-sightpublishing.com.
Copyright
© Hindemburg Melao Jr. and In-Sight Publishing 2012-Present. Unauthorized use and/or duplication of this material without express and written permission from this site’s author and/or owner is strictly prohibited. Excerpts and links may be used, provided that full and clear credit is given to Hindemburg Melao Jr., and In-Sight Publishing and In-Sight: Independent Interview-Based Journal with appropriate and specific direction to the original content. All interviewees and authors co-copyright their material and may disseminate for their independent purposes.

